@@ -50,7 +50,7 @@
[](https://github.com/LC044/WeChatMsg)
[](https://gitee.com/lc044/WeChatMsg)
[](https://memotrace.cn/)
-- 🔒️🔑🔓️Windows本地微信数据库
+- 🔒️🔑🔓️Windows本地微信数据库(支持微信4.0)
- 还原微信聊天界面
- 🗨文本✅
- 🏝图片✅
@@ -88,11 +88,11 @@
[https://github.com/LC044/AnnualReport](https://github.com/LC044/AnnualReport)
-## 2.2更新预告
+## 3.0 全面来袭
### 全面适配微信4.0
-
+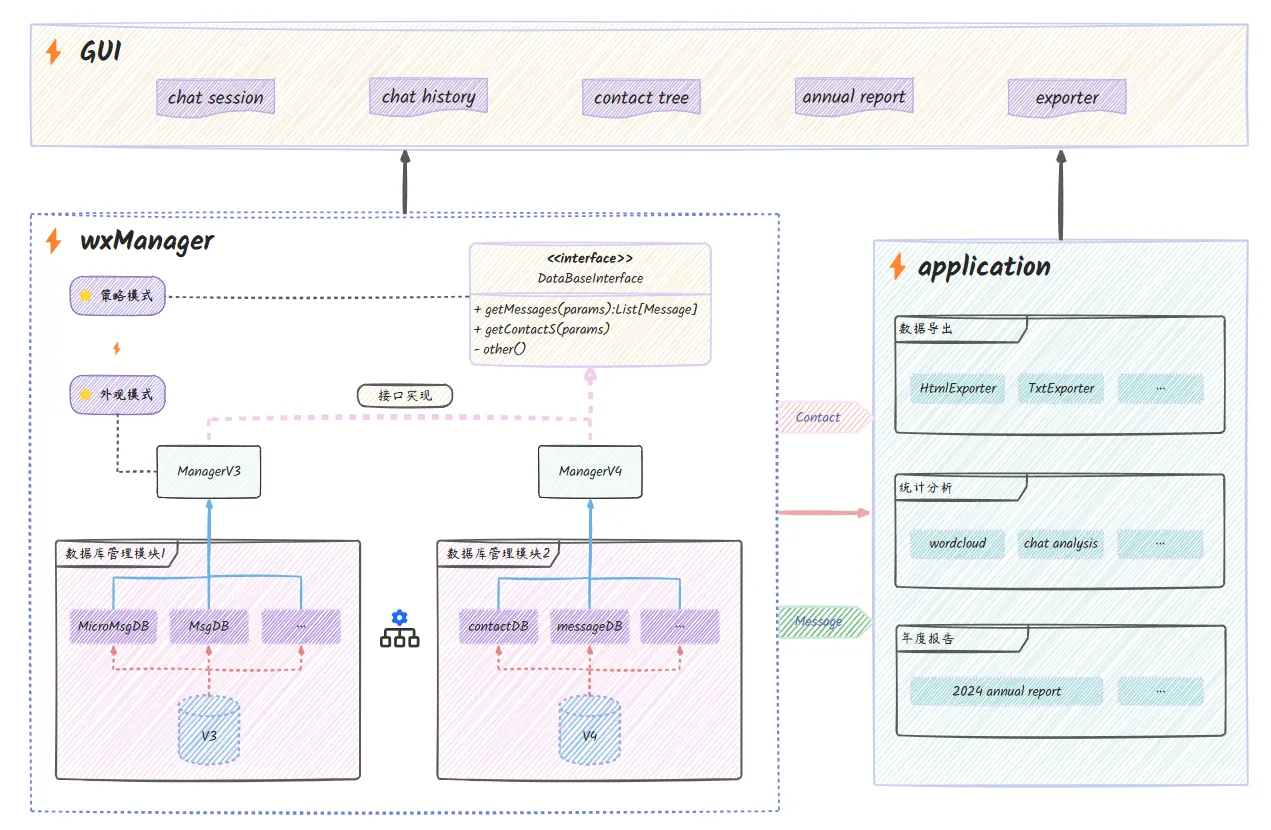
* 全新框架、重构底层逻辑
* 更低的内存占用
@@ -109,33 +109,6 @@
- 如果跟其他模块兼容的话,将采用MIT许可证
- 已有功能代码全开源
-## 🥤效果
-
-
-
- -
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
# ⌛使用
@@ -230,7 +203,6 @@
后续更新将会在公众号同步发布

-

## AI交流
@@ -243,6 +215,6 @@
# License
-WeChatMsg is licensed under [GPLv3](./LICENSE).
+WeChatMsg is licensed under [MIT](./LICENSE).
Copyright © 2022-2024 by SiYuan.
diff --git a/requirements.txt b/requirements.txt
index 2a8ccd7..b0567a6 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -1,20 +1,22 @@
-PyQt5
-psutil
-pycryptodomex
-pywin32
-pymem
-silk-python
-pyaudio
-fuzzywuzzy
-python-Levenshtein
-requests
-flask==3.0.0
-pyecharts==2.0.1
-jieba==0.42.1
+pywin32==308
+psutil~=6.1.1
+yara-python
+pymem==1.14.0
+zstandard~=0.23.0
+pillow==11.0.0
google==3.0.0
protobuf==4.25.1
soupsieve==2.5
-lz4==4.3.2
-pilk==0.2.4
-python-docx==1.1.0
-docxcompose==1.4.0
\ No newline at end of file
+lz4~=4.3.3
+requests~=2.32.3
+xmltodict~=0.14.2
+Crypto~=1.4.1
+pycryptodome
+cryptography
+openpyxl==3.1.5
+aiofiles~=24.1.0
+dateparser~=1.2.1
+beautifulsoup4~=4.12.3
+lxml~=5.3.1
+typing_extensions~=4.12.2
+pysilk-mod==1.6.4
\ No newline at end of file
diff --git a/wxManager/__init__.py b/wxManager/__init__.py
new file mode 100644
index 0000000..8d7fac5
--- /dev/null
+++ b/wxManager/__init__.py
@@ -0,0 +1,42 @@
+# -*- coding: utf-8 -*-
+"""
+@File : __init__.py.py
+@Author : Shuaikang Zhou
+@Time : 2023/1/5 0:10
+@IDE : Pycharm
+@Version : Python3.10
+@comment : ···
+"""
+from .model import Me, MessageType, Message, Person, Contact, TextMessage, ImageMessage
+from .db_main import DataBaseInterface
+from .manager_v4 import DataBaseV4
+from .manager_v3 import DataBaseV3
+
+__version__ = '3.0.0'
+
+
+class DatabaseConnection:
+ def __init__(self, db_dir, db_version=4):
+ self.db_dir = db_dir
+ self.db_version = db_version
+ self.database_interface = self._initialize_database()
+
+ def _initialize_database(self) -> DataBaseInterface:
+ if self.db_version == 4:
+ database0 = DataBaseV4()
+ else:
+ database0 = DataBaseV3()
+ if database0.init_database(self.db_dir):
+ return database0
+ else:
+ return None
+
+ def get_interface(self) -> DataBaseInterface:
+ return self._initialize_database()
+
+
+"""
+使用示例:
+conn = DatabaseConnection(USER_DB_DIR, 4)
+database: DataBaseInterface = conn.get_interface()
+"""
diff --git a/wxManager/db_main.py b/wxManager/db_main.py
new file mode 100644
index 0000000..21bad35
--- /dev/null
+++ b/wxManager/db_main.py
@@ -0,0 +1,254 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2024/12/11 1:22
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-db_main.py
+@Description :
+"""
+
+from abc import ABC, abstractmethod
+
+import os
+from datetime import date
+from typing import List, Any, Tuple
+
+from wxManager import MessageType
+from wxManager.model.contact import Contact
+
+
+class DataBaseInterface(ABC):
+ def __init__(self):
+ self.chatroom_members_map = {}
+ self.contacts_map = {}
+
+ def init_database(self, db_dir=''):
+ raise ValueError("子类必须实现该方法")
+
+ def close(self):
+ raise ValueError("子类必须实现该方法")
+
+ def get_session(self):
+ """
+ 获取聊天会话窗口,在聊天界面显示
+ @return:
+ """
+ raise ValueError("子类必须实现该方法")
+
+ def get_messages(
+ self,
+ username_: str,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None,
+ ):
+ raise ValueError("子类必须实现该方法")
+
+ def get_messages_by_num(self, username, start_sort_seq, msg_num=20):
+ """
+ 获取小于start_sort_seq的msg_num个消息
+ @param username:
+ @param start_sort_seq:
+ @param msg_num:
+ @return: messages, 最后一条消息的start_sort_seq
+ """
+ raise ValueError("子类必须实现该方法")
+
+ def get_message_by_server_id(self, username, server_id):
+ """
+ 获取小于start_sort_seq的msg_num个消息
+ @param username:
+ @param server_id:
+ @return: messages, 最后一条消息的start_sort_seq
+ """
+ raise ValueError("子类必须实现该方法")
+
+ def get_messages_group_by_day(
+ self,
+ username_: str,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None,
+
+ ) -> dict:
+ raise ValueError("子类必须实现该方法")
+
+ def get_messages_all(self, time_range=None):
+ raise ValueError("子类必须实现该方法")
+
+ def get_message_by_num(self, username_, local_id):
+ raise ValueError("子类必须实现该方法")
+
+ def get_messages_by_type(
+ self,
+ username_,
+ type_: MessageType,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None,
+ ):
+ raise ValueError("子类必须实现该方法")
+
+ def get_messages_by_keyword(self, username_, keyword, num=5, max_len=10, time_range=None, year_='all'):
+ raise ValueError("子类必须实现该方法")
+
+ def get_messages_calendar(self, username_):
+ raise ValueError("子类必须实现该方法")
+
+ def get_messages_by_days(
+ self,
+ username_,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None,
+ ):
+ raise ValueError("子类必须实现该方法")
+
+ def get_messages_by_month(
+ self,
+ username_,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None,
+ ):
+ raise ValueError("子类必须实现该方法")
+
+ def get_messages_by_hour(self, username_, time_range=None, year_='all'):
+ raise ValueError("子类必须实现该方法")
+
+ def get_first_time_of_message(self, username_=''):
+ raise ValueError("子类必须实现该方法")
+
+ def get_latest_time_of_message(self, username_='', time_range=None, year_='all'):
+ raise ValueError("子类必须实现该方法")
+
+ def get_messages_number(
+ self,
+ username_,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None,
+ ) -> int:
+ raise ValueError("子类必须实现该方法")
+
+ def get_chatted_top_contacts(
+ self,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None,
+ contain_chatroom=False,
+ top_n=10
+ ) -> list:
+ raise ValueError("子类必须实现该方法")
+
+ def get_send_messages_number_sum(
+ self,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None,
+ ) -> int:
+ raise ValueError("子类必须实现该方法")
+
+ def get_send_messages_number_by_hour(
+ self,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None,
+ ) -> list:
+ raise ValueError("子类必须实现该方法")
+
+ def get_message_length(
+ self,
+ username_='',
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None,
+ ) -> int:
+ raise ValueError("子类必须实现该方法")
+
+ def get_emoji_url(self, md5: str, thumb: bool) -> str | bytes:
+ raise ValueError("子类必须实现该方法")
+
+ def get_emoji_URL(self, md5: str, thumb: bool):
+ raise ValueError("子类必须实现该方法")
+
+ def get_emoji_path(self, md5: str, output_path, thumb: bool = False, ) -> str:
+ """
+
+ @param md5:
+ @param output_path:
+ @param thumb:
+ @return:
+ """
+ raise ValueError("子类必须实现该方法")
+
+ # 图片、视频、文件
+ def get_file(self, md5: bytes | str) -> str:
+ raise ValueError("子类必须实现该方法")
+
+ def get_image(self, content, bytesExtra, up_dir="", md5=None, thumb=False, talker_username='') -> str:
+ raise ValueError("子类必须实现该方法")
+
+ def get_video(self, content, bytesExtra, md5=None, thumb=False):
+ raise ValueError("子类必须实现该方法")
+
+ # 图片、视频、文件结束
+
+ # 语音
+ def get_audio(self, reserved0, output_path, open_im=False, filename=''):
+ raise ValueError("子类必须实现该方法")
+
+ def get_media_buffer(self, server_id, is_open_im=False) -> bytes:
+ pass
+
+ def get_audio_path(self, reserved0, output_path, filename=''):
+ raise ValueError("子类必须实现该方法")
+
+ def get_audio_text(self, msgSvrId):
+ raise ValueError("子类必须实现该方法")
+
+ def add_audio_txt(self, msgSvrId, text):
+ raise ValueError("子类必须实现该方法")
+
+ def update_audio_to_text(self):
+ raise ValueError("子类必须实现该方法")
+
+ # 语音结束
+
+ def get_avatar_buffer(self, username) -> bytes:
+ raise ValueError("子类必须实现该方法")
+
+ def get_contacts(self) -> List[Contact]:
+ raise ValueError("子类必须实现该方法")
+
+ def set_remark(self, username: str, remark) -> bool:
+ raise ValueError("子类必须实现该方法")
+
+ def set_avatar_buffer(self, username, avatar_path):
+ raise ValueError("子类必须实现该方法")
+
+ def get_contact_by_username(self, wxid: str) -> Contact:
+ raise ValueError("子类必须实现该方法")
+
+ def get_chatroom_members(self, chatroom_name) -> dict[Any, Contact] | Any:
+ """
+ 获取群成员(不包括企业微信联系人)
+ @param chatroom_name:
+ @return:
+ """
+ raise ValueError("子类必须实现该方法")
+
+ # 联系人结束
+ def merge(self, db_paths):
+ """
+ 增量将db_path中的数据合入到数据库中,若存在冲突则以db_path中的数据为准
+ @param db_paths:
+ @return:
+ """
+ raise ValueError("子类必须实现该方法")
+
+ def get_favorite_items(self, time_range):
+ raise ValueError("子类必须实现该方法")
+
+
+class Context:
+ def __init__(self, interface_impl):
+ """
+ 初始化上下文,动态加载接口实现中的所有方法和属性。
+ :param interface_impl: 实现接口的具体实例
+ """
+ if not isinstance(interface_impl, DataBaseInterface):
+ raise TypeError("interface_impl 必须是 DataBaseInterface 的子类实例")
+
+ # 动态绑定实现类的方法和属性
+ for name in dir(interface_impl):
+ # 仅绑定非私有且非特殊方法
+ if not name.startswith("_"):
+ attr = getattr(interface_impl, name)
+ setattr(self, name, attr)
+
+
+if __name__ == '__main__':
+ pass
diff --git a/wxManager/db_v3/__init__.py b/wxManager/db_v3/__init__.py
new file mode 100644
index 0000000..0f184cc
--- /dev/null
+++ b/wxManager/db_v3/__init__.py
@@ -0,0 +1,13 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2024/12/4 0:06
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-__init__.py.py
+@Description :
+"""
+
+if __name__ == '__main__':
+ pass
diff --git a/wxManager/db_v3/emotion.py b/wxManager/db_v3/emotion.py
new file mode 100644
index 0000000..6d6e05f
--- /dev/null
+++ b/wxManager/db_v3/emotion.py
@@ -0,0 +1,135 @@
+import os.path
+import sqlite3
+import threading
+import traceback
+
+from wxManager.merge import increase_data
+from wxManager.model import DataBaseBase
+
+lock = threading.Lock()
+# db_path = "./app/Database/Msg/Emotion.db"
+db_path = '.'
+
+
+def singleton(cls):
+ _instance = {}
+
+ def inner():
+ if cls not in _instance:
+ _instance[cls] = cls()
+ return _instance[cls]
+
+ return inner
+
+
+# 一定要保证只有一个实例对象
+
+class Emotion(DataBaseBase):
+
+ def get_emoji_url(self, md5: str, thumb: bool) -> str | bytes:
+ """供下载用,返回可能是url可能是bytes"""
+ if thumb:
+ sql = """
+ select
+ case
+ when thumburl is NULL or thumburl = '' then cdnurl
+ else thumburl
+ end as selected_url
+ from CustomEmotion
+ where md5 = ?
+ """
+ else:
+ sql = """
+ select CDNUrl
+ from CustomEmotion
+ where md5 = ?
+ """
+ cursor = self.DB.cursor()
+ try:
+ cursor.execute(sql, [md5])
+ return cursor.fetchone()[0]
+ except:
+ md5 = md5.upper()
+ sql = f"""
+ select {"Thumb" if thumb else "Data"}
+ from EmotionItem
+ where md5 = ?
+ """
+ cursor.execute(sql, [md5])
+ res = cursor.fetchone()
+ return res[0] if res else ""
+ finally:
+ lock.release()
+
+ def get_emoji_URL(self, md5: str, thumb: bool):
+ """只管url,另外的不管"""
+ if thumb:
+ sql = """
+ select
+ case
+ when thumburl is NULL or thumburl = '' then cdnurl
+ else thumburl
+ end as selected_url
+ from CustomEmotion
+ where md5 = ?
+ """
+ else:
+ sql = """
+ select CDNUrl
+ from CustomEmotion
+ where md5 = ?
+ """
+ cursor = self.DB.cursor()
+ try:
+ cursor.execute(sql, [md5])
+ return cursor.fetchone()[0]
+ except:
+ return ""
+
+ def get_emoji_desc(self, md5: str):
+ sql = '''
+ select Des
+ from EmotionDes1
+ where MD5=? or MD5=?
+ '''
+ cursor = self.DB.cursor()
+ try:
+ cursor.execute(sql, [md5, md5.upper()])
+ result = cursor.fetchone()
+ if result:
+ return result[0][6:].decode('utf-8')
+ return ""
+ except:
+ return ""
+
+ def get_emoji_data(self, md5: str, thumb=False):
+ sql = f'''
+ select {'Thumb' if thumb else 'Data'}
+ from EmotionItem
+ where MD5=? or MD5=?
+ '''
+ cursor = self.DB.cursor()
+ try:
+ cursor.execute(sql, [md5, md5.upper()])
+ result = cursor.fetchone()
+ if result:
+ return result[0]
+ return b""
+ except:
+ return b""
+
+ def merge(self, db_path):
+ if not (os.path.exists(db_path) or os.path.isfile(db_path)):
+ print(f'{db_path} 不存在')
+ return
+ try:
+ cursor = self.DB.cursor()
+ # 获取列名
+ increase_data(db_path, cursor, self.DB, 'CustomEmotion', 'MD5', 0)
+ increase_data(db_path, cursor, self.DB, 'EmotionDes1', 'MD5', 1, True)
+ increase_data(db_path, cursor, self.DB, 'EmotionItem', 'MD5', 1, True)
+ increase_data(db_path, cursor, self.DB, 'EmotionPackageItem', 'ProductId', 0, False)
+ increase_data(db_path, cursor, self.DB, 'EmotionOrderInfo', 'MD5', 0, False)
+ except:
+ print(f"数据库操作错误: {traceback.format_exc()}")
+ self.DB.rollback()
diff --git a/wxManager/db_v3/favorite.py b/wxManager/db_v3/favorite.py
new file mode 100644
index 0000000..b93c179
--- /dev/null
+++ b/wxManager/db_v3/favorite.py
@@ -0,0 +1,37 @@
+import os.path
+import sqlite3
+import threading
+from datetime import date
+from typing import Tuple
+
+from wxManager.db_v3.msg import convert_to_timestamp
+
+lock = threading.Lock()
+DB = None
+cursor = None
+db_path = '.'
+
+
+class Favorite:
+
+ def get_items(self, time_range: Tuple[int | float | str | date, int | float | str | date] = None, ):
+ if time_range:
+ start_time, end_time = convert_to_timestamp(time_range)
+ sql = f'''
+ select FavLocalID, Type, FromUser, RealChatName, SearchKey, UpdateTime, XmlBuf
+ from FavItems
+ where StrTalker=?
+ {'AND UpdateTime>' + str(start_time) + ' AND UpdateTime<' + str(end_time) if time_range else ''}
+ order by UpdateTime
+ '''
+ res = []
+ try:
+ lock.acquire(True)
+ self.cursor.execute(sql)
+ res = self.cursor.fechall()
+ self.DB.commit()
+ except:
+ res = []
+ finally:
+ lock.release()
+ return res if res else []
diff --git a/wxManager/db_v3/hard_link_file.py b/wxManager/db_v3/hard_link_file.py
new file mode 100644
index 0000000..6e471dd
--- /dev/null
+++ b/wxManager/db_v3/hard_link_file.py
@@ -0,0 +1,89 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2025/2/4 1:38
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : wxManager-hard_link_file.py
+@Description :
+"""
+
+import binascii
+import hashlib
+import os
+import sqlite3
+import traceback
+import xml.etree.ElementTree as ET
+
+from wxManager.merge import increase_data
+from wxManager.model.db_model import DataBaseBase
+from wxManager.log import logger
+
+file_root_path = "FileStorage\\File\\"
+
+
+def get_md5_from_xml(content, type_="img"):
+ try:
+ content = content.strip('null:').strip()
+ # 解析XML
+ root = ET.fromstring(content)
+ if type_ == "img":
+ # 提取md5的值
+ md5_value = root.find(".//img").get("md5")
+ elif type_ == "video":
+ md5_value = root.find(".//videomsg").get("md5")
+ else:
+ md5_value = None
+ # print(md5_value)
+ return md5_value
+ except ET.ParseError:
+ logger.error(traceback.format_exc())
+ logger.error(content)
+ return None
+
+
+class HardLinkFile(DataBaseBase):
+ def get_file_by_md5(self, md5: bytes | str):
+ if not md5:
+ return None
+ if not self.open_flag:
+ return None
+ if isinstance(md5, str):
+ md5 = binascii.unhexlify(md5)
+ sql = """
+ select Md5Hash,MD5,FileName,HardLinkFileID2.Dir as DirName2
+ from HardLinkFileAttribute
+ join HardLinkFileID as HardLinkFileID2 on HardLinkFileAttribute.DirID2 = HardLinkFileID2.DirID
+ where MD5 = ?;
+ """
+ cursor = self.DB.cursor()
+ try:
+ cursor.execute(sql, [md5])
+ except sqlite3.OperationalError:
+ return None
+ result = cursor.fetchone()
+ return result
+
+ def get_file(self, md5: bytes | str) -> str:
+ file_path = ''
+ file_info = self.get_file_by_md5(md5)
+ if file_info:
+ file_path = os.path.join(file_root_path, file_info[3], file_info[2])
+ return file_path
+
+ def merge(self, db_path):
+ if not (os.path.exists(db_path) or os.path.isfile(db_path)):
+ print(f'{db_path} 不存在')
+ return
+ try:
+ # 获取列名
+ increase_data(db_path, self.cursor, self.DB, 'HardLinkFileAttribute', 'Md5Hash', 0)
+ increase_data(db_path, self.cursor, self.DB, 'HardLinkFileID', 'DirId', 0)
+ except:
+ print(f"数据库操作错误: {traceback.format_exc()}")
+ self.DB.rollback()
+
+
+if __name__ == '__main__':
+ pass
diff --git a/wxManager/db_v3/hard_link_image.py b/wxManager/db_v3/hard_link_image.py
new file mode 100644
index 0000000..550283c
--- /dev/null
+++ b/wxManager/db_v3/hard_link_image.py
@@ -0,0 +1,157 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2025/2/4 1:26
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : wxManager-hard_link_image.py
+@Description :
+"""
+import binascii
+import hashlib
+import os
+import traceback
+import xml.etree.ElementTree as ET
+
+from wxManager.merge import increase_data
+from wxManager.model.db_model import DataBaseBase
+from wxManager.log import logger
+from wxManager.model.message import Message
+from wxManager.parser.util.protocbuf.msg_pb2 import MessageBytesExtra
+
+image_root_path = "FileStorage\\MsgAttach\\"
+
+
+def get_md5_from_xml(content, type_="img"):
+ try:
+ if not content:
+ return None
+ content = content.strip('null:').strip()
+ # 解析XML
+ root = ET.fromstring(content)
+ if type_ == "img":
+ # 提取md5的值
+ md5_value = root.find(".//img").get("md5")
+ elif type_ == "video":
+ md5_value = root.find(".//videomsg").get("md5")
+ else:
+ md5_value = None
+ # print(md5_value)
+ return md5_value
+ except:
+ logger.error(traceback.format_exc())
+ logger.error(content)
+ return None
+
+
+class HardLinkImage(DataBaseBase):
+ def get_image_path(self):
+ pass
+
+ def get_image_by_md5(self, md5: bytes | str):
+ if not md5:
+ return None
+ if not self.open_flag:
+ return None
+ if isinstance(md5, str):
+ md5 = binascii.unhexlify(md5)
+ sql = """
+ select Md5Hash,MD5,FileName,HardLinkImageID.Dir as DirName1,HardLinkImageID2.Dir as DirName2
+ from HardLinkImageAttribute
+ join HardLinkImageID on HardLinkImageAttribute.DirID1 = HardLinkImageID.DirID
+ join HardLinkImageID as HardLinkImageID2 on HardLinkImageAttribute.DirID2 = HardLinkImageID2.DirID
+ where MD5 = ?;
+ """
+ cursor = self.DB.cursor()
+ try:
+ cursor.execute(sql, [md5])
+ except AttributeError:
+ self.init_database()
+ cursor.execute(sql, [md5])
+ result = cursor.fetchone()
+ return result
+
+ def get_image_original(self, content, bytesExtra) -> str:
+ msg_bytes = MessageBytesExtra()
+ msg_bytes.ParseFromString(bytesExtra)
+ result = ''
+ for tmp in msg_bytes.message2:
+ if tmp.field1 != 4:
+ continue
+ pathh = tmp.field2 # wxid\FileStorage\...
+ pathh = "\\".join(pathh.split("\\")[1:])
+ return pathh
+ md5 = get_md5_from_xml(content)
+ if not md5:
+ pass
+ else:
+ result = self.get_image_by_md5(binascii.unhexlify(md5))
+ if result:
+ dir1 = result[3]
+ dir2 = result[4]
+ data_image = result[2]
+ dir0 = "Image"
+ dat_image = os.path.join(image_root_path, dir1, dir0, dir2, data_image)
+ result = dat_image
+ return result
+
+ def get_image_thumb(self, content, bytesExtra) -> str:
+ msg_bytes = MessageBytesExtra()
+ msg_bytes.ParseFromString(bytesExtra)
+ result = ''
+ for tmp in msg_bytes.message2:
+ if tmp.field1 != 3:
+ continue
+ pathh = tmp.field2 # wxid\FileStorage\...
+ pathh = "\\".join(pathh.split("\\")[1:])
+ return pathh
+ md5 = get_md5_from_xml(content)
+ if not md5:
+ pass
+ else:
+ result = self.get_image_by_md5(md5)
+ if result:
+ dir1 = result[3]
+ dir2 = result[4]
+ data_image = result[2]
+ dir0 = "Thumb"
+ dat_image = os.path.join(image_root_path, dir1, dir0, dir2, data_image)
+ result = dat_image
+ return result
+
+ def get_image(self, content, bytesExtra, up_dir="", md5=None, thumb=False) -> str:
+ result = '.'
+ if md5:
+ imginfo = self.get_image_by_md5(md5)
+ if imginfo:
+ dir1 = imginfo[3]
+ dir2 = imginfo[4]
+ data_image = imginfo[2]
+ dir0 = "Thumb"
+ dat_image = os.path.join(image_root_path, dir1, dir0, dir2, data_image)
+ result = dat_image
+ else:
+ if thumb:
+ result = self.get_image_thumb(content, bytesExtra)
+ else:
+ result = self.get_image_original(content, bytesExtra)
+ if not result:
+ result = self.get_image_thumb(content, bytesExtra)
+ return result
+
+ def merge(self, db_path):
+ if not (os.path.exists(db_path) or os.path.isfile(db_path)):
+ print(f'{db_path} 不存在')
+ return
+ try:
+ # 获取列名
+ increase_data(db_path, self.cursor, self.DB, 'HardLinkImageAttribute', 'Md5Hash', 0)
+ increase_data(db_path, self.cursor, self.DB, 'HardLinkImageID', 'DirId', 0)
+ except:
+ print(f"数据库操作错误: {traceback.format_exc()}")
+ self.DB.rollback()
+
+
+if __name__ == '__main__':
+ pass
diff --git a/wxManager/db_v3/hard_link_video.py b/wxManager/db_v3/hard_link_video.py
new file mode 100644
index 0000000..fcc6e60
--- /dev/null
+++ b/wxManager/db_v3/hard_link_video.py
@@ -0,0 +1,119 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2025/2/4 1:41
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : wxManager-hard_link_video.py
+@Description :
+"""
+
+import binascii
+import hashlib
+import os
+import sqlite3
+import traceback
+import xml.etree.ElementTree as ET
+
+from wxManager.merge import increase_data
+from wxManager.model.db_model import DataBaseBase
+from wxManager.log import logger
+from wxManager.parser.util.protocbuf.msg_pb2 import MessageBytesExtra
+
+video_root_path = "FileStorage\\Video\\"
+
+
+def get_md5_from_xml(content, type_="img"):
+ try:
+ content = content.strip('null:').strip()
+ # 解析XML
+ root = ET.fromstring(content)
+ if type_ == "img":
+ # 提取md5的值
+ md5_value = root.find(".//img").get("md5")
+ elif type_ == "video":
+ md5_value = root.find(".//videomsg").get("md5")
+ else:
+ md5_value = None
+ # print(md5_value)
+ return md5_value
+ except ET.ParseError:
+ logger.error(traceback.format_exc())
+ logger.error(content)
+ return None
+
+
+class HardLinkVideo(DataBaseBase):
+ def get_video_by_md5(self, md5: bytes | str):
+ if not md5:
+ return None
+ if not self.open_flag:
+ return None
+ if isinstance(md5, str):
+ md5 = binascii.unhexlify(md5)
+ sql = """
+ select Md5Hash,MD5,FileName,HardLinkVideoID2.Dir as DirName2
+ from HardLinkVideoAttribute
+ join HardLinkVideoID as HardLinkVideoID2 on HardLinkVideoAttribute.DirID2 = HardLinkVideoID2.DirID
+ where MD5 = ?;
+ """
+ cursor = self.DB.cursor()
+ try:
+ cursor.execute(sql, [md5])
+ except sqlite3.OperationalError:
+ return None
+ result = cursor.fetchone()
+ return result
+
+ def get_video(self, content, bytesExtra, md5=None, thumb=False):
+ if md5:
+ result = self.get_video_by_md5(binascii.unhexlify(md5))
+ if result:
+ dir2 = result[3]
+ data_image = result[2].split(".")[0] + ".jpg" if thumb else result[2]
+ # dir0 = 'Thumb' if thumb else 'Image'
+ dat_image = os.path.join(video_root_path, dir2, data_image)
+ return dat_image
+ else:
+ return ''
+ else:
+ if bytesExtra:
+ msg_bytes = MessageBytesExtra()
+ msg_bytes.ParseFromString(bytesExtra)
+ for tmp in msg_bytes.message2:
+ if tmp.field1 != (3 if thumb else 4):
+ continue
+ pathh = tmp.field2 # wxid\FileStorage\...
+ pathh = "\\".join(pathh.split("\\")[1:])
+ return pathh
+ md5 = get_md5_from_xml(content, type_="video")
+ if not md5:
+ return ''
+ result = self.get_video_by_md5(binascii.unhexlify(md5))
+ if result:
+ dir2 = result[3]
+ data_image = result[2].split(".")[0] + ".jpg" if thumb else result[2]
+ # dir0 = 'Thumb' if thumb else 'Image'
+ dat_image = os.path.join(video_root_path, dir2, data_image)
+ return dat_image
+ else:
+ return ''
+ else:
+ return ''
+
+ def merge(self, db_path):
+ if not (os.path.exists(db_path) or os.path.isfile(db_path)):
+ print(f'{db_path} 不存在')
+ return
+ try:
+ # 获取列名
+ increase_data(db_path, self.cursor, self.DB, 'HardLinkVideoAttribute', 'Md5Hash', 0)
+ increase_data(db_path, self.cursor, self.DB, 'HardLinkVideoID', 'DirId', 0)
+ except:
+ print(f"数据库操作错误: {traceback.format_exc()}")
+ self.DB.rollback()
+
+
+if __name__ == '__main__':
+ pass
diff --git a/wxManager/db_v3/media_msg.py b/wxManager/db_v3/media_msg.py
new file mode 100644
index 0000000..36ba59b
--- /dev/null
+++ b/wxManager/db_v3/media_msg.py
@@ -0,0 +1,281 @@
+import os.path
+import shutil
+import subprocess
+import sys
+import traceback
+import sqlite3
+import base64
+
+import xml.etree.ElementTree as ET
+
+from wxManager.merge import increase_data
+from wxManager.log import logger
+from wxManager.model import DataBaseBase
+
+
+def get_ffmpeg_path():
+ # 获取打包后的资源目录
+ resource_dir = getattr(sys, '_MEIPASS', os.path.abspath(os.path.dirname(__file__)))
+
+ # 构建 FFmpeg 可执行文件的路径
+ ffmpeg_path = os.path.join(resource_dir, 'app', 'resources', 'data', 'ffmpeg.exe')
+
+ return ffmpeg_path
+
+
+class MediaMsg(DataBaseBase):
+ voice_visited = {}
+
+ def get_media_buffer(self, reserved0):
+ sql = '''
+ select Buf
+ from Media
+ where Reserved0 = ?
+ '''
+ for db in self.DB:
+ cursor = db.cursor()
+ cursor.execute(sql, [reserved0])
+ result = cursor.fetchone()
+ if result:
+ return result[0]
+ return None
+
+ def get_audio(self, reserved0, output_path, filename=''):
+ if not filename:
+ filename = reserved0
+ silk_path = f"{output_path}/{filename}.silk"
+ pcm_path = f"{output_path}/{filename}.pcm"
+ mp3_path = f"{output_path}/{filename}.mp3"
+ if os.path.exists(mp3_path):
+ return mp3_path
+ buf = self.get_media_buffer(reserved0)
+ if not buf:
+ return ''
+ with open(silk_path, "wb") as f:
+ f.write(buf)
+ # open(silk_path, "wb").write()
+ try:
+ decode(silk_path, pcm_path, 44100)
+ # 调用系统上的 ffmpeg 可执行文件
+ # 获取 FFmpeg 可执行文件的路径
+ ffmpeg_path = get_ffmpeg_path()
+ # # 调用 FFmpeg
+ if os.path.exists(ffmpeg_path):
+ cmd = f'''"{ffmpeg_path}" -loglevel quiet -y -f s16le -i "{pcm_path}" -ar 44100 -ac 1 "{mp3_path}"'''
+ # system(cmd)
+ # 使用subprocess.run()执行命令
+ subprocess.run(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
+ else:
+ # 源码运行的时候下面的有效
+ # 这里不知道怎么捕捉异常
+ cmd = f'''"{os.path.join(os.getcwd(), 'app', 'resources', 'data', 'ffmpeg.exe')}" -loglevel quiet -y -f s16le -i "{pcm_path}" -ar 44100 -ac 1 "{mp3_path}"'''
+ # system(cmd)
+ # 使用subprocess.run()执行命令
+ subprocess.run(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
+ if os.path.exists(silk_path):
+ os.remove(silk_path)
+ if os.path.exists(pcm_path):
+ os.remove(pcm_path)
+ except Exception as e:
+ print(f"Error: {e}")
+ logger.error(f'语音发送错误\n{traceback.format_exc()}')
+ cmd = f'''"{os.path.join(os.getcwd(), 'app', 'resources', 'data', 'ffmpeg.exe')}" -loglevel quiet -y -f s16le -i "{pcm_path}" -ar 44100 -ac 1 "{mp3_path}"'''
+ # system(cmd)
+ # 使用subprocess.run()执行命令
+ subprocess.run(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
+ finally:
+ return mp3_path
+
+ def get_audio_path(self, reserved0, output_path, filename=''):
+ if not filename:
+ filename = reserved0
+ mp3_path = f"{output_path}\\{filename}.mp3"
+ mp3_path = mp3_path.replace("/", "\\")
+ return mp3_path
+
+ def get_audio_text(self, content):
+ try:
+ root = ET.fromstring(content)
+ transtext = root.find(".//voicetrans").get("transtext")
+ return transtext
+ except:
+ return ""
+
+ def audio_to_text(self, token, reserved0, output_path, open_im=False, filename=''):
+ buf = self.get_media_buffer(reserved0, open_im)
+ if not buf:
+ return ''
+ if not filename:
+ filename = reserved0
+ silk_path = f"{output_path}/{filename}.silk"
+ pcm_path = f"{output_path}/{filename}.pcm"
+ with open(silk_path, "wb") as f:
+ f.write(buf)
+ decode(silk_path, pcm_path, 16000)
+ speech_data = []
+ with open(pcm_path, 'rb') as speech_file:
+ speech_data = speech_file.read()
+ length = len(speech_data)
+ if length == 0:
+ logger.error('file %s length read 0 bytes' % pcm_path)
+ pass
+ speech = base64.b64encode(speech_data).decode('utf-8')
+ params = {'dev_pid': DEV_PID,
+ 'format': 'pcm',
+ 'rate': RATE,
+ 'token': token,
+ 'cuid': CUID,
+ 'channel': 1,
+ 'speech': speech,
+ 'len': length
+ }
+ try:
+ os.remove(silk_path)
+ os.remove(pcm_path)
+ resp = requests.post(ASR_URL, json=params)
+ if resp.status_code == 200:
+ result_dict = resp.json()
+ if result_dict['err_no'] == 0:
+ return result_dict['result']
+ else:
+ print(result_dict)
+ return ""
+ else:
+ return ""
+ except:
+ logger.error(traceback.format_exc())
+ return ""
+
+ def merge(self, db_file_name):
+ def task_(db_path, cursor, db):
+ """
+ 每个线程执行的任务,获取某个数据库实例中的查询结果。
+ """
+ increase_data(db_path, cursor, db, 'Media', 'Reserved0', 1)
+
+ tasks = []
+ for i in range(100):
+ db_path = db_file_name.replace('0', f'{i}')
+ if os.path.exists(db_path):
+ # print('初始化数据库:', db_path)
+ file_name = os.path.basename(db_path)
+ if file_name in self.db_file_name:
+ index = self.db_file_name.index(file_name)
+ db = self.DB[index]
+ cursor = db.cursor()
+ task_(db_path, cursor, db)
+ tasks.append([db_path, cursor, db])
+ else:
+ shutil.copy(db_path, os.path.join(self.db_dir, 'Multi', file_name))
+ # print(tasks)
+ # 使用线程池 (没有加快合并速度)
+ # with ThreadPoolExecutor(max_workers=len(tasks)) as executor:
+ # executor.map(lambda args: task_(*args), tasks)
+ self.commit()
+ print(len(tasks))
+
+
+class Audio2TextDB:
+ def __init__(self):
+ self.DB = None
+ self.cursor: sqlite3.Cursor = None
+ self.open_flag = False
+ self.init_database()
+
+ def init_database(self, db_dir=''):
+ if not self.open_flag:
+ if os.path.exists(audio2text_db_path):
+ self.DB = sqlite3.connect(audio2text_db_path, check_same_thread=False)
+ # '''创建游标'''
+ self.cursor = self.DB.cursor()
+ self.open_flag = True
+ if audio2text_lock.locked():
+ audio2text_lock.release()
+ else:
+ self.DB = sqlite3.connect(audio2text_db_path, check_same_thread=False)
+ # '''创建游标'''
+ self.cursor = self.DB.cursor()
+ self.open_flag = True
+ # 创建表
+ self.cursor.execute('''CREATE TABLE IF NOT EXISTS Audio2Text (
+ ID INTEGER PRIMARY KEY,
+ msgSvrId INTEGER UNIQUE,
+ Text TEXT NOT NULL
+ );''')
+ # 创建索引
+ self.cursor.execute('''CREATE INDEX IF NOT EXISTS idx_msg_id ON Audio2Text (msgSvrId);''')
+ # 提交更改
+ self.DB.commit()
+
+ def get_audio_text(self, reserved0) -> str:
+ """
+ @param reserved0: 语音id或者消息id
+ @return:
+ """
+ sql = '''
+ select text from Audio2Text
+ where msgSvrId =?;
+ '''
+ try:
+ audio2text_lock.acquire(True)
+ self.cursor.execute(sql, [reserved0])
+ result = self.cursor.fetchone()
+ if result:
+ return result[0]
+ else:
+ return ""
+ except:
+ return ""
+ finally:
+ audio2text_lock.release()
+
+ def add_text(self, msgSvrId, text) -> bool:
+ try:
+ audio2text_lock.acquire(True)
+ sql = '''INSERT INTO Audio2Text (msgSvrId, Text) VALUES (?, ?)'''
+ self.cursor.execute(sql, [msgSvrId, text])
+ self.DB.commit()
+ return True
+ except sqlite3.IntegrityError:
+ return False
+ except:
+ return False
+ finally:
+ audio2text_lock.release()
+
+ def check_msgSvrId_exists(self, msgSvrId) -> bool:
+ try:
+ audio2text_lock.acquire(True)
+ sql = '''SELECT * FROM Audio2Text WHERE msgSvrId = ?'''
+ self.cursor.execute(sql, [msgSvrId])
+ result = self.cursor.fetchone()
+ return result is not None
+ except Exception as e:
+ logger.error(f"Failed to check msgSvrId in Audio2Text: {e}")
+ return False
+ finally:
+ audio2text_lock.release()
+
+ def close(self):
+ if self.open_flag:
+ try:
+ audio2text_lock.acquire(True)
+ self.open_flag = False
+ if self.DB:
+ self.DB.close()
+ finally:
+ audio2text_lock.release()
+
+ def __del__(self):
+ self.close()
+
+
+if __name__ == '__main__':
+ db_path = './Msg/MediaMSG.db'
+ media_msg_db = MediaMsg()
+ audio2text_db = Audio2TextDB()
+ reserved = 5434219509914482591
+ # path = media_msg_db.get_audio(reserved, r"D:\gou\message\WeChatMsg")
+ is_msgSvrId_exists = audio2text_db.check_msgSvrId_exists(reserved)
+ print(is_msgSvrId_exists)
+ # print(path)
diff --git a/wxManager/db_v3/micro_msg.py b/wxManager/db_v3/micro_msg.py
new file mode 100644
index 0000000..8b507e8
--- /dev/null
+++ b/wxManager/db_v3/micro_msg.py
@@ -0,0 +1,204 @@
+import os.path
+import shutil
+import sqlite3
+import threading
+import traceback
+
+from wxManager.merge import increase_update_data
+from wxManager.log import logger
+from wxManager.model import DataBaseBase
+from wxManager.model.contact import Contact
+
+lock = threading.Lock()
+# db_path = "./app/Database/Msg/MicroMsg.db"
+db_path = '.'
+
+
+def singleton(cls):
+ _instance = {}
+
+ def inner():
+ if cls not in _instance:
+ _instance[cls] = cls()
+ return _instance[cls]
+
+ return inner
+
+
+def is_database_exist():
+ return os.path.exists(db_path)
+
+
+class MicroMsg(DataBaseBase):
+
+ def get_label_by_id(self, label_id) -> str:
+ sql = '''
+ select LabelName from ContactLabel
+ where LabelId = ?
+ '''
+ try:
+ cursor = self.DB.cursor()
+ cursor.execute(sql, [label_id])
+ result = cursor.fetchone()
+ if result:
+ return result[0]
+ else:
+ return ''
+ except:
+ return ''
+
+ def get_labels(self, label_id_list) -> str:
+ if not label_id_list:
+ return ''
+ return ','.join(map(self.get_label_by_id, label_id_list.strip(',').split(',')))
+
+ def get_contact(self) -> list:
+ if not self.open_flag:
+ return []
+ try:
+ sql = '''SELECT UserName, Alias, Type, Remark, NickName, PYInitial, RemarkPYInitial, ContactHeadImgUrl.smallHeadImgUrl, ContactHeadImgUrl.bigHeadImgUrl,ExTraBuf,LabelIDList
+ FROM Contact
+ INNER JOIN ContactHeadImgUrl ON Contact.UserName = ContactHeadImgUrl.usrName
+ WHERE (Type!=4 AND Type!=0)
+ ORDER BY
+ CASE
+ WHEN RemarkQuanPin = '' THEN QuanPin
+ ELSE RemarkQuanPin
+ END ASC
+ '''
+ cursor = self.DB.cursor()
+ cursor.execute(sql)
+ result = cursor.fetchall()
+ except sqlite3.OperationalError:
+ # lock.acquire(True)
+ sql = '''SELECT UserName, Alias, Type, Remark, NickName, PYInitial, RemarkPYInitial,
+ ContactHeadImgUrl.smallHeadImgUrl, ContactHeadImgUrl.bigHeadImgUrl,ExTraBuf,"None"
+ FROM Contact INNER
+ JOIN ContactHeadImgUrl ON Contact.UserName = ContactHeadImgUrl.usrName WHERE (Type!=4 AND Type!=0)
+ AND NickName != '' ORDER BY CASE WHEN RemarkQuanPin = '' THEN QuanPin ELSE RemarkQuanPin END ASC'''
+ self.cursor.execute(sql)
+ result = self.cursor.fetchall()
+ return result
+
+ def get_contact_by_username(self, username) -> list:
+ if not self.open_flag:
+ return []
+ try:
+ sql = '''
+ SELECT UserName, Alias, Type, Remark, NickName, PYInitial, RemarkPYInitial, ContactHeadImgUrl.smallHeadImgUrl, ContactHeadImgUrl.bigHeadImgUrl,ExTraBuf,LabelIDList
+ FROM Contact
+ INNER JOIN ContactHeadImgUrl ON Contact.UserName = ContactHeadImgUrl.usrName
+ WHERE UserName = ?
+ '''
+ cursor = self.DB.cursor()
+ cursor.execute(sql, [username])
+ result1 = cursor.fetchone()
+ except sqlite3.OperationalError:
+ # 解决ContactLabel表不存在的问题
+ # lock.acquire(True)
+ sql = '''
+ SELECT UserName, Alias, Type, Remark, NickName, PYInitial, RemarkPYInitial, ContactHeadImgUrl.smallHeadImgUrl, ContactHeadImgUrl.bigHeadImgUrl,ExTraBuf,""
+ FROM Contact
+ INNER JOIN ContactHeadImgUrl ON Contact.UserName = ContactHeadImgUrl.usrName
+ WHERE UserName = ?
+ '''
+ self.cursor.execute(sql, [username])
+ result1 = self.cursor.fetchone()
+ if result1:
+ result = [*result1[:-1], self.get_labels(result1[-1])]
+ return result
+ else:
+ return []
+
+ def set_remark(self, username, remark) -> bool:
+ try:
+ update_sql = '''
+ UPDATE Contact
+ SET Remark = ?
+ WHERE UserName = ?
+ '''
+ cursor = self.DB.cursor()
+ cursor.execute(update_sql, [remark, username])
+ self.commit() # 提交更改
+ except:
+ return False
+ return True
+
+ def set_head_image(self, username, image_url):
+ pass
+
+ def get_chatroom_info(self, chatroomname):
+ """
+ 获取群聊信息
+ """
+ if not self.open_flag:
+ return None
+ sql = '''SELECT ChatRoomName, RoomData,UserNameList,DisplayNameList FROM ChatRoom WHERE ChatRoomName = ?'''
+ cursor = self.DB.cursor()
+ cursor.execute(sql, [chatroomname])
+ result = cursor.fetchone()
+ return result
+
+ def add_contact(self, contact: Contact):
+ sql1 = '''
+ insert into Contact (UserName,Alias,Remark,NickName,Type)
+ values(?,?,?,?,10086);
+ '''
+ sql2 = '''
+ insert into ContactHeadImgUrl (usrName,smallHeadImgUrl,bigHeadImgUrl)
+ values(?,?,?);
+ '''
+ try:
+ cursor = self.DB.cursor()
+ cursor.execute(sql1, [contact.wxid, contact.alias, contact.remark, contact.nickname])
+ cursor.execute(sql2, [contact.wxid, contact.small_head_img_url, contact.big_head_img_url])
+ self.commit()
+ except:
+ logger.error(traceback.format_exc())
+ return True
+
+ def get_session(self):
+ """
+ 获取聊天对话
+ @return:
+ """
+ if not self.open_flag:
+ return None
+ sql = '''
+ SELECT strUsrName, nOrder,nUnreadCount,strNickName ,nIsSend,strContent,nMsgType,nTime,strftime('%Y/%m/%d', nTime, 'unixepoch','localtime') AS strTime
+ FROM Session
+ '''
+ cursor = self.DB.cursor()
+ cursor.execute(sql)
+ result = cursor.fetchall()
+ if result:
+ result.reverse()
+ return result
+
+ def merge(self, db_path):
+ if not (os.path.exists(db_path) or os.path.isfile(db_path)):
+ print(f'{db_path} 不存在')
+ return
+ try:
+ # 获取列名
+ increase_update_data(db_path, self.cursor, self.DB, 'ChatRoom', 'ChatRoomName', 0)
+ increase_update_data(db_path, self.cursor, self.DB, 'ChatRoomInfo', 'ChatRoomName', 0)
+ increase_update_data(db_path, self.cursor, self.DB, 'Contact', 'UserName', 0)
+ increase_update_data(db_path, self.cursor, self.DB, 'ContactHeadImgUrl', 'usrName', 0)
+ increase_update_data(db_path, self.cursor, self.DB, 'ContactLabel', 'LabelId', 0)
+ increase_update_data(db_path, self.cursor, self.DB, 'Session', 'strUsrName', 0)
+ except:
+ print(f"数据库操作错误: {traceback.format_exc()}")
+ self.DB.rollback()
+
+
+if __name__ == '__main__':
+ db_path = "./Msg/MicroMsg.db"
+ msg = MicroMsg()
+ msg.init_database()
+ contacts = msg.get_contact()
+
+ sessions = msg.get_session()
+ print(sessions)
+ for session in sessions:
+ print(session)
diff --git a/wxManager/db_v3/misc.py b/wxManager/db_v3/misc.py
new file mode 100644
index 0000000..9bbfa42
--- /dev/null
+++ b/wxManager/db_v3/misc.py
@@ -0,0 +1,80 @@
+import hashlib
+import io
+import os.path
+import shutil
+import sqlite3
+import time
+import traceback
+
+from PIL import Image
+
+from wxManager.merge import increase_update_data
+from wxManager.log import logger
+from wxManager.model import DataBaseBase
+
+
+class Misc(DataBaseBase):
+
+ def get_avatar_buffer(self, username):
+ if not self.open_flag:
+ return None
+ sql = '''
+ select smallHeadBuf
+ from ContactHeadImg1
+ where usrName=?;
+ '''
+ cursor = self.DB.cursor()
+ cursor.execute(sql, [username])
+ result = cursor.fetchall()
+ cursor.close()
+ self.DB.commit()
+ if result:
+ return result[0][0]
+ else:
+ return b''
+
+ def set_avatar_buffer(self, username, img_path):
+ try:
+ # 打开图片并缩放
+ with Image.open(img_path) as img:
+ img = img.resize((128, 128))
+
+ # 将图片转换为二进制格式
+ img_byte_arr = io.BytesIO()
+ img.save(img_byte_arr, format='PNG') # 可以根据需要更改格式
+ img_binary = img_byte_arr.getvalue()
+ md5_hash = hashlib.md5()
+ md5_hash.update(img_binary)
+
+ update_sql = '''
+ UPDATE ContactHeadImg1
+ SET createTime = ?,smallHeadBuf=?
+ WHERE usrName = ?
+ '''
+ cursor = self.DB.cursor()
+ cursor.execute(update_sql, [int(time.time()), img_binary, username, md5_hash.hexdigest()])
+ # 检查是否有行被更新
+ if cursor.rowcount == 0:
+ # 如果没有更新,则插入新记录
+ insert_sql = '''
+ INSERT INTO head_image (username,md5, image_buffer,update_time)
+ VALUES (?, ?,?,?)
+ '''
+ cursor.execute(insert_sql, [username, md5_hash.hexdigest(), int(time.time()), img_binary])
+ cursor.close()
+ self.commit() # 提交更改
+ except:
+ logger.error(traceback.format_exc())
+ return False
+ return True
+
+ def merge(self, db_path):
+ if not (os.path.exists(db_path) or os.path.isfile(db_path)):
+ print(f'{db_path} 不存在')
+ return
+ try:
+ # 获取列名
+ increase_update_data(db_path, self.DB.cursor(), self.DB, 'ContactHeadImg1', 'usrName', 0)
+ except:
+ print(f"数据库操作错误: {traceback.format_exc()}")
+ self.DB.rollback()
diff --git a/wxManager/db_v3/msg.py b/wxManager/db_v3/msg.py
new file mode 100644
index 0000000..577ac41
--- /dev/null
+++ b/wxManager/db_v3/msg.py
@@ -0,0 +1,301 @@
+import os.path
+import shutil
+import sqlite3
+import traceback
+import concurrent
+import hashlib
+import threading
+from concurrent.futures import ThreadPoolExecutor
+from datetime import datetime, date
+from typing import Tuple
+
+from wxManager import MessageType
+from wxManager.merge import increase_data, increase_update_data
+from wxManager.log import logger
+from wxManager.model import DataBaseBase
+
+
+def convert_to_timestamp_(time_input) -> int:
+ if isinstance(time_input, (int, float)):
+ # 如果输入是时间戳,直接返回
+ return int(time_input)
+ elif isinstance(time_input, str):
+ # 如果输入是格式化的时间字符串,将其转换为时间戳
+ try:
+ dt_object = datetime.strptime(time_input, '%Y-%m-%d %H:%M:%S')
+ return int(dt_object.timestamp())
+ except ValueError:
+ # 如果转换失败,可能是其他格式的字符串,可以根据需要添加更多的处理逻辑
+ print("Error: Unsupported date format")
+ return -1
+ elif isinstance(time_input, date):
+ # 如果输入是datetime.date对象,将其转换为时间戳
+ dt_object = datetime.combine(time_input, datetime.min.time())
+ return int(dt_object.timestamp())
+ else:
+ print("Error: Unsupported input type")
+ return -1
+
+
+def convert_to_timestamp(time_range) -> Tuple[int, int]:
+ """
+ 将时间转换成时间戳
+ @param time_range:
+ @return:
+ """
+ if not time_range:
+ return 0, 0
+ else:
+ return convert_to_timestamp_(time_range[0]), convert_to_timestamp_(time_range[1])
+
+
+def get_local_type(type_: MessageType):
+ type_name_dict = {
+ MessageType.Text: (1, 0),
+ MessageType.Image: (3, 0),
+ MessageType.Audio: (34, 0),
+ MessageType.Video: (43, 0),
+ MessageType.Emoji: (47, 0),
+ MessageType.BusinessCard: (42, 0),
+ MessageType.OpenIMBCard: (66, 0),
+ MessageType.Position: (48, 0),
+ MessageType.FavNote: (49, 40),
+ MessageType.FavNote: (49, 24),
+ (49, 53): "接龙",
+ MessageType.File: (49, 0),
+ MessageType.Text2: (49, 1),
+ MessageType.Music: (49, 3),
+ MessageType.Music: (49, 76),
+ MessageType.LinkMessage: (49, 5),
+ MessageType.File: (49, 6),
+ (49, 8): "用户上传的GIF表情",
+ MessageType.System: (49, 17), # 发起了位置共享
+ MessageType.MergedMessages: (49, 19),
+ MessageType.Applet: (49, 33),
+ MessageType.Applet2: (49, 36),
+ MessageType.WeChatVideo: (49, 51),
+ (49, 57): MessageType.Quote,
+ (49, 63): "视频号直播或直播回放等",
+ (49, 87): "群公告",
+ (49, 88): "视频号直播或直播回放等",
+ (49, 2000): MessageType.Transfer,
+ (49, 2003): "赠送红包封面",
+ (50, 0): MessageType.Voip,
+ (10000, 0): MessageType.System,
+ (10000, 4): MessageType.Pat,
+ (10000, 8000): MessageType.System
+ }
+ return type_name_dict.get(type_, (0, 0))
+
+
+class Msg(DataBaseBase):
+
+ def _get_messages_by_num(self, cursor, username_, start_sort_seq, msg_num):
+ sql = '''
+ select localId,TalkerId,Type,SubType,IsSender,CreateTime,Status,StrContent,strftime('%Y-%m-%d %H:%M:%S',CreateTime,'unixepoch','localtime') as StrTime,MsgSvrID,BytesExtra,CompressContent,DisplayContent
+ from MSG
+ where StrTalker = ? and CreateTime < ?
+ order by CreateTime desc
+ limit ?
+ '''
+ cursor.execute(sql, [username_, start_sort_seq, msg_num])
+ result = cursor.fetchall()
+ if result:
+ return result
+ else:
+ return []
+
+ def get_messages_by_num(self, username, start_sort_seq, msg_num=20):
+ results = []
+ # for db in self.DB:
+ # cursor = db.cursor()
+ # yield self._get_messages_by_num(cursor, username, start_sort_seq, msg_num)
+ lock = threading.Lock() # 锁,用于确保线程安全地写入 results
+
+ def task(db):
+ """
+ 每个线程执行的任务,获取某个数据库实例中的查询结果。
+ """
+ cursor = db.cursor()
+ try:
+ data = self._get_messages_by_num(cursor, username, start_sort_seq, msg_num)
+ with lock: # 确保对 results 的操作是线程安全的
+ results.append(data)
+ finally:
+ cursor.close()
+
+ # 使用线程池
+ with ThreadPoolExecutor(max_workers=len(self.DB)) as executor:
+ executor.map(task, self.DB)
+ self.commit()
+ return results
+
+ def _get_messages_by_username(self, cursor, username: str,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None, ):
+ if time_range:
+ start_time, end_time = convert_to_timestamp(time_range)
+ sql = f'''
+ select localId,TalkerId,Type,SubType,IsSender,CreateTime,Status,StrContent,strftime('%Y-%m-%d %H:%M:%S',CreateTime,'unixepoch','localtime') as StrTime,MsgSvrID,BytesExtra,CompressContent,DisplayContent
+ from MSG
+ where StrTalker=?
+ {'AND CreateTime>' + str(start_time) + ' AND CreateTime<' + str(end_time) if time_range else ''}
+ order by CreateTime
+ '''
+ cursor.execute(sql, [username])
+ result = cursor.fetchall()
+ if result:
+ return result
+ else:
+ return []
+
+ def get_messages_by_username(self, username: str,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None, ):
+ with concurrent.futures.ThreadPoolExecutor() as executor:
+ # 创建一个任务列表
+ futures = [
+ executor.submit(self._get_messages_by_username, db.cursor(), username, time_range)
+ for db in self.DB
+ ]
+
+ # 等待所有任务完成,并获取结果
+ results = []
+ for future in concurrent.futures.as_completed(futures):
+ r1 = future.result()
+ if r1:
+ # results.append(future.result())
+ results.extend(r1)
+
+ return results
+
+ def get_message_by_server_id(self, username, server_id):
+ """
+ 获取小于start_sort_seq的msg_num个消息
+ @param username:
+ @param server_id:
+ @return: messages, 最后一条消息的start_sort_seq
+ """
+ sql = f'''
+ select localId,TalkerId,Type,SubType,IsSender,CreateTime,Status,StrContent,strftime('%Y-%m-%d %H:%M:%S',CreateTime,'unixepoch','localtime') as StrTime,MsgSvrID,BytesExtra,CompressContent,DisplayContent
+ from MSG
+ where MsgSvrID=?
+'''
+ for db in self.DB:
+ cursor = db.cursor()
+ cursor.execute(sql, [server_id])
+ result = cursor.fetchone()
+ if result:
+ return result
+
+ return None
+
+ def _get_messages_calendar(self, cursor, username):
+ """
+ 获取某个人的聊天日历列表
+ @param username_:
+ @return:
+ """
+ sql = f'''SELECT DISTINCT strftime('%Y-%m-%d',create_time,'unixepoch','localtime') AS date
+ from MSG
+ where StrTalker=?
+ ORDER BY date desc;
+ '''
+ cursor.execute(sql, [username])
+ result = cursor.fetchall()
+ return (data[0] for data in result)
+
+ def get_messages_calendar(self, username):
+ res = []
+ for db in self.DB:
+ r1 = self._get_messages_calendar(db.cursor(), username)
+ if r1:
+ res.extend(r1)
+ res.sort()
+ return res
+
+ def _get_messages_by_type(self, cursor, username: str, type_: MessageType,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None, ):
+ if time_range:
+ start_time, end_time = convert_to_timestamp(time_range)
+ local_type, sub_type = get_local_type(type_)
+ sql = f'''
+ select localId,TalkerId,Type,SubType,IsSender,CreateTime,Status,StrContent,strftime('%Y-%m-%d %H:%M:%S',CreateTime,'unixepoch','localtime') as StrTime,MsgSvrID,BytesExtra,CompressContent,DisplayContent
+ from MSG
+ where StrTalker=? and Type=? and SubType = ?
+ {'AND CreateTime>' + str(start_time) + ' AND CreateTime<' + str(end_time) if time_range else ''}
+ order by CreateTime
+ '''
+ cursor.execute(sql, [username, local_type, sub_type])
+ result = cursor.fetchall()
+ if result:
+ return result
+ else:
+ return None
+
+ def get_messages_by_type(self, username: str, type_: MessageType,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None, ):
+ with concurrent.futures.ThreadPoolExecutor() as executor:
+ # 创建一个任务列表
+ futures = [
+ executor.submit(self._get_messages_by_type, db.cursor(), username, type_, time_range)
+ for db in self.DB
+ ]
+
+ # 等待所有任务完成,并获取结果
+ results = []
+ for future in concurrent.futures.as_completed(futures):
+ r1 = future.result()
+ if r1:
+ # results.append(future.result())
+ results.extend(r1)
+
+ return results
+
+ def update_audio_text(self, MsgSvrID_, voicetrans_text):
+ voicetrans_tag = f'
'
+ sql_xml = f'''
+ SELECT StrContent FROM MSG WHERE MsgSvrID = ?
+ '''
+ sql_update = f'''
+ UPDATE MSG SET StrContent = ? WHERE MsgSvrID = ?'''
+ try:
+ lock.acquire(True)
+ self.cursor.execute(sql_xml, [MsgSvrID_])
+ strContent = self.cursor.fetchone()[0]
+ insert_position = strContent.find('')
+ new_strContent = strContent[:insert_position] + voicetrans_tag + strContent[insert_position:]
+ self.cursor.execute(sql_update, [new_strContent, MsgSvrID_])
+ self.DB.commit()
+ except sqlite3.DatabaseError:
+ logger.error(f'{traceback.format_exc()}\n数据库损坏请删除msg文件夹重试')
+ finally:
+ lock.release()
+
+ def merge(self, db_file_name):
+ def task_(db_path, cursor, db):
+ """
+ 每个线程执行的任务,获取某个数据库实例中的查询结果。
+ """
+ increase_data(db_path, cursor, db, 'Name2Id', 'UsrName')
+ increase_update_data(db_path, cursor, db, 'DBInfo', 'tableIndex')
+ increase_data(db_path, cursor, db, 'MSG', 'MsgSvrID', exclude_first_column=True)
+
+ tasks = []
+ for i in range(100):
+ db_path = db_file_name.replace('0', f'{i}')
+ if os.path.exists(db_path):
+ # print('初始化数据库:', db_path)
+ file_name = os.path.basename(db_path)
+ if file_name in self.db_file_name:
+ index = self.db_file_name.index(file_name)
+ db = self.DB[index]
+ cursor = db.cursor()
+ task_(db_path, cursor, db)
+ tasks.append([db_path, cursor, db])
+ else:
+ shutil.copy(db_path, os.path.join(self.db_dir, 'Multi', file_name))
+ # print(tasks)
+ # 使用线程池 (没有加快合并速度)
+ # with ThreadPoolExecutor(max_workers=len(tasks)) as executor:
+ # executor.map(lambda args: task_(*args), tasks)
+ self.commit()
+ print(len(tasks))
diff --git a/wxManager/db_v3/open_im_contact.py b/wxManager/db_v3/open_im_contact.py
new file mode 100644
index 0000000..e11f899
--- /dev/null
+++ b/wxManager/db_v3/open_im_contact.py
@@ -0,0 +1,144 @@
+import os.path
+import shutil
+import sqlite3
+import threading
+import traceback
+
+from wxManager.merge import increase_update_data
+from wxManager.log import logger
+from wxManager.model import DataBaseBase
+
+
+class OpenIMContactDB(DataBaseBase):
+ def get_contacts(self):
+ result = []
+ if not self.open_flag:
+ return result
+ try:
+ sql = '''SELECT UserName,NickName,Type,Remark,BigHeadImgUrl,SmallHeadImgUrl,Source,NickNamePYInit,NickNameQuanPin,RemarkPYInit,RemarkQuanPin,CustomInfoDetail,DescWordingId
+ FROM OpenIMContact
+ WHERE Type!=0 AND Type!=4
+ '''
+ cursor = self.DB.cursor()
+ cursor.execute(sql)
+ result = cursor.fetchall()
+ self.commit() # 提交更改
+ except sqlite3.OperationalError:
+ logger.error(f'数据库错误:\n{traceback.format_exc()}')
+ res = []
+ if result:
+ for contact in result:
+ wording = self.get_wordinfo(contact[12])
+ if wording:
+ res.append((*contact, wording[1]))
+ else:
+ res.append((*contact, ''))
+ return res
+
+ def set_remark(self, username, remark):
+ update_sql = '''
+ UPDATE OpenIMContact
+ SET Remark = ?
+ WHERE UserName = ?
+ '''
+ cursor = self.DB.cursor()
+ cursor.execute(update_sql, [remark, username])
+ self.commit() # 提交更改
+ return True
+
+ def get_contact_by_username(self, username_):
+ result = []
+ if not self.open_flag:
+ return result
+ try:
+ sql = '''SELECT UserName,NickName,Type,Remark,BigHeadImgUrl,SmallHeadImgUrl,Source,NickNamePYInit,NickNameQuanPin,RemarkPYInit,RemarkQuanPin,CustomInfoDetail,DescWordingId
+ FROM OpenIMContact
+ WHERE UserName=?
+ '''
+ cursor = self.DB.cursor()
+ cursor.execute(sql, [username_])
+ result = cursor.fetchone()
+ self.commit() # 提交更改
+ except sqlite3.OperationalError:
+ logger.error(f'数据库错误:\n{traceback.format_exc()}')
+ if result:
+ result = list(result)
+ wording = self.get_wordinfo(result[12])
+ if wording:
+ result.append(wording[1])
+ else:
+ result.append('')
+ return result
+
+ def get_wordinfo(self, wording_id):
+ """
+ 获取企业微信所在的公司
+ @param wording_id:
+ @return: WordingId, id
+ Wording, 企业名
+ Pinyin, 拼音
+ Quanpin, 全拼
+ UpdateTime 更新时间
+ """
+ result = []
+ return result
+ if not self.open_flag:
+ return result
+ try:
+ sql = '''SELECT WordingId,Wording,Pinyin,Quanpin,UpdateTime
+ FROM OpenIMWordingInfo
+ WHERE WordingId=?
+ '''
+ cursor = self.DB.cursor()
+ cursor.execute(sql, [wording_id])
+ result = cursor.fetchone()
+ self.commit() # 提交更改
+ except sqlite3.OperationalError:
+ logger.error(f'数据库错误:\n{traceback.format_exc()}')
+ return result
+
+
+ def increase_source(self, db_path_):
+ if not (os.path.exists(db_path_) or os.path.isfile(db_path_)):
+ print(f'{db_path_} 不存在')
+ return
+ if not self.sourceDB or not self.sourceCursor:
+ print(f'企业微信数据异常,尝试修复···')
+ try:
+ os.remove(open_im_source_db_path)
+ except:
+ pass
+ try:
+ shutil.copy(db_path_, open_im_source_db_path)
+ except:
+ pass
+ return
+ try:
+ lock.acquire(True)
+ # 获取列名
+ increase_update_data(db_path_, self.sourceCursor, self.sourceDB, 'OpenIMWordingInfo', 'WordingId', 2)
+ except sqlite3.Error as e:
+ print(f"数据库操作错误: {e}")
+ self.sourceDB.rollback()
+ finally:
+ lock.release()
+
+ def merge(self, db_path):
+ if not (os.path.exists(db_path) or os.path.isfile(db_path)):
+ print(f'{db_path} 不存在')
+ return
+ try:
+ # 获取列名
+ increase_update_data(db_path, self.cursor, self.DB, 'OpenIMContact', 'UserName', 0)
+ except:
+ print(f"数据库操作错误: {traceback.format_exc()}")
+ self.DB.rollback()
+
+
+if __name__ == '__main__':
+ db_path = "./Msg/OpenIMContact.db"
+ msg = OpenIMContactDB()
+ msg.init_database()
+ contacts = msg.get_contacts()
+ for contact in contacts:
+ print(contact)
diff --git a/wxManager/db_v3/open_im_media.py b/wxManager/db_v3/open_im_media.py
new file mode 100644
index 0000000..76a5a4a
--- /dev/null
+++ b/wxManager/db_v3/open_im_media.py
@@ -0,0 +1,47 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2025/2/17 21:34
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-open_im_media.py
+@Description :
+"""
+
+import os.path
+import shutil
+import sqlite3
+import traceback
+
+from wxManager.merge import increase_data
+from wxManager.log import logger
+from wxManager.model import DataBaseBase
+
+
+class OpenIMMediaDB(DataBaseBase):
+ def get_media_buffer(self, reserved0):
+ sql = '''
+ select Buf
+ from OpenIMMedia
+ where Reserved0 = ?
+ '''
+ cursor = self.DB.cursor()
+ cursor.execute(sql, [reserved0])
+ result = cursor.fetchone()
+ self.commit()
+ if result:
+ return result[0]
+ else:
+ return None
+
+ def merge(self, db_path):
+ if not (os.path.exists(db_path) or os.path.isfile(db_path)):
+ print(f'{db_path} 不存在')
+ return
+ try:
+ # 获取列名
+ increase_data(db_path, self.cursor, self.DB, 'OpenIMMedia', 'Reserved0', 1)
+ except:
+ print(f"数据库操作错误: {traceback.format_exc()}")
+ self.DB.rollback()
diff --git a/wxManager/db_v3/open_im_msg.py b/wxManager/db_v3/open_im_msg.py
new file mode 100644
index 0000000..9d7a888
--- /dev/null
+++ b/wxManager/db_v3/open_im_msg.py
@@ -0,0 +1,147 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2025/2/17 21:43
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-open_im_msg.py
+@Description :
+"""
+
+import os.path
+import sqlite3
+import threading
+import traceback
+import concurrent
+import hashlib
+import threading
+from collections import defaultdict
+from concurrent.futures import ThreadPoolExecutor
+from datetime import datetime, date
+from typing import Tuple
+
+from wxManager.merge import increase_data, increase_update_data
+from wxManager.log import logger
+from wxManager.model import DataBaseBase
+from wxManager.parser.util.protocbuf.msg_pb2 import MessageBytesExtra
+
+
+def convert_to_timestamp_(time_input) -> int:
+ if isinstance(time_input, (int, float)):
+ # 如果输入是时间戳,直接返回
+ return int(time_input)
+ elif isinstance(time_input, str):
+ # 如果输入是格式化的时间字符串,将其转换为时间戳
+ try:
+ dt_object = datetime.strptime(time_input, '%Y-%m-%d %H:%M:%S')
+ return int(dt_object.timestamp())
+ except ValueError:
+ # 如果转换失败,可能是其他格式的字符串,可以根据需要添加更多的处理逻辑
+ print("Error: Unsupported date format")
+ return -1
+ elif isinstance(time_input, date):
+ # 如果输入是datetime.date对象,将其转换为时间戳
+ dt_object = datetime.combine(time_input, datetime.min.time())
+ return int(dt_object.timestamp())
+ else:
+ print("Error: Unsupported input type")
+ return -1
+
+
+def convert_to_timestamp(time_range) -> Tuple[int, int]:
+ """
+ 将时间转换成时间戳
+ @param time_range:
+ @return:
+ """
+ if not time_range:
+ return 0, 0
+ else:
+ return convert_to_timestamp_(time_range[0]), convert_to_timestamp_(time_range[1])
+
+
+class OpenIMMsgDB(DataBaseBase):
+
+ def _get_messages_by_num(self, cursor, username_, start_sort_seq, msg_num):
+ """
+
+ @param cursor:
+ @param username_:
+ @param start_sort_seq:
+ @param msg_num:
+ @return:
+ """
+ sql = '''
+ select localId,TalkerId,Type,statusEx,IsSender,CreateTime,Status,StrContent,strftime('%Y-%m-%d %H:%M:%S',CreateTime,'unixepoch','localtime') as StrTime,MsgSvrID,BytesExtra,'',Reserved1
+ from ChatCRMsg
+ where StrTalker = ? and CreateTime < ?
+ order by CreateTime desc
+ limit ?
+ '''
+ cursor.execute(sql, [username_, start_sort_seq, msg_num])
+ result = cursor.fetchall()
+ if result:
+ return result
+ else:
+ return []
+
+ def get_messages_by_num(self, username, start_sort_seq, msg_num=20):
+ results = [self._get_messages_by_num(self.DB.cursor(), username, start_sort_seq, msg_num)]
+ self.commit()
+ return results
+
+ def _get_messages_by_username(self, cursor, username: str,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None, ):
+ if time_range:
+ start_time, end_time = convert_to_timestamp(time_range)
+ sql = f'''
+ select localId,TalkerId,Type,statusEx,IsSender,CreateTime,Status,StrContent,strftime('%Y-%m-%d %H:%M:%S',CreateTime,'unixepoch','localtime') as StrTime,MsgSvrID,BytesExtra,'',Reserved1
+ from ChatCRMsg
+ where StrTalker=?
+ {'AND CreateTime>' + str(start_time) + ' AND CreateTime<' + str(end_time) if time_range else ''}
+ order by CreateTime
+ '''
+ cursor.execute(sql, [username])
+ result = cursor.fetchall()
+ if result:
+ return result
+ else:
+ return []
+
+ def get_messages_by_username(self, username: str,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None, ):
+ result = self._get_messages_by_username(self.DB.cursor(), username, time_range)
+ return [result]
+
+ def get_message_by_server_id(self, username, server_id):
+ """
+ 获取小于start_sort_seq的msg_num个消息
+ @param username:
+ @param server_id:
+ @return: messages, 最后一条消息的start_sort_seq
+ """
+ sql = f'''
+ select localId,TalkerId,Type,statusEx,IsSender,CreateTime,Status,StrContent,strftime('%Y-%m-%d %H:%M:%S',CreateTime,'unixepoch','localtime') as StrTime,MsgSvrID,BytesExtra,'',Reserved1
+ from ChatCRMsg
+ where MsgSvrID=?
+'''
+ for db in self.DB:
+ cursor = db.cursor()
+ cursor.execute(sql, [server_id])
+ result = cursor.fetchone()
+ if result:
+ return result
+
+ return None
+
+ def merge(self, db_path):
+ if not (os.path.exists(db_path) or os.path.isfile(db_path)):
+ print(f'{db_path} 不存在')
+ return
+ try:
+ # 获取列名
+ increase_update_data(db_path, self.cursor, self.DB, 'ChatCRMsg', 'MsgSvrID', 1, exclude_first_column=True)
+ except:
+ print(f"数据库操作错误: {traceback.format_exc()}")
+ self.DB.rollback()
\ No newline at end of file
diff --git a/wxManager/db_v3/public_msg.py b/wxManager/db_v3/public_msg.py
new file mode 100644
index 0000000..b2fb969
--- /dev/null
+++ b/wxManager/db_v3/public_msg.py
@@ -0,0 +1,189 @@
+import concurrent
+import os.path
+import shutil
+import sqlite3
+import threading
+import traceback
+from datetime import date
+from typing import Tuple
+from concurrent.futures import ThreadPoolExecutor
+
+from wxManager.merge import increase_data
+from wxManager.db_v3.msg import convert_to_timestamp
+from wxManager.model import DataBaseBase
+
+
+class PublicMsg(DataBaseBase):
+
+ def get_messages(
+ self,
+ username_: str,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None,
+ ):
+ """
+ return list
+ a[0]: localId,
+ a[1]: talkerId, (和strtalker对应的,不是群聊信息发送人)
+ a[2]: type,
+ a[3]: subType,
+ a[4]: is_sender,
+ a[5]: timestamp,
+ a[6]: status, (没啥用)
+ a[7]: str_content,
+ a[8]: str_time, (格式化的时间)
+ a[9]: msgSvrId,
+ a[10]: BytesExtra,
+ a[11]: CompressContent,
+ a[12]: DisplayContent,
+ a[13]: 联系人的类(如果是群聊就有,不是的话没有这个字段)
+ """
+ if not self.open_flag:
+ return []
+ if time_range:
+ start_time, end_time = convert_to_timestamp(time_range)
+ sql = f'''
+ select localId,TalkerId,Type,SubType,IsSender,CreateTime,Status,StrContent,strftime('%Y-%m-%d %H:%M:%S',CreateTime,'unixepoch','localtime') as StrTime,MsgSvrID,BytesExtra,CompressContent,DisplayContent
+ from PublicMsg
+ where StrTalker=?
+ {'AND CreateTime>' + str(start_time) + ' AND CreateTime<' + str(end_time) if time_range else ''}
+ order by CreateTime
+ '''
+ try:
+ lock.acquire(True)
+ self.cursor.execute(sql, [username_])
+ result = self.cursor.fetchall()
+ finally:
+ lock.release()
+ return result
+
+ def get_messages_by_type(
+ self,
+ username_: str,
+ type_,
+ sub_type=None,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None,
+ ):
+ if not self.open_flag:
+ return []
+ if time_range:
+ start_time, end_time = convert_to_timestamp(time_range)
+ sql = f'''
+ select localId,TalkerId,Type,SubType,IsSender,CreateTime,Status,StrContent,strftime('%Y-%m-%d %H:%M:%S',CreateTime,'unixepoch','localtime') as StrTime,MsgSvrID,BytesExtra,CompressContent,DisplayContent
+ from PublicMsg
+ where StrTalker=? AND Type=? {'AND SubType=' + str(sub_type) if sub_type else ''}
+ {'AND CreateTime>' + str(start_time) + ' AND CreateTime<' + str(end_time) if time_range else ''}
+ order by CreateTime
+ '''
+ try:
+ lock.acquire(True)
+ self.cursor.execute(sql, [username_, type_])
+ result = self.cursor.fetchall()
+ finally:
+ lock.release()
+ return result
+
+ def get_sport_score_by_name(self, username,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None, ):
+ if not self.open_flag:
+ return 0
+
+ def _get_messages_by_num(self, cursor, username_, start_sort_seq, msg_num):
+ sql = '''
+ select localId,TalkerId,Type,SubType,IsSender,CreateTime,Status,StrContent,strftime('%Y-%m-%d %H:%M:%S',CreateTime,'unixepoch','localtime') as StrTime,MsgSvrID,BytesExtra,CompressContent,DisplayContent
+ from PublicMsg
+ where StrTalker = ? and CreateTime < ?
+ order by CreateTime desc
+ limit ?
+ '''
+ cursor.execute(sql, [username_, start_sort_seq, msg_num])
+ result = cursor.fetchall()
+ if result:
+ return result
+ else:
+ return []
+
+ def get_messages_by_num(self, username, start_sort_seq, msg_num=20):
+ cursor = self.DB.cursor()
+ yield self._get_messages_by_num(cursor, username, start_sort_seq, msg_num)
+
+ def _get_messages_by_username(self, cursor, username: str,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None, ):
+ if time_range:
+ start_time, end_time = convert_to_timestamp(time_range)
+ sql = f'''
+ select localId,TalkerId,Type,SubType,IsSender,CreateTime,Status,StrContent,strftime('%Y-%m-%d %H:%M:%S',CreateTime,'unixepoch','localtime') as StrTime,MsgSvrID,BytesExtra,CompressContent,DisplayContent
+ from PublicMsg
+ where StrTalker=?
+ {'AND CreateTime>' + str(start_time) + ' AND CreateTime<' + str(end_time) if time_range else ''}
+ order by CreateTime
+ '''
+ cursor.execute(sql, [username])
+ result = cursor.fetchall()
+ if result:
+ return result
+ else:
+ return []
+
+ def get_messages_by_username(self, username: str,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None, ):
+ return self._get_messages_by_username(self.DB.cursor(),username,time_range)
+
+ def get_message_by_server_id(self, username, server_id):
+ """
+ 获取小于start_sort_seq的msg_num个消息
+ @param username:
+ @param server_id:
+ @return: messages, 最后一条消息的start_sort_seq
+ """
+ sql = f'''
+ select localId,TalkerId,Type,SubType,IsSender,CreateTime,Status,StrContent,strftime('%Y-%m-%d %H:%M:%S',CreateTime,'unixepoch','localtime') as StrTime,MsgSvrID,BytesExtra,CompressContent,DisplayContent
+ from PublicMsg
+ where MsgSvrID=?
+ '''
+ cursor = self.DB.cursor()
+ cursor.execute(sql, [server_id])
+ result = cursor.fetchone()
+ if result:
+ return result
+ return None
+
+ def _get_messages_calendar(self, cursor, username):
+ """
+ 获取某个人的聊天日历列表
+ @param username_:
+ @return:
+ """
+ sql = f'''SELECT DISTINCT strftime('%Y-%m-%d',create_time,'unixepoch','localtime') AS date
+ from PublicMsg
+ where StrTalker=?
+ ORDER BY date desc;
+ '''
+ cursor.execute(sql, [username])
+ result = cursor.fetchall()
+ return (data[0] for data in result)
+
+ def get_messages_calendar(self, username):
+ res = []
+ r1 = self._get_messages_calendar(self.DB.cursor(), username)
+ if r1:
+ res.extend(r1)
+ res.sort()
+ return res
+
+ def merge(self, db_path):
+ if not (os.path.exists(db_path) or os.path.isfile(db_path)):
+ print(f'{db_path} 不存在')
+ return
+ try:
+ # 获取列名
+ increase_data(db_path, self.cursor, self.DB, 'PublicMsg', 'MsgSvrID', 1, exclude_first_column=True)
+ except:
+ print(f"数据库操作错误: {traceback.format_exc()}")
+ self.DB.rollback()
+
+
+if __name__ == '__main__':
+ pdb = PublicMsg()
+ db_path = "./Msg/PublicMsg.db"
+ pdb.init_database()
+ pdb.get_public_msg()
diff --git a/wxManager/db_v3/sns.py b/wxManager/db_v3/sns.py
new file mode 100644
index 0000000..d7385ab
--- /dev/null
+++ b/wxManager/db_v3/sns.py
@@ -0,0 +1,210 @@
+import os.path
+import sqlite3
+import threading
+from datetime import date
+from typing import Tuple
+
+from wxManager.db_v3.msg import convert_to_timestamp
+
+lock = threading.Lock()
+DB = None
+cursor = None
+db_path = '.'
+
+# db_path = "./app/Database/Msg/Misc.db"
+
+
+# db_path = './Msg/Misc.db'
+# 朋友圈类型
+type_ = {
+ '1': '图文',
+ '2': '文本',
+ '3': '应用分享(如:网易云音乐)',
+ '15': '视频',
+ '28': '视频号'
+}
+
+
+def singleton(cls):
+ _instance = {}
+
+ def inner():
+ if cls not in _instance:
+ _instance[cls] = cls()
+ return _instance[cls]
+
+ return inner
+
+
+# @singleton
+class Sns:
+ def __init__(self):
+ self.DB = None
+ self.cursor = None
+ self.open_flag = False
+ self.init_database()
+
+ def init_database(self, db_dir=''):
+ global db_path
+ if not self.open_flag:
+ if db_dir:
+ db_path = os.path.join(db_dir, 'Sns.db')
+ if os.path.exists(db_path):
+ self.DB = sqlite3.connect(db_path, check_same_thread=False)
+ # '''创建游标'''
+ self.cursor = self.DB.cursor()
+ self.open_flag = True
+ if lock.locked():
+ lock.release()
+
+ def close(self):
+ if self.open_flag:
+ try:
+ lock.acquire(True)
+ self.open_flag = False
+ self.DB.close()
+ finally:
+ lock.release()
+
+ def get_sns_bg_url(self) -> str:
+ """
+ 获取朋友圈背景URL
+ @return:
+ """
+ sql = '''
+ select StrValue
+ from SnsConfigV20
+ where Key=6;
+ '''
+ try:
+ lock.acquire(True)
+ self.cursor.execute(sql)
+ result = self.cursor.fetchall()
+ if result:
+ return result[0][0]
+ finally:
+ lock.release()
+ return ''
+
+ def get_feeds(
+ self,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None,
+ ):
+ """
+
+ @param time_range:
+ @return: List[
+ a[0]:FeedId,
+ a[1]:CreateTime,时间戳
+ a[2]:StrTime,时间戳,
+ a[3]:Type,类型,
+ a[4]:UserName,用户名wxid,
+ a[5]:Status,状态,
+ a[6]:StringId,id,
+ a[7]:Content,xml,
+ ]
+ """
+ if not self.open_flag:
+ return None
+ if time_range:
+ start_time, end_time = convert_to_timestamp(time_range)
+ result = []
+ sql = f'''
+ select FeedId,CreateTime,strftime('%Y-%m-%d %H:%M:%S',CreateTime,'unixepoch','localtime') as StrTime,Type,UserName,Status,StringId,Content
+ from FeedsV20
+ {'where CreateTime>' + str(start_time) + ' AND CreateTime<' + str(end_time) if time_range else ''}
+ order by CreateTime
+ '''
+ try:
+ lock.acquire(True)
+ self.cursor.execute(sql)
+ result = self.cursor.fetchall()
+ finally:
+ lock.release()
+ return result
+
+ def get_feeds_by_username(
+ self,
+ username,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None,
+ ):
+ """
+ @param time_range:
+ @return: List[
+ a[0]:FeedId,
+ a[1]:CreateTime,时间戳
+ a[2]:StrTime,时间戳,
+ a[3]:Type,类型,
+ a[4]:UserName,用户名wxid,
+ a[5]:Status,状态,
+ a[6]:StringId,id,
+ a[7]:Content,xml,
+ ]
+ """
+ if not self.open_flag:
+ return []
+ if time_range:
+ start_time, end_time = convert_to_timestamp(time_range)
+ result = []
+ sql = f'''
+ select FeedId,CreateTime,strftime('%Y-%m-%d %H:%M:%S',CreateTime,'unixepoch','localtime') as StrTime,Type,UserName,Status,StringId,Content
+ from FeedsV20
+ where UserName=?
+ {' AND CreateTime > ' + str(start_time) + ' AND CreateTime < ' + str(end_time) if time_range else ''}
+ order by CreateTime
+ '''
+ try:
+ lock.acquire(True)
+ self.cursor.execute(sql, [username])
+ result = self.cursor.fetchall()
+ finally:
+ lock.release()
+ return result
+
+ def get_comment(self, feed_id):
+ """
+
+ @param feed_id:
+ @return: List[
+ a[0]:FeedId,
+ a[1]:CommentId,
+ a[2]:CreateTime,时间戳,
+ a[3]:StrTime,
+ a[4]:CommentType,用户名wxid,
+ a[5]:Content,
+ a[6]:FromUserName
+ a[7]:ReplyUserName
+ a[8]:ReplyId
+ ]
+ """
+ if not self.open_flag:
+ return []
+
+ result = []
+ sql = f'''
+ select FeedId,CommentId,CreateTime,strftime('%Y-%m-%d %H:%M:%S',CreateTime,'unixepoch','localtime') as StrTime,CommentType,Content,FromUserName,ReplyUserName,ReplyId
+ from CommentV20
+ where FeedId=?
+ '''
+ try:
+ lock.acquire(True)
+ self.cursor.execute(sql, [feed_id])
+ result = self.cursor.fetchall()
+ finally:
+ lock.release()
+ return result
+
+ def __del__(self):
+ self.close()
+
+
+if __name__ == '__main__':
+ db_path = "./Msg1/Sns.db"
+ sns_db = Sns()
+ sns_db.init_database()
+ print(sns_db.get_sns_bg_url())
+ feeds = sns_db.get_feeds_by_username('wxid_27hqbq7vx5hf22')
+ print(feeds)
+ for feed in feeds:
+ comment = sns_db.get_comment(feed[0])
+ print(comment)
diff --git a/wxManager/db_v4/__init__.py b/wxManager/db_v4/__init__.py
new file mode 100644
index 0000000..8e1236e
--- /dev/null
+++ b/wxManager/db_v4/__init__.py
@@ -0,0 +1,19 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2024/12/5 22:46
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-__init__.py.py
+@Description :
+"""
+
+from .message import MessageDB
+from .contact import ContactDB
+from .session import SessionDB
+from .head_image import HeadImageDB
+from .hardlink import HardLinkDB
+
+if __name__ == '__main__':
+ pass
diff --git a/wxManager/db_v4/biz_message.py b/wxManager/db_v4/biz_message.py
new file mode 100644
index 0000000..c1f7643
--- /dev/null
+++ b/wxManager/db_v4/biz_message.py
@@ -0,0 +1,311 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2025/2/28 0:40
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : wxManager-biz_message.py
+@Description :
+"""
+import concurrent
+import hashlib
+import os
+import shutil
+import threading
+from concurrent.futures import ThreadPoolExecutor
+from datetime import date, datetime
+from typing import Tuple
+
+from wxManager import MessageType
+from wxManager.merge import increase_data, increase_update_data
+from wxManager.model.db_model import DataBaseBase
+
+
+def convert_to_timestamp_(time_input) -> int:
+ if isinstance(time_input, (int, float)):
+ # 如果输入是时间戳,直接返回
+ return int(time_input)
+ elif isinstance(time_input, str):
+ # 如果输入是格式化的时间字符串,将其转换为时间戳
+ try:
+ dt_object = datetime.strptime(time_input, '%Y-%m-%d %H:%M:%S')
+ return int(dt_object.timestamp())
+ except ValueError:
+ # 如果转换失败,可能是其他格式的字符串,可以根据需要添加更多的处理逻辑
+ print("Error: Unsupported date format")
+ return -1
+ elif isinstance(time_input, date):
+ # 如果输入是datetime.date对象,将其转换为时间戳
+ dt_object = datetime.combine(time_input, datetime.min.time())
+ return int(dt_object.timestamp())
+ else:
+ print("Error: Unsupported input type")
+ return -1
+
+
+def convert_to_timestamp(time_range) -> Tuple[int, int]:
+ """
+ 将时间转换成时间戳
+ @param time_range:
+ @return:
+ """
+ if not time_range:
+ return 0, 0
+ else:
+ return convert_to_timestamp_(time_range[0]), convert_to_timestamp_(time_range[1])
+
+
+def get_local_type(type_: MessageType):
+ return type_
+
+
+class BizMessageDB(DataBaseBase):
+ columns = (
+ "local_id,server_id,local_type,sort_seq,Name2Id.user_name as sender_username,create_time,strftime('%Y-%m-%d %H:%M:%S',"
+ "create_time,'unixepoch','localtime') as StrTime,status,upload_status,server_seq,origin_source,source,"
+ "message_content,compress_content")
+
+ def get_messages(self):
+ pass
+
+ def table_exists(self, cursor, table_name):
+ # 查询 sqlite_master 系统表,判断表是否存在
+ cursor.execute("SELECT name FROM sqlite_master WHERE type='table' AND name=?;", (table_name,))
+ result = cursor.fetchone()
+ # 如果结果不为空,表存在;否则表不存在
+ return result
+
+ def _get_messages_by_username(self, cursor, username: str,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None, ):
+ table_name = f'Msg_{hashlib.md5(username.encode("utf-8")).hexdigest()}'
+ if not self.table_exists(cursor, table_name):
+ return None
+ if time_range:
+ start_time, end_time = convert_to_timestamp(time_range)
+ sql = f'''
+select {BizMessageDB.columns}
+from {table_name} as msg
+join Name2Id on msg.real_sender_id = Name2Id.rowid
+{'where create_time>' + str(start_time) + ' AND create_time<' + str(end_time) if time_range else ''}
+order by sort_seq
+ '''
+ cursor.execute(sql)
+ result = cursor.fetchall()
+ if result:
+ return result
+ else:
+ return None
+
+ def get_messages_by_username(self, username: str,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None, ):
+ with concurrent.futures.ThreadPoolExecutor() as executor:
+ # 创建一个任务列表
+ futures = [
+ executor.submit(self._get_messages_by_username, db.cursor(), username, time_range)
+ for db in self.DB
+ ]
+
+ # 等待所有任务完成,并获取结果
+ results = []
+ for future in concurrent.futures.as_completed(futures):
+ r1 = future.result()
+ if r1:
+ # results.append(future.result())
+ results.extend(r1)
+
+ return results
+ results = []
+ # for db in self.DB:
+ # cursor = db.cursor()
+ # yield self._get_messages_by_num(cursor, username, start_sort_seq, msg_num)
+ lock = threading.Lock() # 锁,用于确保线程安全地写入 results
+
+ def task(db):
+ """
+ 每个线程执行的任务,获取某个数据库实例中的查询结果。
+ """
+ cursor = db.cursor()
+ try:
+ data = self._get_messages_by_username(cursor, username, time_range)
+ with lock: # 确保对 results 的操作是线程安全的
+ results.append(data)
+ finally:
+ cursor.close()
+
+ # 使用线程池
+ with ThreadPoolExecutor(max_workers=len(self.DB)) as executor:
+ executor.map(task, self.DB)
+ self.commit()
+ return results
+
+ def _get_messages_by_num(self, cursor, username, start_sort_seq, msg_num):
+ table_name = f'Msg_{hashlib.md5(username.encode("utf-8")).hexdigest()}'
+ if not self.table_exists(cursor, table_name):
+ return []
+ sql = f'''
+ select {BizMessageDB.columns}
+ from {table_name} as msg
+ join Name2Id on msg.real_sender_id = Name2Id.rowid
+ where sort_seq < ?
+ order by sort_seq desc
+ limit ?
+ '''
+ cursor.execute(sql, [start_sort_seq, msg_num])
+ result = cursor.fetchall()
+ if result:
+ return result
+ else:
+ return []
+
+ def get_message_by_server_id(self, username, server_id):
+ """
+ 获取小于start_sort_seq的msg_num个消息
+ @param username:
+ @param server_id:
+ @return: messages, 最后一条消息的start_sort_seq
+ """
+ table_name = f'Msg_{hashlib.md5(username.encode("utf-8")).hexdigest()}'
+ sql = f'''
+select {BizMessageDB.columns}
+from {table_name} as msg
+join Name2Id on msg.real_sender_id = Name2Id.rowid
+where server_id = ?
+'''
+ for db in self.DB:
+ cursor = db.cursor()
+ if not self.table_exists(cursor, table_name):
+ continue
+ cursor.execute(sql, [server_id])
+ result = cursor.fetchone()
+ if result:
+ return result
+
+ def get_messages_by_num(self, username, start_sort_seq, msg_num=20):
+ results = []
+ # for db in self.DB:
+ # cursor = db.cursor()
+ # yield self._get_messages_by_num(cursor, username, start_sort_seq, msg_num)
+ lock = threading.Lock() # 锁,用于确保线程安全地写入 results
+
+ def task(db):
+ """
+ 每个线程执行的任务,获取某个数据库实例中的查询结果。
+ """
+ cursor = db.cursor()
+ try:
+ data = self._get_messages_by_num(cursor, username, start_sort_seq, msg_num)
+ with lock: # 确保对 results 的操作是线程安全的
+ results.append(data)
+ finally:
+ cursor.close()
+
+ # 使用线程池
+ with ThreadPoolExecutor(max_workers=len(self.DB)) as executor:
+ executor.map(task, self.DB)
+ self.commit()
+ return results
+
+ def _get_messages_calendar(self, cursor, username):
+ """
+ 获取某个人的聊天日历列表
+ @param username_:
+ @return:
+ """
+ table_name = f'Msg_{hashlib.md5(username.encode("utf-8")).hexdigest()}'
+ if not self.table_exists(cursor, table_name):
+ return None
+ sql = f'''SELECT DISTINCT strftime('%Y-%m-%d',create_time,'unixepoch','localtime') AS date
+ from {table_name} as msg
+ ORDER BY date desc;
+ '''
+ cursor.execute(sql)
+ result = cursor.fetchall()
+ return (data[0] for data in result)
+
+ def get_messages_calendar(self, username):
+ res = []
+ for db in self.DB:
+ r1 = self._get_messages_calendar(db.cursor(), username)
+ if r1:
+ res.extend(r1)
+ res.sort()
+ return res
+
+ def _get_messages_by_type(self, cursor, username: str, type_: MessageType,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None, ):
+ table_name = f'Msg_{hashlib.md5(username.encode("utf-8")).hexdigest()}'
+ if not self.table_exists(cursor, table_name):
+ return None
+ if time_range:
+ start_time, end_time = convert_to_timestamp(time_range)
+ local_type = get_local_type(type_)
+ sql = f'''
+select {BizMessageDB.columns}
+from {table_name} as msg
+join Name2Id on msg.real_sender_id = Name2Id.rowid
+where local_type=? {'and create_time>' + str(start_time) + ' AND create_time<' + str(end_time) if time_range else ''}
+order by sort_seq
+ '''
+ cursor.execute(sql, [local_type])
+ result = cursor.fetchall()
+ if result:
+ return result
+ else:
+ return None
+
+ def get_messages_by_type(self, username: str, type_: MessageType,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None, ):
+ with concurrent.futures.ThreadPoolExecutor() as executor:
+ # 创建一个任务列表
+ futures = [
+ executor.submit(self._get_messages_by_type, db.cursor(), username, type_, time_range)
+ for db in self.DB
+ ]
+
+ # 等待所有任务完成,并获取结果
+ results = []
+ for future in concurrent.futures.as_completed(futures):
+ r1 = future.result()
+ if r1:
+ # results.append(future.result())
+ results.extend(r1)
+
+ return results
+
+ def merge(self, db_file_name):
+ def task_(db_path, cursor, db):
+ """
+ 每个线程执行的任务,获取某个数据库实例中的查询结果。
+ """
+ increase_data(db_path, cursor, db, 'Name2Id', 'user_name')
+ increase_update_data(db_path, cursor, db, 'TimeStamp', 'timestamp')
+ cursor.execute("SELECT name FROM sqlite_master WHERE type='table';")
+ result = cursor.fetchall()
+ # print(result)
+ if result:
+ for row in result:
+ table_name = row[0]
+ if table_name.startswith('Msg'):
+ increase_data(db_path, cursor, db, table_name, 'server_id', exclude_first_column=True)
+
+ tasks = []
+ for i in range(100):
+ db_path = db_file_name.replace('0', f'{i}')
+ if os.path.exists(db_path):
+ # print('初始化数据库:', db_path)
+ file_name = os.path.basename(db_path)
+ if file_name in self.db_file_name:
+ index = self.db_file_name.index(file_name)
+ db = self.DB[index]
+ cursor = db.cursor()
+ task_(db_path, cursor, db)
+ tasks.append([db_path, cursor, db])
+ else:
+ shutil.copy(db_path, os.path.join(self.db_dir, 'message'))
+ # print(tasks)
+ # 使用线程池 (没有加快合并速度)
+ # with ThreadPoolExecutor(max_workers=len(tasks)) as executor:
+ # executor.map(lambda args: task_(*args), tasks)
+ self.commit()
+ print(len(tasks))
diff --git a/wxManager/db_v4/contact.py b/wxManager/db_v4/contact.py
new file mode 100644
index 0000000..91d4bce
--- /dev/null
+++ b/wxManager/db_v4/contact.py
@@ -0,0 +1,152 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2024/12/5 22:47
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-contact.py
+@Description :
+"""
+import os
+import traceback
+
+from wxManager.merge import increase_update_data, increase_data
+from wxManager.model.db_model import DataBaseBase
+
+
+class ContactDB(DataBaseBase):
+ def create_index(self):
+ sql = "CREATE INDEX IF NOT EXISTS contact_username ON contact(username);"
+ try:
+ cursor = self.DB.cursor()
+ cursor.execute(sql)
+ self.commit()
+ cursor.close()
+ return True
+ except:
+ return False
+
+ def get_label_by_id(self, label_id) -> str:
+ sql = '''
+ select label_name_ from contact_label
+ where label_id_ = ?
+ '''
+ try:
+ cursor = self.DB.cursor()
+ cursor.execute(sql, [label_id])
+ result = cursor.fetchone()
+ if result:
+ return result[0]
+ else:
+ return ''
+ except:
+ return ''
+
+ def get_labels(self, label_id_list) -> str:
+ if not label_id_list:
+ return ''
+ return ','.join(map(self.get_label_by_id, label_id_list.strip(',').split(',')))
+
+ def get_contacts(self):
+ if not self.open_flag:
+ return []
+ self.create_index()
+ '''
+ @return:
+ a[0]:username
+ a[1]:alias
+ a[2]:local_type
+ a[3]:flag
+ a[4]:remark
+ a[5]:nick_name
+ a[6]:pin_yin_initial
+ a[7]:remark_pin_yin_initial
+ a[8]:small_head_url
+ a[9]:big_head_url
+ a[10]:extra_buffer
+ a[11]:head_img_md5
+ a[12]:
+ a[13]:
+ a[14]:
+ '''
+ sql = '''
+SELECT username, alias, local_type, flag, remark, nick_name, pin_yin_initial, remark_pin_yin_initial, small_head_url, big_head_url,extra_buffer,head_img_md5,chat_room_notify,is_in_chat_room,description,chat_room_type
+FROM contact
+WHERE (local_type=1 or local_type=2 or local_type=5)
+ORDER BY
+ CASE
+ WHEN remark_quan_pin = '' THEN quan_pin
+ ELSE remark_quan_pin
+ END ASC
+ '''
+ self.cursor.execute(sql)
+ results = self.cursor.fetchall()
+ self.DB.commit()
+ return results
+
+ def get_contact_by_username(self, username):
+ sql = '''
+SELECT username, alias, local_type,flag, remark, nick_name, pin_yin_initial, remark_pin_yin_initial, small_head_url, big_head_url,extra_buffer,head_img_md5,chat_room_notify,is_in_chat_room,description,chat_room_type
+FROM contact
+WHERE username=?
+ '''
+ cursor = self.DB.cursor()
+ cursor.execute(sql, [username])
+ result = cursor.fetchone()
+ cursor.close()
+ # self.commit()
+ if result:
+ return result
+ return None
+
+ def get_chatroom_info(self, username):
+ sql = '''
+select id,ext_buffer,username,owner
+from chat_room
+where username=?
+ '''
+ cursor = self.DB.cursor()
+ cursor.execute(sql, [username])
+ result = cursor.fetchone()
+ cursor.close()
+ if result:
+ return result
+ return None
+
+ def set_remark(self, username, remark):
+ if not remark:
+ return False
+ sql = '''
+ update contact
+ set remark=?
+ where username=?
+ '''
+ cursor = self.DB.cursor()
+ cursor.execute(sql, [remark, username])
+ cursor.close()
+ self.commit()
+ return True
+
+ def merge(self, db_path):
+ if not (os.path.exists(db_path) or os.path.isfile(db_path)):
+ print(f'{db_path} 不存在')
+ return
+ try:
+ # 获取列名
+ increase_update_data(db_path, self.cursor, self.DB, 'biz_info', 'username')
+ increase_update_data(db_path, self.cursor, self.DB, 'chat_room', 'username')
+ increase_update_data(db_path, self.cursor, self.DB, 'chat_room_info_detail', 'room_id_')
+ increase_update_data(db_path, self.cursor, self.DB, 'contact', 'username')
+ increase_update_data(db_path, self.cursor, self.DB, 'contact_label', 'label_id_')
+ increase_update_data(db_path, self.cursor, self.DB, 'openim_acct_type', 'lang_id')
+ increase_update_data(db_path, self.cursor, self.DB, 'openim_appid', 'lang_id')
+ # increase_update_data(db_path, self.cursor, self.DB, 'chat_room_member', 'room_id_')
+ increase_data(db_path, self.cursor, self.DB, 'name2id', 'username')
+ except:
+ print(f"数据库操作错误: {traceback.format_exc()}")
+ self.DB.rollback()
+
+
+if __name__ == '__main__':
+ pass
diff --git a/wxManager/db_v4/emotion.py b/wxManager/db_v4/emotion.py
new file mode 100644
index 0000000..24a3c86
--- /dev/null
+++ b/wxManager/db_v4/emotion.py
@@ -0,0 +1,55 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2024/12/12 18:10
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-emotion.py
+@Description :
+"""
+import os
+import traceback
+
+from wxManager.merge import increase_data
+from wxManager.model import DataBaseBase
+
+
+class EmotionDB(DataBaseBase):
+ def get_emoji_url(self, md5, thumb=False):
+ emoji_info = self._get_emoji_info(md5)
+ if emoji_info:
+ return emoji_info[1] if thumb else emoji_info[2]
+ else:
+ return ''
+
+ def _get_emoji_info(self, md5):
+ sql = '''
+ select aes_key,thumb_url,cdn_url
+ from kNonStoreEmoticonTable
+ where md5=?
+ '''
+ cursor = self.DB.cursor()
+ cursor.execute(sql, [md5])
+ result = cursor.fetchone()
+ if result:
+ return result
+ else:
+ return None
+
+ def merge(self, db_path):
+ if not (os.path.exists(db_path) or os.path.isfile(db_path)):
+ print(f'{db_path} 不存在')
+ return
+ try:
+ # 获取列名
+ increase_data(db_path, self.cursor, self.DB, 'kNonStoreEmoticonTable', 'md5')
+ increase_data(db_path, self.cursor, self.DB, 'kStoreEmoticonCaptionsTable', 'md5_')
+ increase_data(db_path, self.cursor, self.DB, 'kStoreEmoticonFilesTable', 'md5_')
+ increase_data(db_path, self.cursor, self.DB, 'kStoreEmoticonPackageTable', 'package_id_')
+ except:
+ print(f"数据库操作错误: {traceback.format_exc()}")
+ self.DB.rollback()
+
+if __name__ == '__main__':
+ pass
diff --git a/wxManager/db_v4/hardlink.py b/wxManager/db_v4/hardlink.py
new file mode 100644
index 0000000..8ed84e2
--- /dev/null
+++ b/wxManager/db_v4/hardlink.py
@@ -0,0 +1,277 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2024/12/8 17:30
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-hardlink.py
+@Description :
+"""
+import hashlib
+import os
+import traceback
+from lxml import etree
+
+from wxManager import Me
+from wxManager.merge import increase_data
+from wxManager.model.db_model import DataBaseBase
+from wxManager.log import logger
+from wxManager.model.message import Message
+from wxManager.parser.util.protocbuf import file_info_pb2
+from google.protobuf.json_format import MessageToJson, MessageToDict
+
+image_root_path = "msg\\attach\\"
+video_root_path = "msg\\video\\"
+file_root_path = "msg\\file\\"
+
+
+def get_md5_from_xml(content, type_="img"):
+ if not content:
+ return None
+ try:
+ content = content.strip('null:').strip().replace(' length="0" ', ' ') # 哪个天才在xml里写两个一样的字段 length="0"
+ # 解析XML
+ parser = etree.XMLParser(recover=True)
+ root = etree.fromstring(content, parser=parser)
+ if type_ == "img":
+ # 提取md5的值
+ md5_value = root.find(".//img").get("md5")
+ elif type_ == "video":
+ md5_value = root.find(".//videomsg").get("md5")
+ else:
+ md5_value = None
+ # print(md5_value)
+ return md5_value
+ except:
+ logger.error(traceback.format_exc())
+ logger.error(content)
+ return None
+
+
+class HardLinkDB(DataBaseBase):
+ def get_image_path(self):
+ pass
+
+ def create_index(self):
+ sql = "CREATE INDEX IF NOT EXISTS image_hardlink_info_v3_md5 ON image_hardlink_info_v3(md5);"
+ try:
+ cursor = self.DB.cursor()
+ cursor.execute(sql)
+ self.commit()
+ cursor.close()
+ except:
+ pass
+
+ sql = "CREATE INDEX IF NOT EXISTS video_hardlink_info_v3_md5 ON video_hardlink_info_v3(md5);"
+ try:
+ cursor = self.DB.cursor()
+ cursor.execute(sql)
+ self.commit()
+ cursor.close()
+ except:
+ pass
+
+ sql = "CREATE INDEX IF NOT EXISTS file_hardlink_info_v3_md5 ON file_hardlink_info_v3(md5);"
+ try:
+ cursor = self.DB.cursor()
+ cursor.execute(sql)
+ self.commit()
+ cursor.close()
+ except:
+ pass
+
+ def get_image_by_md5(self, md5: str):
+ sql = '''
+ select file_size,type,file_name,dir2id.username,dir2id2.username,_rowid_,modify_time,extra_buffer
+ from image_hardlink_info_v3
+ join dir2id on dir2id.rowid = dir1
+ join dir2id as dir2id2 on dir2id2.rowid=dir2
+ where md5=?
+ '''
+ cursor = self.DB.cursor()
+ cursor.execute(sql, [md5])
+ result = cursor.fetchall()
+ if result:
+ return result[0]
+ return None
+
+ def get_video_by_md5(self, md5: str):
+ sql = '''
+ SELECT file_size, type, file_name, dir2id.username, dir2id2.username, _rowid_, modify_time, extra_buffer
+ FROM video_hardlink_info_v3
+ JOIN dir2id ON dir2id.rowid = dir1
+ LEFT JOIN dir2id AS dir2id2 ON dir2id2.rowid = dir2 AND dir2 != 0
+ WHERE md5 = ?
+ '''
+ cursor = self.DB.cursor()
+ cursor.execute(sql, [md5])
+ result = cursor.fetchall()
+ if result:
+ return result[0]
+ return None
+
+ def get_file_by_md5(self, md5: str):
+ sql = '''
+ select file_size,type,file_name,dir2id.username,dir2id2.username,_rowid_,modify_time,extra_buffer
+ from file_hardlink_info_v3
+ join dir2id on dir2id.rowid = dir1
+ LEFT JOIN dir2id AS dir2id2 ON dir2id2.rowid = dir2 AND dir2 != 0
+ where md5=?
+ '''
+ cursor = self.DB.cursor()
+ cursor.execute(sql, [md5])
+ result = cursor.fetchall()
+ if result:
+ return result[0]
+ return None
+
+ def get_video(self, md5, thumb=False):
+ video_info = self.get_video_by_md5(md5)
+ if video_info:
+ type_ = video_info[1]
+ if type_ == 5:
+ dir1 = video_info[3]
+ dir2 = video_info[4]
+ extra_buffer = video_info[7]
+ # 创建顶级消息对象
+ message = file_info_pb2.FileInfoData()
+ # 解析二进制数据
+ message.ParseFromString(extra_buffer)
+ extra_dic = MessageToDict(message)
+ dir3 = extra_dic.get('dir3', '')
+ file_name = video_info[2]
+ result = os.path.join(video_root_path, dir1, dir2, 'Rec', dir3, 'V', file_name)
+ else:
+ dir1 = video_info[3]
+ data_image = video_info[2].split('.')[0] + '_thumb.jpg' if thumb else video_info[2]
+ dat_image = os.path.join(video_root_path, dir1, data_image)
+ result = dat_image
+ return result
+ return ''
+
+ def get_image_thumb(self, message: Message, talker_username):
+ """
+ @param message:
+ @param talker_username: 聊天对象的wxid
+ @return:
+ """
+ dir1 = hashlib.md5(talker_username.encode('utf-8')).hexdigest()
+ str_time = message.str_time
+ dir2 = str_time[:7] # 2024-12
+ dir0 = "Img"
+ local_id = message.local_id
+ create_time = message.timestamp
+ data_image = f'{message.file_name}_t.dat' if message.file_name else f'{local_id}_{create_time}_t.dat'
+ return os.path.join(image_root_path, dir1, dir2, dir0, data_image)
+
+ def get_image_by_time(self, message: Message, talker_username):
+ """
+ @param message:
+ @param talker_username: 聊天对象的wxid
+ @return:
+ """
+ dir1 = hashlib.md5(talker_username.encode('utf-8')).hexdigest()
+ str_time = message.str_time
+ dir2 = str_time[:7] # 2024-12
+ dir0 = "Img"
+ local_id = message.local_id
+ create_time = message.timestamp
+ data_image = f'{message.file_name}_W.dat' if message.file_name else f'{local_id}_{create_time}_W.dat'
+ path1 = os.path.join(image_root_path, dir1, dir2, dir0, data_image)
+ if os.path.exists(os.path.join(Me().wx_dir, path1)):
+ return path1
+ else:
+ data_image = f'{message.file_name}.dat' if message.file_name else f'{local_id}_{create_time}.dat'
+ path1 = os.path.join(image_root_path, dir1, dir2, dir0, data_image)
+ return path1
+
+ def get_image(self, content, message, up_dir="", md5=None, thumb=False, talker_username='') -> str:
+ """
+ @param content: image xml
+ @param message:
+ @param up_dir:
+ @param md5: image的md5
+ @param thumb: 是否是缩略图
+ @param talker_username: 聊天对象的wxid
+ @return:
+ """
+ result = '.'
+ self.create_index()
+ if thumb:
+ return self.get_image_thumb(message, talker_username)
+ else:
+ result = self.get_image_by_time(message, talker_username)
+ if os.path.exists(os.path.join(Me().wx_dir, result)):
+ return result
+ if not md5:
+ md5 = get_md5_from_xml(content)
+ if md5:
+ imginfo = self.get_image_by_md5(md5)
+ if imginfo:
+ type_ = imginfo[1]
+ if type_ == 4:
+ dir1 = imginfo[3]
+ dir2 = imginfo[4]
+ extra_buffer = imginfo[7]
+ # 创建顶级消息对象
+ message = file_info_pb2.FileInfoData()
+ # 解析二进制数据
+ message.ParseFromString(extra_buffer)
+ extra_dic = MessageToDict(message)
+ dir3 = extra_dic.get('dir3', '')
+ file_name = imginfo[2]
+ result = os.path.join(image_root_path, dir1, dir2, 'Rec', dir3, 'Img', file_name)
+ else:
+ dir1 = imginfo[3]
+ dir2 = imginfo[4]
+ data_image = imginfo[2]
+ dir0 = "Img"
+ dat_image = os.path.join(image_root_path, dir1, dir2, dir0, data_image)
+ result = dat_image
+ else:
+ result = self.get_image_thumb(message, talker_username)
+ else:
+ result = self.get_image_by_time(message, talker_username)
+ return result
+
+ def get_file(self, md5):
+ file_info = self.get_file_by_md5(md5)
+ if file_info:
+ type_ = file_info[1]
+ if type_ == 6:
+ dir1 = file_info[3]
+ dir2 = file_info[4]
+ extra_buffer = file_info[7]
+ # 创建顶级消息对象
+ message = file_info_pb2.FileInfoData()
+ # 解析二进制数据
+ message.ParseFromString(extra_buffer)
+ extra_dic = MessageToDict(message)
+ dir3 = extra_dic.get('dir3', '')
+ file_name = file_info[2]
+ filepath = os.path.join(image_root_path, dir1, dir2, dir3, file_name)
+ else:
+ dir1 = file_info[3]
+ filename = file_info[2]
+ filepath = os.path.join(file_root_path, dir1, filename)
+ return filepath
+ return ''
+
+ def merge(self, db_path):
+ if not (os.path.exists(db_path) or os.path.isfile(db_path)):
+ print(f'{db_path} 不存在')
+ return
+ try:
+ # 获取列名
+ increase_data(db_path, self.cursor, self.DB, 'file_hardlink_info_v3', 'md5')
+ increase_data(db_path, self.cursor, self.DB, 'image_hardlink_info_v3', 'md5')
+ increase_data(db_path, self.cursor, self.DB, 'video_hardlink_info_v3', 'md5')
+ increase_data(db_path, self.cursor, self.DB, 'dir2id', 'username')
+ except:
+ print(f"数据库操作错误: {traceback.format_exc()}")
+ self.DB.rollback()
+
+
+if __name__ == '__main__':
+ pass
diff --git a/wxManager/db_v4/head_image.py b/wxManager/db_v4/head_image.py
new file mode 100644
index 0000000..6760153
--- /dev/null
+++ b/wxManager/db_v4/head_image.py
@@ -0,0 +1,91 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2024/12/5 23:35
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-head_image.py
+@Description :
+"""
+import hashlib
+import io
+import os
+import time
+import traceback
+
+from PIL import Image
+
+from wxManager.merge import increase_update_data
+from wxManager.model.db_model import DataBaseBase
+from wxManager.log import logger
+
+
+class HeadImageDB(DataBaseBase):
+ def get_avatar_buffer(self, username):
+ if not self.open_flag:
+ return b''
+ sql = '''
+select image_buffer
+from head_image
+where username = ?
+ '''
+ cursor = self.DB.cursor()
+ cursor.execute(sql, [username])
+ result = cursor.fetchall()
+ cursor.close()
+ self.DB.commit()
+ if result:
+ return result[0][0]
+ else:
+ return b''
+
+ def set_avatar_buffer(self, username, img_path):
+ try:
+ # 打开图片并缩放
+ with Image.open(img_path) as img:
+ img = img.resize((128, 128))
+
+ # 将图片转换为二进制格式
+ img_byte_arr = io.BytesIO()
+ img.save(img_byte_arr, format='PNG') # 可以根据需要更改格式
+ img_binary = img_byte_arr.getvalue()
+ md5_hash = hashlib.md5()
+ md5_hash.update(img_binary)
+
+ update_sql = '''
+ UPDATE head_image
+ SET update_time = ?,image_buffer=?,md5=?
+ WHERE username = ?
+ '''
+ cursor = self.DB.cursor()
+ cursor.execute(update_sql, [int(time.time()), img_binary, username, md5_hash.hexdigest()])
+ # 检查是否有行被更新
+ if cursor.rowcount == 0:
+ # 如果没有更新,则插入新记录
+ insert_sql = '''
+ INSERT INTO head_image (username,md5, image_buffer,update_time)
+ VALUES (?, ?,?,?)
+ '''
+ cursor.execute(insert_sql, [username, md5_hash.hexdigest(), int(time.time()), img_binary])
+ cursor.close()
+ self.commit() # 提交更改
+ except:
+ logger.error(traceback.format_exc())
+ return False
+ return True
+
+ def merge(self, db_path):
+ if not (os.path.exists(db_path) or os.path.isfile(db_path)):
+ print(f'{db_path} 不存在')
+ return
+ try:
+ # 获取列名
+ increase_update_data(db_path, self.cursor, self.DB, 'head_image', 'username')
+ except:
+ print(f"数据库操作错误: {traceback.format_exc()}")
+ self.DB.rollback()
+
+
+if __name__ == '__main__':
+ pass
diff --git a/wxManager/db_v4/media.py b/wxManager/db_v4/media.py
new file mode 100644
index 0000000..bb93ca4
--- /dev/null
+++ b/wxManager/db_v4/media.py
@@ -0,0 +1,116 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2024/12/12 17:06
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-media.py
+@Description :
+"""
+import os
+import subprocess
+import sys
+import traceback
+
+from wxManager.merge import increase_update_data, increase_data
+from wxManager.model import DataBaseBase
+from wxManager.log import logger
+
+
+def get_ffmpeg_path():
+ # 获取打包后的资源目录
+ resource_dir = getattr(sys, '_MEIPASS', os.path.abspath(os.path.dirname(__file__)))
+
+ # 构建 FFmpeg 可执行文件的路径
+ ffmpeg_path = os.path.join(resource_dir, 'app', 'resources', 'data', 'ffmpeg.exe')
+
+ return ffmpeg_path
+
+
+class MediaDB(DataBaseBase):
+ def get_media_buffer(self, server_id) -> bytes:
+ sql = '''
+ select voice_data
+ from VoiceInfo
+ where svr_id = ?
+ '''
+ for db in self.DB:
+ cursor = db.cursor()
+ cursor.execute(sql, [server_id])
+ result = cursor.fetchone()
+ if result:
+ return result[0]
+ return b''
+
+ def get_audio_path(self, server_id, output_dir, filename=''):
+ if filename:
+ return f'{output_dir}/{filename}.mp3'
+ else:
+ return f'{output_dir}/{server_id}.mp3'
+
+ def get_audio(self, server_id, output_dir, filename=''):
+ if not filename:
+ filename = server_id
+ silk_path = f"{output_dir}/{filename}.silk"
+ pcm_path = f"{output_dir}/{filename}.pcm"
+ mp3_path = f"{output_dir}/{filename}.mp3"
+ if os.path.exists(mp3_path):
+ return mp3_path
+ buf = self.get_media_buffer(server_id)
+ if not buf:
+ return ''
+ with open(silk_path, "wb") as f:
+ f.write(buf)
+ # open(silk_path, "wb").write()
+ try:
+ decode(silk_path, pcm_path, 44100)
+ # 调用系统上的 ffmpeg 可执行文件
+ # 获取 FFmpeg 可执行文件的路径
+ ffmpeg_path = get_ffmpeg_path()
+ # # 调用 FFmpeg
+ if os.path.exists(ffmpeg_path):
+ cmd = f'''"{ffmpeg_path}" -loglevel quiet -y -f s16le -i "{pcm_path}" -ar 44100 -ac 1 "{mp3_path}"'''
+ # system(cmd)
+ # 使用subprocess.run()执行命令
+ subprocess.run(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
+ else:
+ # 源码运行的时候下面的有效
+ # 这里不知道怎么捕捉异常
+ cmd = f'''"{os.path.join(os.getcwd(), 'app', 'resources', 'data', 'ffmpeg.exe')}" -loglevel quiet -y -f s16le -i "{pcm_path}" -ar 44100 -ac 1 "{mp3_path}"'''
+ # system(cmd)
+ # 使用subprocess.run()执行命令
+ subprocess.run(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
+ if os.path.exists(silk_path):
+ os.remove(silk_path)
+ if os.path.exists(pcm_path):
+ os.remove(pcm_path)
+ except Exception as e:
+ print(f"Error: {e}")
+ logger.error(f'语音错误\n{traceback.format_exc()}')
+ cmd = f'''"{os.path.join(os.getcwd(), 'app', 'resources', 'data', 'ffmpeg.exe')}" -loglevel quiet -y -f s16le -i "{pcm_path}" -ar 44100 -ac 1 "{mp3_path}"'''
+ # system(cmd)
+ # 使用subprocess.run()执行命令
+ subprocess.run(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
+ finally:
+ return mp3_path
+
+ def merge(self, db_path):
+ # todo 判断数据库对应情况
+ if not (os.path.exists(db_path) or os.path.isfile(db_path)):
+ print(f'{db_path} 不存在')
+ return
+ for db in self.DB:
+ cursor = db.cursor()
+ try:
+ # 获取列名
+ increase_data(db_path, cursor, db, 'VoiceInfo', 'svr_id')
+ increase_data(db_path, cursor, db, 'Name2Id', 'user_name')
+ increase_update_data(db_path, cursor, db, 'Timestamp', 'timestamp')
+ except:
+ print(f"数据库操作错误: {traceback.format_exc()}")
+ db.rollback()
+
+
+if __name__ == '__main__':
+ pass
diff --git a/wxManager/db_v4/message.py b/wxManager/db_v4/message.py
new file mode 100644
index 0000000..62af58f
--- /dev/null
+++ b/wxManager/db_v4/message.py
@@ -0,0 +1,316 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2024/12/6 23:07
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-message.py
+@Description :
+"""
+import concurrent
+import hashlib
+import os
+import shutil
+import threading
+import traceback
+from concurrent.futures import ThreadPoolExecutor
+from datetime import date, datetime
+from typing import Tuple
+
+from wxManager import MessageType
+from wxManager.merge import increase_data, increase_update_data
+from wxManager.model.db_model import DataBaseBase
+
+
+def convert_to_timestamp_(time_input) -> int:
+ if isinstance(time_input, (int, float)):
+ # 如果输入是时间戳,直接返回
+ return int(time_input)
+ elif isinstance(time_input, str):
+ # 如果输入是格式化的时间字符串,将其转换为时间戳
+ try:
+ dt_object = datetime.strptime(time_input, '%Y-%m-%d %H:%M:%S')
+ return int(dt_object.timestamp())
+ except ValueError:
+ # 如果转换失败,可能是其他格式的字符串,可以根据需要添加更多的处理逻辑
+ print("Error: Unsupported date format")
+ return -1
+ elif isinstance(time_input, date):
+ # 如果输入是datetime.date对象,将其转换为时间戳
+ dt_object = datetime.combine(time_input, datetime.min.time())
+ return int(dt_object.timestamp())
+ else:
+ print("Error: Unsupported input type")
+ return -1
+
+
+def convert_to_timestamp(time_range) -> Tuple[int, int]:
+ """
+ 将时间转换成时间戳
+ @param time_range:
+ @return:
+ """
+ if not time_range:
+ return 0, 0
+ else:
+ return convert_to_timestamp_(time_range[0]), convert_to_timestamp_(time_range[1])
+
+
+def get_local_type(type_: MessageType):
+ return type_
+
+
+class MessageDB(DataBaseBase):
+ columns = (
+ "local_id,server_id,local_type,sort_seq,Name2Id.user_name as sender_username,create_time,strftime('%Y-%m-%d %H:%M:%S',"
+ "create_time,'unixepoch','localtime') as StrTime,status,upload_status,server_seq,origin_source,source,"
+ "message_content,compress_content,packed_info_data")
+
+ def get_messages(self):
+ pass
+
+ def table_exists(self, cursor, table_name):
+ # 查询 sqlite_master 系统表,判断表是否存在
+ cursor.execute("SELECT name FROM sqlite_master WHERE type='table' AND name=?;", (table_name,))
+ result = cursor.fetchone()
+ # 如果结果不为空,表存在;否则表不存在
+ return result
+
+ def _get_messages_by_username(self, cursor, username: str,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None, ):
+ table_name = f'Msg_{hashlib.md5(username.encode("utf-8")).hexdigest()}'
+ if not self.table_exists(cursor, table_name):
+ return None
+ if time_range:
+ start_time, end_time = convert_to_timestamp(time_range)
+ sql = f'''
+select {MessageDB.columns}
+from {table_name} as msg
+join Name2Id on msg.real_sender_id = Name2Id.rowid
+{'where create_time>' + str(start_time) + ' AND create_time<' + str(end_time) if time_range else ''}
+order by sort_seq
+ '''
+ cursor.execute(sql)
+ result = cursor.fetchall()
+ if result:
+ return result
+ else:
+ return None
+
+ def get_messages_by_username(self, username: str,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None, ):
+ with concurrent.futures.ThreadPoolExecutor() as executor:
+ # 创建一个任务列表
+ futures = [
+ executor.submit(self._get_messages_by_username, db.cursor(), username, time_range)
+ for db in self.DB
+ ]
+
+ # 等待所有任务完成,并获取结果
+ results = []
+ for future in concurrent.futures.as_completed(futures):
+ r1 = future.result()
+ if r1:
+ # results.append(future.result())
+ results.extend(r1)
+
+ return results
+ results = []
+ # for db in self.DB:
+ # cursor = db.cursor()
+ # yield self._get_messages_by_num(cursor, username, start_sort_seq, msg_num)
+ lock = threading.Lock() # 锁,用于确保线程安全地写入 results
+
+ def task(db):
+ """
+ 每个线程执行的任务,获取某个数据库实例中的查询结果。
+ """
+ cursor = db.cursor()
+ try:
+ data = self._get_messages_by_username(cursor, username, time_range)
+ with lock: # 确保对 results 的操作是线程安全的
+ results.append(data)
+ finally:
+ cursor.close()
+
+ # 使用线程池
+ with ThreadPoolExecutor(max_workers=len(self.DB)) as executor:
+ executor.map(task, self.DB)
+ self.commit()
+ return results
+
+ def _get_messages_by_num(self, cursor, username, start_sort_seq, msg_num):
+ table_name = f'Msg_{hashlib.md5(username.encode("utf-8")).hexdigest()}'
+ if not self.table_exists(cursor, table_name):
+ return []
+ sql = f'''
+ select {MessageDB.columns}
+ from {table_name} as msg
+ join Name2Id on msg.real_sender_id = Name2Id.rowid
+ where sort_seq < ?
+ order by sort_seq desc
+ limit ?
+ '''
+ cursor.execute(sql, [start_sort_seq, msg_num])
+ result = cursor.fetchall()
+ if result:
+ return result
+ else:
+ return []
+
+ def get_message_by_server_id(self, username, server_id):
+ """
+ 获取小于start_sort_seq的msg_num个消息
+ @param username:
+ @param server_id:
+ @return: messages, 最后一条消息的start_sort_seq
+ """
+ table_name = f'Msg_{hashlib.md5(username.encode("utf-8")).hexdigest()}'
+ sql = f'''
+select {MessageDB.columns}
+from {table_name} as msg
+join Name2Id on msg.real_sender_id = Name2Id.rowid
+where server_id = ?
+'''
+ for db in self.DB:
+ cursor = db.cursor()
+ if not self.table_exists(cursor, table_name):
+ continue
+ cursor.execute(sql, [server_id])
+ result = cursor.fetchone()
+ if result:
+ return result
+
+ def get_messages_by_num(self, username, start_sort_seq, msg_num=20):
+ results = []
+ # for db in self.DB:
+ # cursor = db.cursor()
+ # yield self._get_messages_by_num(cursor, username, start_sort_seq, msg_num)
+ lock = threading.Lock() # 锁,用于确保线程安全地写入 results
+
+ def task(db):
+ """
+ 每个线程执行的任务,获取某个数据库实例中的查询结果。
+ """
+ cursor = db.cursor()
+ try:
+ data = self._get_messages_by_num(cursor, username, start_sort_seq, msg_num)
+ with lock: # 确保对 results 的操作是线程安全的
+ results.append(data)
+ finally:
+ cursor.close()
+
+ # 使用线程池
+ with ThreadPoolExecutor(max_workers=len(self.DB)) as executor:
+ executor.map(task, self.DB)
+ self.commit()
+ return results
+
+ def _get_messages_calendar(self, cursor, username):
+ """
+ 获取某个人的聊天日历列表
+ @param username_:
+ @return:
+ """
+ table_name = f'Msg_{hashlib.md5(username.encode("utf-8")).hexdigest()}'
+ if not self.table_exists(cursor, table_name):
+ return None
+ sql = f'''SELECT DISTINCT strftime('%Y-%m-%d',create_time,'unixepoch','localtime') AS date
+ from {table_name} as msg
+ ORDER BY date desc;
+ '''
+ cursor.execute(sql)
+ result = cursor.fetchall()
+ return (data[0] for data in result)
+
+ def get_messages_calendar(self, username):
+ res = []
+ for db in self.DB:
+ r1 = self._get_messages_calendar(db.cursor(), username)
+ if r1:
+ res.extend(r1)
+ res.sort()
+ return res
+
+ def _get_messages_by_type(self, cursor, username: str, type_: MessageType,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None, ):
+ table_name = f'Msg_{hashlib.md5(username.encode("utf-8")).hexdigest()}'
+ if not self.table_exists(cursor, table_name):
+ return None
+ if time_range:
+ start_time, end_time = convert_to_timestamp(time_range)
+ local_type = get_local_type(type_)
+ sql = f'''
+select {MessageDB.columns}
+from {table_name} as msg
+join Name2Id on msg.real_sender_id = Name2Id.rowid
+where local_type=? {'and create_time>' + str(start_time) + ' AND create_time<' + str(end_time) if time_range else ''}
+order by sort_seq
+ '''
+ cursor.execute(sql, [local_type])
+ result = cursor.fetchall()
+ if result:
+ return result
+ else:
+ return None
+
+ def get_messages_by_type(self, username: str, type_: MessageType,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None, ):
+ with concurrent.futures.ThreadPoolExecutor() as executor:
+ # 创建一个任务列表
+ futures = [
+ executor.submit(self._get_messages_by_type, db.cursor(), username, type_, time_range)
+ for db in self.DB
+ ]
+
+ # 等待所有任务完成,并获取结果
+ results = []
+ for future in concurrent.futures.as_completed(futures):
+ r1 = future.result()
+ if r1:
+ # results.append(future.result())
+ results.extend(r1)
+
+ return results
+
+ def merge(self, db_file_name):
+ def task_(db_path, cursor, db):
+ """
+ 每个线程执行的任务,获取某个数据库实例中的查询结果。
+ """
+ increase_data(db_path, cursor, db, 'Name2Id', 'user_name')
+ increase_update_data(db_path, cursor, db, 'TimeStamp', 'timestamp')
+ cursor.execute("SELECT name FROM sqlite_master WHERE type='table';")
+ result = cursor.fetchall()
+ # print(result)
+ if result:
+ for row in result:
+ table_name = row[0]
+ if table_name.startswith('Msg'):
+ increase_data(db_path, cursor, db, table_name, 'server_id', exclude_first_column=True)
+
+ tasks = []
+ for i in range(100):
+ db_path = db_file_name.replace('0', f'{i}')
+ if os.path.exists(db_path):
+ # print('初始化数据库:', db_path)
+ file_name = os.path.basename(db_path)
+ if file_name in self.db_file_name:
+ index = self.db_file_name.index(file_name)
+ db = self.DB[index]
+ cursor = db.cursor()
+ task_(db_path, cursor, db)
+ tasks.append([db_path, cursor, db])
+ else:
+ shutil.copy(db_path, os.path.join(self.db_dir, 'Multi', file_name))
+ # print(tasks)
+ # 使用线程池 (没有加快合并速度)
+ # with ThreadPoolExecutor(max_workers=len(tasks)) as executor:
+ # executor.map(lambda args: task_(*args), tasks)
+ self.commit()
+ print(len(tasks))
+
+
+if __name__ == '__main__':
+ pass
diff --git a/wxManager/db_v4/session.py b/wxManager/db_v4/session.py
new file mode 100644
index 0000000..0c77b96
--- /dev/null
+++ b/wxManager/db_v4/session.py
@@ -0,0 +1,51 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2024/12/7 0:04
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-session.py
+@Description :
+"""
+import os
+import traceback
+
+from wxManager.merge import increase_update_data
+from wxManager.model.db_model import DataBaseBase
+
+
+class SessionDB(DataBaseBase):
+ def get_session(self):
+ if not self.open_flag:
+ return []
+ sql = '''
+select username, type, unread_count, unread_first_msg_srv_id,last_timestamp, summary,last_msg_type,last_msg_sub_type,strftime('%Y/%m/%d', last_timestamp, 'unixepoch','localtime') AS strTime,last_sender_display_name,last_msg_sender
+from SessionTable
+order by sort_timestamp desc
+ '''
+ self.cursor.execute(sql)
+ result = self.cursor.fetchall()
+ self.commit()
+ if result:
+ return result
+ else:
+ return []
+
+ def merge(self, db_path):
+ if not (os.path.exists(db_path) or os.path.isfile(db_path)):
+ print(f'{db_path} 不存在')
+ return
+ try:
+ # 获取列名
+ increase_update_data(db_path, self.cursor, self.DB, 'SessionTable', 'username')
+ except:
+ print(f"数据库操作错误: {traceback.format_exc()}")
+ self.DB.rollback()
+
+
+if __name__ == '__main__':
+ cd = SessionDB('session/session.db')
+ cd.init_database(r'E:\Project\Python\MemoTrace\app\DataBase\Msg\wxid_27hqbq7vx5hf22\db_storage')
+ r = cd.get_session()
+ print(r)
diff --git a/wxManager/decrypt/__init__.py b/wxManager/decrypt/__init__.py
new file mode 100644
index 0000000..a6aa8da
--- /dev/null
+++ b/wxManager/decrypt/__init__.py
@@ -0,0 +1,61 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2025/1/10 2:34
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : wxManager-__init__.py.py
+@Description :
+"""
+from typing import List
+
+import psutil
+
+from wxManager.decrypt.wx_info_v3 import dump_wechat_info_v3
+from wxManager.decrypt.wx_info_v4 import dump_wechat_info_v4
+from wxManager.decrypt.common import WeChatInfo
+
+
+def get_info_v4() -> List[WeChatInfo]:
+ result_v4 = []
+ for process in psutil.process_iter(['name', 'exe', 'pid']):
+ if process.name() == 'Weixin.exe':
+ wechat_base_address = 0
+ for module in process.memory_maps(grouped=False):
+ if module.path and 'Weixin.dll' in module.path:
+ wechat_base_address = int(module.addr, 16)
+ break
+ if wechat_base_address == 0:
+ continue
+ pid = process.pid
+ wxinfo = dump_wechat_info_v4(pid)
+ result_v4.append(
+ wxinfo
+ )
+ return result_v4
+
+
+def get_info_v3(version_list) -> List[WeChatInfo]:
+ result = []
+ for process in psutil.process_iter(['name', 'exe', 'pid']):
+ if process.name() == 'WeChat.exe':
+ pid = process.pid
+ wxinfo = dump_wechat_info_v3(version_list, pid)
+ result.append(
+ wxinfo
+ )
+ return result
+
+
+if __name__ == "__main__":
+ import json
+
+ file_path = r'E:\Project\Python\MemoTrace\resources\data\version_list.json'
+ with open(file_path, "r", encoding="utf-8") as f:
+ version_list = json.loads(f.read())
+
+ r_4 = get_info_v4()
+ r_3 = get_info_v3(version_list)
+ for wx_info in r_4+r_3:
+ print(wx_info)
\ No newline at end of file
diff --git a/wxManager/decrypt/common.py b/wxManager/decrypt/common.py
new file mode 100644
index 0000000..fb4c970
--- /dev/null
+++ b/wxManager/decrypt/common.py
@@ -0,0 +1,56 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2025/3/7 16:39
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-common.py
+@Description :
+"""
+import psutil
+import win32api
+
+if __name__ == '__main__':
+ pass
+
+
+def get_version(pid):
+ p = psutil.Process(pid)
+ version_info = win32api.GetFileVersionInfo(p.exe(), '\\')
+ version = f"{win32api.HIWORD(version_info['FileVersionMS'])}.{win32api.LOWORD(version_info['FileVersionMS'])}.{win32api.HIWORD(version_info['FileVersionLS'])}.{win32api.LOWORD(version_info['FileVersionLS'])}"
+ return version
+
+
+class WeChatInfo:
+ def __init__(self):
+ self.pid = 0
+ self.version = '0.0.0.0'
+ self.account_name = ''
+ self.nick_name = ''
+ self.phone = ''
+ self.wx_dir = ''
+ self.key = ''
+ self.wxid = ''
+ self.errcode: int = 404 # 405: 版本不匹配, 404: 重新登录微信, other: 未知错误
+ self.errmsg: str = '错误!请登录微信。'
+
+ def __str__(self):
+ return f'''
+pid: {self.pid}
+version: {self.version}
+account_name: {self.account_name}
+nickname: {self.nick_name}
+phone: {self.phone}
+wxid: {self.wxid}
+wx_dir: {self.wx_dir}
+key: {self.key}
+'''
+
+ def to_json(self):
+ return {
+ 'version': self.version,
+ 'nickname': self.nick_name,
+ 'wx_dir': self.wx_dir,
+ 'wxid': self.wxid
+ }
\ No newline at end of file
diff --git a/wxManager/decrypt/decrypt_dat.py b/wxManager/decrypt/decrypt_dat.py
new file mode 100644
index 0000000..a4e82a9
--- /dev/null
+++ b/wxManager/decrypt/decrypt_dat.py
@@ -0,0 +1,307 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2024/12/9 23:44
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : wxManager-decrypt_dat.py
+@Description :
+"""
+import os
+import struct
+from typing import List, Tuple
+from concurrent.futures import ProcessPoolExecutor
+from aiofiles import open as aio_open
+from aiofiles.os import makedirs
+
+from Crypto.Cipher import AES
+
+# 图片字节头信息,
+# [0][1]为jpg头信息,
+# [2][3]为png头信息,
+# [4][5]为gif头信息
+pic_head = (0xff, 0xd8, 0x89, 0x50, 0x47, 0x49)
+# 解密码
+decode_code = 0
+decode_code_v4 = -1
+
+
+def get_code(dat_read):
+ """
+ 自动判断文件类型,并获取dat文件解密码
+ :param file_path: dat文件路径
+ :return: 如果文件为jpg/png/gif格式,则返回解密码,否则返回-1
+ """
+ try:
+ if not dat_read:
+ return -1, -1
+ head_index = 0
+ while head_index < len(pic_head):
+ # 使用第一个头信息字节来计算加密码
+ # 第二个字节来验证解密码是否正确
+ code = dat_read[0] ^ pic_head[head_index]
+ idf_code = dat_read[1] ^ code
+ head_index = head_index + 1
+ if idf_code == pic_head[head_index]:
+ return head_index, code
+ head_index = head_index + 1
+ print("not jpg, png, gif")
+ return -1, -1
+ except:
+ return -1, -1
+
+
+def decode_dat(xor_key: int, file_path, out_path, dst_name='') -> str | bytes:
+ """
+ 解密文件,并生成图片
+ @param file_path: 输入文件路径
+ @param out_path: 输出文件文件夹
+ @param dst_name: 输出文件名
+ :param xor_key: 异或加密密钥
+ """
+ if not os.path.exists(file_path) or os.path.isdir(file_path):
+ return ''
+ if not os.path.exists(out_path):
+ os.makedirs(out_path, exist_ok=True)
+ if not os.path.isdir(out_path):
+ return ''
+ # print(file_path,out_path,dst_name)
+ with open(file_path, 'rb') as file_in:
+ data = file_in.read(0xf)
+ if data.startswith(b'\x07\x08V1\x08\x07'):
+ # 微信4.0
+ return decode_dat_v4(xor_key, file_path, out_path, dst_name)
+
+ with open(file_path, 'rb') as file_in:
+ data = file_in.read(2)
+ file_type, decode_code = get_code(data)
+ if decode_code == -1:
+ return ''
+
+ filename = os.path.basename(file_path)[:-4] if not dst_name else dst_name
+ if file_type == 1:
+ pic_name = filename + ".jpg"
+ elif file_type == 3:
+ pic_name = filename + ".png"
+ elif file_type == 5:
+ pic_name = filename + ".gif"
+ else:
+ pic_name = filename + ".jpg"
+
+ file_outpath = os.path.join(out_path, pic_name)
+ if os.path.exists(file_outpath):
+ return file_outpath
+
+ # 分块读取和写入
+ buffer_size = 1024 # 定义缓冲区大小
+ with open(file_outpath, 'wb') as file_out:
+ file_out.write(bytes([byte ^ decode_code for byte in data]))
+ while True:
+ data = file_in.read(buffer_size)
+ if not data:
+ break
+ file_out.write(bytes([byte ^ decode_code for byte in data]))
+
+ # print(os.path.basename(file_outpath))
+ return file_outpath
+
+
+def get_decode_code_v4(wx_dir):
+ cache_dir = os.path.join(wx_dir, 'cache')
+ if not os.path.isdir(wx_dir) or not os.path.exists(cache_dir):
+ raise ValueError(f'微信路径输入错误,请检查:{wx_dir}')
+ ok_flag = False
+ for root, dirs, files in os.walk(cache_dir):
+ if ok_flag:
+ break
+ for file in files:
+ if file.endswith(".dat"):
+ # 构造源文件和目标文件的完整路径
+ src_file_path = os.path.join(root, file)
+ with open(src_file_path, 'rb') as f:
+ data = f.read()
+ if not data.startswith(b'\x07\x08V1\x08\x07'):
+ continue
+ file_tail = data[-2:]
+
+ jpg_known_tail = b'\xff\xd9'
+ # 推导出密钥
+ xor_key = [c ^ p for c, p in zip(file_tail, jpg_known_tail)]
+ if len(set(xor_key)) == 1:
+ print(f'[*] 找到异或密钥: 0x{xor_key[0]:x}')
+ return xor_key[0]
+ return -1
+
+
+def get_image_type(data: bytes) -> str:
+ """
+ 根据文件头字节判断图片类型
+ :param data: 文件头数据(通常至少需要前 10 个字节)
+ :return: 图片类型(扩展名),默认为 'bin'
+ """
+ if data.startswith(b'\xff\xd8\xff'):
+ return 'jpg' # JPEG 文件
+ elif data.startswith(b'\x89PNG\r\n\x1a\n'):
+ return 'png' # PNG 文件
+ elif data.startswith(b'GIF87a') or data.startswith(b'GIF89a'):
+ return 'gif' # GIF 文件
+ elif data.startswith(b'BM'):
+ return 'bmp' # BMP 文件
+ elif data.startswith(b'II*\x00') or data.startswith(b'MM\x00*'):
+ return 'tiff' # TIFF 文件
+ elif data.startswith(b'RIFF') and data[8:12] == b'WEBP':
+ return 'webp' # WEBP 文件
+ elif data.startswith(b'\x00\x00\x01\x00'):
+ return 'ico' # ICO 文件
+ else:
+ return 'bin' # 未知类型,返回二进制
+
+
+def decode_dat_v4(xor_key: int, file_path, out_path, dst_name='') -> str | bytes:
+ """
+ 适用于微信4.0图片.dat,解密文件,并生成图片
+ :param xor_key: int 异或密钥
+ :param file_path: dat文件路径
+ :param out_path: 输出文件夹
+ :param dst_name: 输出文件名,默认为输入文件名
+ :return:
+ """
+
+ if not os.path.exists(file_path) or os.path.isdir(file_path):
+ return ''
+
+ # 读取加密文件的内容
+ with open(file_path, 'rb') as f:
+ header = f.read(0xf)
+ encrypt_length = struct.unpack_from('
str:
+ """
+ 异步版本的微信4.0图片 .dat 文件解密器
+ :param xor_key: int 异或密钥
+ :param file_path: .dat 文件路径
+ :param out_path: 输出文件夹
+ :param dst_name: 输出文件名,默认为输入文件名
+ :return: 解密后的文件路径
+ """
+ if not os.path.exists(file_path):
+ return ''
+
+ # 确保输出目录存在
+ await makedirs(out_path, exist_ok=True)
+
+ # 读取加密文件的内容
+ async with aio_open(file_path, 'rb') as f:
+ header = await f.read(0xf)
+ encrypt_length = struct.unpack_from('' + out_path)
+ return False, 'error'
+ salt = blist[:16]
+ byteKey = hashlib.pbkdf2_hmac("sha1", password, salt, DEFAULT_ITER, KEY_SIZE)
+ first = blist[16:DEFAULT_PAGESIZE]
+ if len(salt) != 16:
+ return False, f"[-] db_path:'{db_path}' File Error!"
+
+ mac_salt = bytes([(salt[i] ^ 58) for i in range(16)])
+ mac_key = hashlib.pbkdf2_hmac("sha1", byteKey, mac_salt, 2, KEY_SIZE)
+ hash_mac = hmac.new(mac_key, first[:-32], hashlib.sha1)
+ hash_mac.update(b'\x01\x00\x00\x00')
+
+ if hash_mac.digest() != first[-32:-12]:
+ return False, f"[-] Key Error! (db_path:'{db_path}' )"
+
+ newblist = [blist[i:i + DEFAULT_PAGESIZE] for i in range(DEFAULT_PAGESIZE, len(blist), DEFAULT_PAGESIZE)]
+
+ with open(out_path, "wb") as deFile:
+ deFile.write(SQLITE_FILE_HEADER.encode())
+ t = AES.new(byteKey, AES.MODE_CBC, first[-48:-32])
+ decrypted = t.decrypt(first[:-48])
+ deFile.write(decrypted)
+ deFile.write(first[-48:])
+
+ for i in newblist:
+ t = AES.new(byteKey, AES.MODE_CBC, i[-48:-32])
+ decrypted = t.decrypt(i[:-48])
+ deFile.write(decrypted)
+ deFile.write(i[-48:])
+ return True, [db_path, out_path, key]
+
+
+def decrypt_db_files(key, src_dir: str, dest_dir: str):
+ if not os.path.exists(src_dir):
+ print(f"源文件夹 {src_dir} 不存在")
+ return
+
+ if not os.path.exists(dest_dir):
+ os.makedirs(dest_dir) # 如果目标文件夹不存在,创建它
+
+ for root, dirs, files in os.walk(src_dir):
+ for file in files:
+ if file.endswith(".db"):
+ # 构造源文件和目标文件的完整路径
+ src_file_path = os.path.join(root, file)
+
+ # 计算目标路径,保持子文件夹结构
+ relative_path = os.path.relpath(root, src_dir)
+ dest_sub_dir = os.path.join(dest_dir, relative_path)
+ dest_file_path = os.path.join(dest_sub_dir, file)
+
+ # 确保目标子文件夹存在
+ if not os.path.exists(dest_sub_dir):
+ os.makedirs(dest_sub_dir)
+ print(dest_file_path)
+ decrypt_db_file_v3(key, src_file_path, dest_file_path)
diff --git a/wxManager/decrypt/decrypt_v4.py b/wxManager/decrypt/decrypt_v4.py
new file mode 100644
index 0000000..aa5505f
--- /dev/null
+++ b/wxManager/decrypt/decrypt_v4.py
@@ -0,0 +1,127 @@
+import hmac
+import os
+import struct
+from Crypto.Cipher import AES
+from Crypto.Protocol.KDF import PBKDF2
+from Crypto.Hash import SHA512
+
+# Constants
+IV_SIZE = 16
+HMAC_SHA256_SIZE = 64
+KEY_SIZE = 32
+AES_BLOCK_SIZE = 16
+ROUND_COUNT = 256000
+PAGE_SIZE = 4096
+SALT_SIZE = 16
+SQLITE_HEADER = b"SQLite format 3"
+
+
+def decrypt_db_file_v4(pkey, in_db_path, out_db_path):
+ if not os.path.exists(in_db_path):
+ print(f"【!!!】{in_db_path} does not exist.")
+ return False
+
+ with open(in_db_path, 'rb') as f_in, open(out_db_path, 'wb') as f_out:
+ # Read salt from the first SALT_SIZE bytes
+ salt = f_in.read(SALT_SIZE)
+ if not salt:
+ print("File is empty or corrupted.")
+ return False
+
+ mac_salt = bytes(x ^ 0x3a for x in salt)
+
+ # Convert pkey from hex to bytes
+ passphrase = bytes.fromhex(pkey)
+
+ # Use PBKDF2 to derive key and mac_key
+ key = PBKDF2(passphrase, salt, dkLen=KEY_SIZE, count=ROUND_COUNT, hmac_hash_module=SHA512)
+ mac_key = PBKDF2(key, mac_salt, dkLen=KEY_SIZE, count=2, hmac_hash_module=SHA512)
+
+ # Write SQLITE_HEADER to the output file
+ f_out.write(SQLITE_HEADER)
+ f_out.write(b'\x00')
+
+ # Reserve space for IV_SIZE + HMAC_SHA256_SIZE, rounded to a multiple of AES_BLOCK_SIZE
+ reserve = IV_SIZE + HMAC_SHA256_SIZE
+ reserve = ((reserve + AES_BLOCK_SIZE - 1) // AES_BLOCK_SIZE) * AES_BLOCK_SIZE
+
+ # Process each page
+ cur_page = 0
+ while True:
+
+ # For the first page, include SALT_SIZE adjustment
+ if cur_page == 0:
+ # Read one full PAGE_SIZE starting from after the salt
+ page = f_in.read(PAGE_SIZE - SALT_SIZE)
+ if not page:
+ break # No more data
+ page = salt + page # Include the salt in the first page data
+ else:
+ page = f_in.read(PAGE_SIZE)
+ if not page:
+ break # End of file
+ # print(f'第{cur_page + 1}页')
+ offset = SALT_SIZE if cur_page == 0 else 0
+ end = len(page)
+
+ # If the page is all zero bytes, append it directly and exit
+ if all(x == 0 for x in page):
+ f_out.write(page)
+ print("Exiting early due to zeroed page.")
+ break
+
+ # Perform HMAC check
+ mac = hmac.new(mac_key, page[offset:end - reserve + IV_SIZE], SHA512)
+ mac.update(struct.pack(' 2 ** 32 else 0x7fff0000
+ while next_region < user_space_limit:
+ try:
+ next_region, page_found = pymem.pattern.scan_pattern_page(
+ handle,
+ next_region,
+ pattern,
+ return_multiple=return_multiple
+ )
+ except Exception as e:
+ print(e)
+ break
+ if not return_multiple and page_found:
+ return page_found
+ if page_found:
+ found += page_found
+ if len(found) > find_num:
+ break
+ return found
+
+
+def get_info_wxid(h_process):
+ find_num = 100
+ addrs = pattern_scan_all(h_process, br'\\Msg\\FTSContact', return_multiple=True, find_num=find_num)
+ wxids = []
+ for addr in addrs:
+ array = ctypes.create_string_buffer(80)
+ if ReadProcessMemory(h_process, void_p(addr - 30), array, 80, 0) == 0: return "None"
+ array = bytes(array) # .split(b"\\")[0]
+ array = array.split(b"\\Msg")[0]
+ array = array.split(b"\\")[-1]
+ wxids.append(array.decode('utf-8', errors='ignore'))
+ wxid = max(wxids, key=wxids.count) if wxids else "None"
+ return wxid
+
+
+def get_wx_dir(wxid):
+ if not wxid:
+ return ''
+ try:
+ is_w_dir = False
+ try:
+ key = winreg.OpenKey(winreg.HKEY_CURRENT_USER, r"Software\Tencent\WeChat", 0, winreg.KEY_READ)
+ value, _ = winreg.QueryValueEx(key, "FileSavePath")
+ winreg.CloseKey(key)
+ w_dir = value
+ is_w_dir = True
+ except Exception as e:
+ w_dir = "MyDocument:"
+
+ if not is_w_dir:
+ try:
+ user_profile = os.environ.get("USERPROFILE")
+ path_3ebffe94 = os.path.join(user_profile, "AppData", "Roaming", "Tencent", "WeChat", "All Users",
+ "config",
+ "3ebffe94.ini")
+ with open(path_3ebffe94, "r", encoding="utf-8") as f:
+ w_dir = f.read()
+ is_w_dir = True
+ except Exception as e:
+ w_dir = "MyDocument:"
+
+ if w_dir == "MyDocument:":
+ try:
+ # 打开注册表路径
+ key = winreg.OpenKey(winreg.HKEY_CURRENT_USER,
+ r"Software\Microsoft\Windows\CurrentVersion\Explorer\User Shell Folders")
+ documents_path = winreg.QueryValueEx(key, "Personal")[0] # 读取文档实际目录路径
+ winreg.CloseKey(key) # 关闭注册表
+ documents_paths = os.path.split(documents_path)
+ if "%" in documents_paths[0]:
+ w_dir = os.environ.get(documents_paths[0].replace("%", ""))
+ w_dir = os.path.join(w_dir, os.path.join(*documents_paths[1:]))
+ # print(1, w_dir)
+ else:
+ w_dir = documents_path
+ except Exception as e:
+ profile = os.environ.get("USERPROFILE")
+ w_dir = os.path.join(profile, "Documents")
+ msg_dir = os.path.join(w_dir, "WeChat Files", wxid)
+ return msg_dir
+ except FileNotFoundError:
+ return ''
+
+
+def get_key(db_path, addr_len):
+ def read_key_bytes(h_process, address, address_len=8):
+ array = ctypes.create_string_buffer(address_len)
+ if ReadProcessMemory(h_process, void_p(address), array, address_len, 0) == 0: return "None"
+ address = int.from_bytes(array, byteorder='little') # 逆序转换为int地址(key地址)
+ key = ctypes.create_string_buffer(32)
+ if ReadProcessMemory(h_process, void_p(address), key, 32, 0) == 0: return "None"
+ key_bytes = bytes(key)
+ return key_bytes
+
+ def verify_key(key, wx_db_path):
+ if not wx_db_path or wx_db_path.lower() == "none":
+ return True
+ KEY_SIZE = 32
+ DEFAULT_PAGESIZE = 4096
+ DEFAULT_ITER = 64000
+ with open(wx_db_path, "rb") as file:
+ blist = file.read(5000)
+ salt = blist[:16]
+ byteKey = hashlib.pbkdf2_hmac("sha1", key, salt, DEFAULT_ITER, KEY_SIZE)
+ first = blist[16:DEFAULT_PAGESIZE]
+
+ mac_salt = bytes([(salt[i] ^ 58) for i in range(16)])
+ mac_key = hashlib.pbkdf2_hmac("sha1", byteKey, mac_salt, 2, KEY_SIZE)
+ hash_mac = hmac.new(mac_key, first[:-32], hashlib.sha1)
+ hash_mac.update(b'\x01\x00\x00\x00')
+
+ if hash_mac.digest() != first[-32:-12]:
+ return False
+ return True
+
+ phone_type1 = "iphone\x00"
+ phone_type2 = "android\x00"
+ phone_type3 = "ipad\x00"
+
+ pm = pymem.Pymem("WeChat.exe")
+ module_name = "WeChatWin.dll"
+
+ MicroMsg_path = os.path.join(db_path, "MSG", "MicroMsg.db")
+
+ type1_addrs = pm.pattern_scan_module(phone_type1.encode(), module_name, return_multiple=True)
+ type2_addrs = pm.pattern_scan_module(phone_type2.encode(), module_name, return_multiple=True)
+ type3_addrs = pm.pattern_scan_module(phone_type3.encode(), module_name, return_multiple=True)
+ type_addrs = type1_addrs if len(type1_addrs) >= 2 else type2_addrs if len(type2_addrs) >= 2 else type3_addrs if len(
+ type3_addrs) >= 2 else "None"
+ # print(type_addrs)
+ if type_addrs == "None":
+ return "None"
+ for i in type_addrs[::-1]:
+ for j in range(i, i - 2000, -addr_len):
+ key_bytes = read_key_bytes(pm.process_handle, j, addr_len)
+ if key_bytes == "None":
+ continue
+ if db_path != "None" and verify_key(key_bytes, MicroMsg_path):
+ return key_bytes.hex()
+ return "None"
+
+
+# 读取微信信息(account,mobile,name,mail,wxid,key)
+def read_info(version_list):
+ result = []
+ default_res = {
+ 'wxid': '',
+ 'name': '',
+ 'account': '',
+ 'key': '',
+ 'mobile': '',
+ 'version': '',
+ 'wx_dir': '',
+ 'errcode': 404,
+ 'errmsg': '错误!请登录微信。'
+ }
+ error = ""
+ for process in psutil.process_iter(['name', 'exe', 'pid']):
+ if process.name() == 'WeChat.exe':
+ tmp_rd = {}
+ pythoncom.CoInitialize()
+ tmp_rd['pid'] = process.pid
+ try:
+ tmp_rd['version'] = Dispatch("Scripting.FileSystemObject").GetFileVersion(process.exe())
+ except:
+ try:
+ tmp_rd['version'] = get_version(process.pid)
+ except:
+ tmp_rd['version'] = '3'
+ wechat_base_address = 0
+ for module in process.memory_maps(grouped=False):
+ if module.path and 'WeChatWin.dll' in module.path:
+ wechat_base_address = int(module.addr, 16)
+ break
+ if wechat_base_address == 0:
+ error = f"[-] WeChat WeChatWin.dll Not Found"
+ default_res['errmsg'] = '错误!请登录微信。'
+ return [default_res]
+
+ Handle = ctypes.windll.kernel32.OpenProcess(0x1F0FFF, False, process.pid)
+
+ bias_list = version_list.get(tmp_rd['version'])
+ if not isinstance(bias_list, list) or len(bias_list) <= 4:
+ default_res['version'] = tmp_rd['version']
+ default_res['errcode'] = 405
+ default_res['errmsg'] = '错误!微信版本不匹配,请手动填写信息。'
+ return [default_res]
+ else:
+ name_base_address = wechat_base_address + bias_list[0]
+ account__base_address = wechat_base_address + bias_list[1]
+ mobile_base_address = wechat_base_address + bias_list[2]
+ mail_base_address = wechat_base_address + bias_list[3]
+ # key_base_address = wechat_base_address + bias_list[4]
+
+ tmp_rd['account'] = get_info_without_key(Handle, account__base_address, 32) if bias_list[1] != 0 else "None"
+ tmp_rd['mobile'] = get_info_without_key(Handle, mobile_base_address, 64) if bias_list[2] != 0 else "None"
+ tmp_rd['name'] = get_info_without_key(Handle, name_base_address, 64) if bias_list[0] != 0 else "None"
+ tmp_rd['mail'] = get_info_without_key(Handle, mail_base_address, 64) if bias_list[3] != 0 else "None"
+
+ addrLen = get_exe_bit(process.exe()) // 8
+
+ tmp_rd['wxid'] = get_info_wxid(Handle)
+ tmp_rd['wx_dir'] = get_wx_dir(tmp_rd['wxid']) if tmp_rd['wxid'] != "None" else "None"
+ tmp_rd['key'] = "None"
+ tmp_rd['key'] = get_key(tmp_rd['wx_dir'], addrLen)
+ if tmp_rd['key'] == 'None':
+ tmp_rd['errcode'] = 404
+ tmp_rd['errmsg'] = '请重启微信后重试。'
+ else:
+ tmp_rd['errcode'] = 200
+ result.append(tmp_rd)
+ return result
+
+
+def get_info_v4():
+ result_v4 = []
+ for process in psutil.process_iter(['name', 'exe', 'pid']):
+ if process.name() == 'Weixin.exe':
+ wechat_base_address = 0
+ for module in process.memory_maps(grouped=False):
+ if module.path and 'Weixin.dll' in module.path:
+ wechat_base_address = int(module.addr, 16)
+ break
+ if wechat_base_address == 0:
+ continue
+ pid = process.pid
+ wxinfo = dump_wechat_info_v4(pid)
+ result_v4.append(
+ {
+ 'wxid': wxinfo.wxid,
+ 'name': wxinfo.nick_name,
+ 'account': wxinfo.account_name,
+ 'key': wxinfo.key,
+ 'mobile': wxinfo.phone,
+ 'version': wxinfo.version,
+ 'wx_dir': wxinfo.wx_dir,
+ 'errcode': 200
+ }
+ )
+ return result_v4
+
+
+def get_info_v3(version_list):
+ return read_info(version_list) # 读取微信信息
+
+
+def get_info(version_list):
+ result_v3 = read_info(version_list) # 读取微信信息
+ result_v4 = get_info_v4()
+ print(result_v3 + result_v4)
+ return result_v3 + result_v4
+
+
+if __name__ == "__main__":
+ import json
+
+ file_path = r'E:\Project\Python\MemoTrace\resources\data\version_list.json'
+ with open(file_path, "r", encoding="utf-8") as f:
+ version_list = json.loads(f.read())
+ wx_info = get_info_v3(version_list)
+ print(wx_info)
diff --git a/app/resources/data/version_list.json b/wxManager/decrypt/version_list.json
similarity index 94%
rename from app/resources/data/version_list.json
rename to wxManager/decrypt/version_list.json
index 0fb952d..d09e60a 100644
--- a/app/resources/data/version_list.json
+++ b/wxManager/decrypt/version_list.json
@@ -1076,5 +1076,68 @@
94516520,
0,
94517984
+ ],
+ "3.9.12.31": [
+ 94518242,
+ 94518240,
+ 94516712,
+ 0,
+ 0
+ ],
+ "3.9.12.35": [
+ 94516904,
+ 94518240,
+ 94516712,
+ 0,
+ 94518176
+ ],
+ "3.9.12.37": [
+ 94520808,
+ 94522144,
+ 94520616,
+ 0,
+ 94522080
+ ],
+ "3.9.5.22": [
+ 61549552,
+ 61549552,
+ 61525640,
+ 0,
+ 0
+ ],
+ "3.9.2.20": [
+ 50292048,
+ 50292976,
+ 50291904,
+ 0,
+ 0
+ ],
+ "3.9.12.41": [
+ 94499560,
+ 0,
+ 94499368,
+ 0,
+ 94500832
+ ],
+ "3.9.12.45": [
+ 94503784,
+ 94505120,
+ 94503592,
+ 0,
+ 94505056
+ ],
+ "3.9.12.44": [
+ 70639072,
+ 70640040,
+ 70638928,
+ 0,
+ 0
+ ],
+ "3.9.12.51": [
+ 94555176,
+ 94556512,
+ 94554984,
+ 0,
+ 94556448
]
}
\ No newline at end of file
diff --git a/wxManager/decrypt/wx_info_v3.py b/wxManager/decrypt/wx_info_v3.py
new file mode 100644
index 0000000..6d9ecee
--- /dev/null
+++ b/wxManager/decrypt/wx_info_v3.py
@@ -0,0 +1,263 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2025/3/7 16:30
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-wx_info_v3.py
+@Description :
+"""
+
+# -*- coding: utf-8 -*-#
+# -------------------------------------------------------------------------------
+# Name: getwxinfo.py
+# Description:
+# Author: xaoyaoo
+# Date: 2023/08/21
+# -------------------------------------------------------------------------------
+
+import os
+import sys
+import hmac
+import hashlib
+import ctypes
+import winreg
+import pymem
+import pythoncom
+import psutil
+import pymem.process
+
+from wxManager.decrypt.common import WeChatInfo
+from wxManager.decrypt.common import get_version
+
+ReadProcessMemory = ctypes.windll.kernel32.ReadProcessMemory
+void_p = ctypes.c_void_p
+
+
+def get_exe_bit(file_path):
+ try:
+ with open(file_path, 'rb') as f:
+ dos_header = f.read(2)
+ if dos_header != b'MZ':
+ print('get exe bit error: Invalid PE file')
+ return 64
+ # Seek to the offset of the PE signature
+ f.seek(60)
+ pe_offset_bytes = f.read(4)
+ pe_offset = int.from_bytes(pe_offset_bytes, byteorder='little')
+
+ # Seek to the Machine field in the PE header
+ f.seek(pe_offset + 4)
+ machine_bytes = f.read(2)
+ machine = int.from_bytes(machine_bytes, byteorder='little')
+
+ if machine == 0x14c:
+ return 32
+ elif machine == 0x8664:
+ return 64
+ else:
+ return 64
+ except:
+ return 64
+
+
+def get_info_without_key(h_process, address, n_size=64):
+ array = ctypes.create_string_buffer(n_size)
+ if ReadProcessMemory(h_process, void_p(address), array, n_size, 0) == 0: return "None"
+ array = bytes(array).split(b"\x00")[0] if b"\x00" in array else bytes(array)
+ text = array.decode('utf-8', errors='ignore')
+ return text.strip() if text.strip() != "" else "None"
+
+
+def pattern_scan_all(handle, pattern, *, return_multiple=False, find_num=100):
+ next_region = 0
+ found = []
+ user_space_limit = 0x7FFFFFFF0000 if sys.maxsize > 2 ** 32 else 0x7fff0000
+ while next_region < user_space_limit:
+ try:
+ next_region, page_found = pymem.pattern.scan_pattern_page(
+ handle,
+ next_region,
+ pattern,
+ return_multiple=return_multiple
+ )
+ except Exception as e:
+ print(e)
+ break
+ if not return_multiple and page_found:
+ return page_found
+ if page_found:
+ found += page_found
+ if len(found) > find_num:
+ break
+ return found
+
+
+def get_info_wxid(h_process):
+ find_num = 100
+ addrs = pattern_scan_all(h_process, br'\\Msg\\FTSContact', return_multiple=True, find_num=find_num)
+ wxids = []
+ for addr in addrs:
+ array = ctypes.create_string_buffer(80)
+ if ReadProcessMemory(h_process, void_p(addr - 30), array, 80, 0) == 0: return "None"
+ array = bytes(array) # .split(b"\\")[0]
+ array = array.split(b"\\Msg")[0]
+ array = array.split(b"\\")[-1]
+ wxids.append(array.decode('utf-8', errors='ignore'))
+ wxid = max(wxids, key=wxids.count) if wxids else "None"
+ return wxid
+
+
+def get_wx_dir(wxid):
+ if not wxid:
+ return ''
+ try:
+ is_w_dir = False
+ try:
+ key = winreg.OpenKey(winreg.HKEY_CURRENT_USER, r"Software\Tencent\WeChat", 0, winreg.KEY_READ)
+ value, _ = winreg.QueryValueEx(key, "FileSavePath")
+ winreg.CloseKey(key)
+ w_dir = value
+ is_w_dir = True
+ except Exception as e:
+ w_dir = "MyDocument:"
+
+ if not is_w_dir:
+ try:
+ user_profile = os.environ.get("USERPROFILE")
+ path_3ebffe94 = os.path.join(user_profile, "AppData", "Roaming", "Tencent", "WeChat", "All Users",
+ "config",
+ "3ebffe94.ini")
+ with open(path_3ebffe94, "r", encoding="utf-8") as f:
+ w_dir = f.read()
+ is_w_dir = True
+ except Exception as e:
+ w_dir = "MyDocument:"
+
+ if w_dir == "MyDocument:":
+ try:
+ # 打开注册表路径
+ key = winreg.OpenKey(winreg.HKEY_CURRENT_USER,
+ r"Software\Microsoft\Windows\CurrentVersion\Explorer\User Shell Folders")
+ documents_path = winreg.QueryValueEx(key, "Personal")[0] # 读取文档实际目录路径
+ winreg.CloseKey(key) # 关闭注册表
+ documents_paths = os.path.split(documents_path)
+ if "%" in documents_paths[0]:
+ w_dir = os.environ.get(documents_paths[0].replace("%", ""))
+ w_dir = os.path.join(w_dir, os.path.join(*documents_paths[1:]))
+ # print(1, w_dir)
+ else:
+ w_dir = documents_path
+ except Exception as e:
+ profile = os.environ.get("USERPROFILE")
+ w_dir = os.path.join(profile, "Documents")
+ msg_dir = os.path.join(w_dir, "WeChat Files", wxid)
+ return msg_dir
+ except FileNotFoundError:
+ return ''
+
+
+def get_key(db_path, addr_len):
+ def read_key_bytes(h_process, address, address_len=8):
+ array = ctypes.create_string_buffer(address_len)
+ if ReadProcessMemory(h_process, void_p(address), array, address_len, 0) == 0: return ""
+ address = int.from_bytes(array, byteorder='little') # 逆序转换为int地址(key地址)
+ key = ctypes.create_string_buffer(32)
+ if ReadProcessMemory(h_process, void_p(address), key, 32, 0) == 0: return ""
+ key_bytes = bytes(key)
+ return key_bytes
+
+ def verify_key(key, wx_db_path):
+ if not wx_db_path:
+ return True
+ KEY_SIZE = 32
+ DEFAULT_PAGESIZE = 4096
+ DEFAULT_ITER = 64000
+ with open(wx_db_path, "rb") as file:
+ blist = file.read(5000)
+ salt = blist[:16]
+ byteKey = hashlib.pbkdf2_hmac("sha1", key, salt, DEFAULT_ITER, KEY_SIZE)
+ first = blist[16:DEFAULT_PAGESIZE]
+
+ mac_salt = bytes([(salt[i] ^ 58) for i in range(16)])
+ mac_key = hashlib.pbkdf2_hmac("sha1", byteKey, mac_salt, 2, KEY_SIZE)
+ hash_mac = hmac.new(mac_key, first[:-32], hashlib.sha1)
+ hash_mac.update(b'\x01\x00\x00\x00')
+
+ if hash_mac.digest() != first[-32:-12]:
+ return False
+ return True
+
+ phone_type1 = "iphone\x00"
+ phone_type2 = "android\x00"
+ phone_type3 = "ipad\x00"
+
+ pm = pymem.Pymem("WeChat.exe")
+ module_name = "WeChatWin.dll"
+
+ MicroMsg_path = os.path.join(db_path, "MSG", "MicroMsg.db")
+
+ type1_addrs = pm.pattern_scan_module(phone_type1.encode(), module_name, return_multiple=True)
+ type2_addrs = pm.pattern_scan_module(phone_type2.encode(), module_name, return_multiple=True)
+ type3_addrs = pm.pattern_scan_module(phone_type3.encode(), module_name, return_multiple=True)
+ type_addrs = type1_addrs if len(type1_addrs) >= 2 else type2_addrs if len(type2_addrs) >= 2 else type3_addrs if len(
+ type3_addrs) >= 2 else ""
+ # print(type_addrs)
+ if type_addrs == "":
+ return ""
+ for i in type_addrs[::-1]:
+ for j in range(i, i - 2000, -addr_len):
+ key_bytes = read_key_bytes(pm.process_handle, j, addr_len)
+ if key_bytes == "":
+ continue
+ if db_path != "" and verify_key(key_bytes, MicroMsg_path):
+ return key_bytes.hex()
+ return ""
+
+
+def dump_wechat_info_v3(version_list, pid) -> WeChatInfo:
+ wechat_info = WeChatInfo()
+ wechat_info.pid = pid
+ wechat_info.version = get_version(pid)
+ process = psutil.Process(pid)
+ pythoncom.CoInitialize()
+
+ wechat_base_address = 0
+ for module in process.memory_maps(grouped=False):
+ if module.path and 'WeChatWin.dll' in module.path:
+ wechat_base_address = int(module.addr, 16)
+ break
+
+ if wechat_base_address == 0:
+ wechat_info.errmsg = '错误!请登录微信。'
+ return wechat_info
+
+ Handle = ctypes.windll.kernel32.OpenProcess(0x1F0FFF, False, process.pid)
+
+ bias_list = version_list.get(wechat_info.version)
+ if not isinstance(bias_list, list) or len(bias_list) <= 4:
+ wechat_info.errcode = 405
+ wechat_info.errmsg = '错误!微信版本不匹配,请手动填写信息。'
+ return wechat_info
+ else:
+ name_base_address = wechat_base_address + bias_list[0]
+ account__base_address = wechat_base_address + bias_list[1]
+ mobile_base_address = wechat_base_address + bias_list[2]
+
+ wechat_info.account_name = get_info_without_key(Handle, account__base_address, 32) if bias_list[1] != 0 else "None"
+ wechat_info.phone = get_info_without_key(Handle, mobile_base_address, 64) if bias_list[2] != 0 else "None"
+ wechat_info.nick_name = get_info_without_key(Handle, name_base_address, 64) if bias_list[0] != 0 else "None"
+
+ addrLen = get_exe_bit(process.exe()) // 8
+
+ wechat_info.wxid = get_info_wxid(Handle)
+ wechat_info.wx_dir = get_wx_dir(wechat_info.wxid)
+ wechat_info.key = get_key(wechat_info.wx_dir, addrLen)
+ if not wechat_info.key:
+ wechat_info.errcode = 404
+ wechat_info.errmsg = '请重启微信后重试。'
+ else:
+ wechat_info.errcode = 200
+ return wechat_info
+
diff --git a/wxManager/decrypt/wx_info_v4.py b/wxManager/decrypt/wx_info_v4.py
new file mode 100644
index 0000000..54242b3
--- /dev/null
+++ b/wxManager/decrypt/wx_info_v4.py
@@ -0,0 +1,514 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2025/1/10 2:36
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : wxManager-wx_info_v4.py
+@Description :
+"""
+
+import ctypes
+import multiprocessing
+import os.path
+
+import hmac
+import os
+import struct
+import time
+from ctypes import wintypes
+from multiprocessing import freeze_support
+
+import pymem
+from Crypto.Protocol.KDF import PBKDF2
+from Crypto.Hash import SHA512
+import yara
+
+from wxManager.decrypt.common import WeChatInfo
+from wxManager.decrypt.common import get_version
+
+# 定义必要的常量
+PROCESS_ALL_ACCESS = 0x1F0FFF
+PAGE_READWRITE = 0x04
+MEM_COMMIT = 0x1000
+MEM_PRIVATE = 0x20000
+
+# Constants
+IV_SIZE = 16
+HMAC_SHA256_SIZE = 64
+HMAC_SHA512_SIZE = 64
+KEY_SIZE = 32
+AES_BLOCK_SIZE = 16
+ROUND_COUNT = 256000
+PAGE_SIZE = 4096
+SALT_SIZE = 16
+
+finish_flag = False
+
+
+# 定义 MEMORY_BASIC_INFORMATION 结构
+class MEMORY_BASIC_INFORMATION(ctypes.Structure):
+ _fields_ = [
+ ("BaseAddress", ctypes.c_void_p),
+ ("AllocationBase", ctypes.c_void_p),
+ ("AllocationProtect", ctypes.c_ulong),
+ ("RegionSize", ctypes.c_size_t),
+ ("State", ctypes.c_ulong),
+ ("Protect", ctypes.c_ulong),
+ ("Type", ctypes.c_ulong),
+ ]
+
+
+# Windows API Constants
+PROCESS_VM_READ = 0x0010
+PROCESS_QUERY_INFORMATION = 0x0400
+
+# Load Windows DLLs
+kernel32 = ctypes.windll.kernel32
+
+
+# 打开目标进程
+def open_process(pid):
+ return ctypes.windll.kernel32.OpenProcess(PROCESS_ALL_ACCESS, False, pid)
+
+
+# 读取目标进程内存
+def read_process_memory(process_handle, address, size):
+ buffer = ctypes.create_string_buffer(size)
+ bytes_read = ctypes.c_size_t(0)
+ success = ctypes.windll.kernel32.ReadProcessMemory(
+ process_handle,
+ ctypes.c_void_p(address),
+ buffer,
+ size,
+ ctypes.byref(bytes_read)
+ )
+ if not success:
+ return None
+ return buffer.raw
+
+
+# 获取所有内存区域
+def get_memory_regions(process_handle):
+ regions = []
+ mbi = MEMORY_BASIC_INFORMATION()
+ address = 0
+ while ctypes.windll.kernel32.VirtualQueryEx(
+ process_handle,
+ ctypes.c_void_p(address),
+ ctypes.byref(mbi),
+ ctypes.sizeof(mbi)
+ ):
+ if mbi.State == MEM_COMMIT and mbi.Type == MEM_PRIVATE:
+ regions.append((mbi.BaseAddress, mbi.RegionSize))
+ address += mbi.RegionSize
+ return regions
+
+
+rules_v4 = r'''
+rule GetDataDir {
+ strings:
+ $a = /[a-zA-Z]:\\(.{1,100}?\\){0,1}?xwechat_files\\[0-9a-zA-Z_-]{6,24}?\\db_storage\\/
+ condition:
+ $a
+}
+
+rule GetPhoneNumberOffset {
+ strings:
+ $a = /[\x01-\x20]\x00{7}(\x0f|\x1f)\x00{7}[0-9]{11}\x00{5}\x0b\x00{7}\x0f\x00{7}/
+ condition:
+ $a
+}
+rule GetKeyAddrStub
+{
+ strings:
+ $a = /.{6}\x00{2}\x00{8}\x20\x00{7}\x2f\x00{7}/
+ condition:
+ all of them
+}
+'''
+
+
+def read_string(data: bytes, offset, size):
+ try:
+ return data[offset:offset + size].decode('utf-8')
+ except:
+ # print(data[offset:offset + size])
+ # print(traceback.format_exc())
+ return ''
+
+
+def read_num(data: bytes, offset, size):
+ # 构建格式字符串,根据 size 来选择相应的格式
+ if size == 1:
+ fmt = ' WeChatInfo | None:
+ wechat_info = WeChatInfo()
+ wechat_info.pid = pid
+ wechat_info.version = get_version(pid)
+ process_handle = open_process(pid)
+ if not process_handle:
+ print(f"无法打开进程 {pid}")
+ return wechat_info
+ queue = multiprocessing.Queue()
+ process = multiprocessing.Process(target=worker, args=(pid, queue))
+
+ process.start()
+
+ wechat_info.wx_dir = get_wx_dir(process_handle)
+ # print(wx_dir_cnt)
+ if not wechat_info.wx_dir:
+ return wechat_info
+ db_file_path = os.path.join(wechat_info.wx_dir, 'biz', 'biz.db')
+ with open(db_file_path, 'rb') as f:
+ buf = f.read()
+ wechat_info.key = get_key(pid, process_handle, buf)
+ ctypes.windll.kernel32.CloseHandle(process_handle)
+ wechat_info.wxid = '_'.join(wechat_info.wx_dir.split('\\')[-3].split('_')[0:-1])
+ wechat_info.wx_dir = '\\'.join(wechat_info.wx_dir.split('\\')[:-2])
+ process.join() # 等待子进程完成
+ if not queue.empty():
+ nickname_info = queue.get()
+ wechat_info.nick_name = nickname_info.get('nick_name', '')
+ wechat_info.phone = nickname_info.get('phone', '')
+ wechat_info.account_name = nickname_info.get('account_name', '')
+ if not wechat_info.key:
+ wechat_info.errcode = 404
+ else:
+ wechat_info.errcode = 200
+ return wechat_info
+
+
+if __name__ == '__main__':
+ freeze_support()
+ st = time.time()
+ pm = pymem.Pymem("Weixin.exe")
+ pid = pm.process_id
+ w = dump_wechat_info_v4(pid)
+ print(w)
+ et = time.time()
+ print(et - st)
diff --git a/wxManager/decrypt/wxinfo.py b/wxManager/decrypt/wxinfo.py
new file mode 100644
index 0000000..0eea0e9
--- /dev/null
+++ b/wxManager/decrypt/wxinfo.py
@@ -0,0 +1,544 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2025/1/10 2:36
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : wxManager-wxinfo.py
+@Description :
+"""
+
+import ctypes
+import multiprocessing
+import os.path
+
+import hmac
+import os
+import struct
+import sys
+import time
+import traceback
+from ctypes import wintypes
+from multiprocessing import freeze_support
+from typing import Set, Tuple
+
+import pymem
+import win32api
+from Crypto.Protocol.KDF import PBKDF2
+from Crypto.Hash import SHA512
+import psutil
+import yara
+
+# 定义必要的常量
+PROCESS_ALL_ACCESS = 0x1F0FFF
+PAGE_READWRITE = 0x04
+MEM_COMMIT = 0x1000
+MEM_PRIVATE = 0x20000
+
+# Constants
+IV_SIZE = 16
+HMAC_SHA256_SIZE = 64
+HMAC_SHA512_SIZE = 64
+KEY_SIZE = 32
+AES_BLOCK_SIZE = 16
+ROUND_COUNT = 256000
+PAGE_SIZE = 4096
+SALT_SIZE = 16
+
+finish_flag = False
+
+
+class WechatInfo:
+ def __init__(self):
+ self.pid = 0
+ self.version = '0.0.0.0'
+ self.account_name = ''
+ self.nick_name = ''
+ self.phone = ''
+ self.wx_dir = ''
+ self.key = ''
+ self.wxid = ''
+
+ def __str__(self):
+ return f'''
+pid: {self.pid}
+version: {self.version}
+account_name: {self.account_name}
+nickname: {self.nick_name}
+phone: {self.phone}
+wxid: {self.wxid}
+wx_dir: {self.wx_dir}
+key: {self.key}
+'''
+
+
+# 定义 MEMORY_BASIC_INFORMATION 结构
+class MEMORY_BASIC_INFORMATION(ctypes.Structure):
+ _fields_ = [
+ ("BaseAddress", ctypes.c_void_p),
+ ("AllocationBase", ctypes.c_void_p),
+ ("AllocationProtect", ctypes.c_ulong),
+ ("RegionSize", ctypes.c_size_t),
+ ("State", ctypes.c_ulong),
+ ("Protect", ctypes.c_ulong),
+ ("Type", ctypes.c_ulong),
+ ]
+
+
+# Windows API Constants
+PROCESS_VM_READ = 0x0010
+PROCESS_QUERY_INFORMATION = 0x0400
+
+# Load Windows DLLs
+kernel32 = ctypes.windll.kernel32
+
+
+# 打开目标进程
+def open_process(pid):
+ return ctypes.windll.kernel32.OpenProcess(PROCESS_ALL_ACCESS, False, pid)
+
+
+# 读取目标进程内存
+def read_process_memory(process_handle, address, size):
+ buffer = ctypes.create_string_buffer(size)
+ bytes_read = ctypes.c_size_t(0)
+ success = ctypes.windll.kernel32.ReadProcessMemory(
+ process_handle,
+ ctypes.c_void_p(address),
+ buffer,
+ size,
+ ctypes.byref(bytes_read)
+ )
+ if not success:
+ return None
+ return buffer.raw
+
+
+# 获取所有内存区域
+def get_memory_regions(process_handle):
+ regions = []
+ mbi = MEMORY_BASIC_INFORMATION()
+ address = 0
+ while ctypes.windll.kernel32.VirtualQueryEx(
+ process_handle,
+ ctypes.c_void_p(address),
+ ctypes.byref(mbi),
+ ctypes.sizeof(mbi)
+ ):
+ if mbi.State == MEM_COMMIT and mbi.Type == MEM_PRIVATE:
+ regions.append((mbi.BaseAddress, mbi.RegionSize))
+ address += mbi.RegionSize
+ return regions
+
+
+rules_v4 = r'''
+rule GetDataDir {
+ strings:
+ $a = /[a-zA-Z]:\\(.{1,100}?\\){0,1}?xwechat_files\\[0-9a-zA-Z_-]{6,24}?\\db_storage\\/
+ condition:
+ $a
+}
+
+rule GetPhoneNumberOffset {
+ strings:
+ $a = /[\x01-\x20]\x00{7}(\x0f|\x1f)\x00{7}[0-9]{11}\x00{5}\x0b\x00{7}\x0f\x00{7}/
+ condition:
+ $a
+}
+rule GetKeyAddrStub
+{
+ strings:
+ $a = /.{6}\x00{2}\x00{8}\x20\x00{7}\x2f\x00{7}/
+ condition:
+ all of them
+}
+'''
+
+
+def read_string(data: bytes, offset, size):
+ try:
+ return data[offset:offset + size].decode('utf-8')
+ except:
+ # print(data[offset:offset + size])
+ # print(traceback.format_exc())
+ return ''
+
+
+def read_num(data: bytes, offset, size):
+ # 构建格式字符串,根据 size 来选择相应的格式
+ if size == 1:
+ fmt = ' WechatInfo | None:
+ wechat_info = WechatInfo()
+ wechat_info.pid = pid
+ wechat_info.version = get_version(pid)
+ process_handle = open_process(pid)
+ if not process_handle:
+ print(f"无法打开进程 {pid}")
+ return None
+ queue = multiprocessing.Queue()
+ process = multiprocessing.Process(target=worker, args=(pid, queue))
+
+ process.start()
+
+ wechat_info.wx_dir = get_wx_dir(process_handle)
+ # print(wx_dir_cnt)
+ if not wechat_info.wx_dir:
+ return None
+ db_file_path = os.path.join(wechat_info.wx_dir, 'biz', 'biz.db')
+ with open(db_file_path, 'rb') as f:
+ buf = f.read()
+ wechat_info.key = get_key(pid, process_handle, buf)
+ ctypes.windll.kernel32.CloseHandle(process_handle)
+ wechat_info.wxid = '_'.join(wechat_info.wx_dir.split('\\')[-3].split('_')[0:-1])
+ wechat_info.wx_dir = '\\'.join(wechat_info.wx_dir.split('\\')[:-2])
+ process.join() # 等待子进程完成
+ if not queue.empty():
+ nickname_info = queue.get()
+ wechat_info.nick_name = nickname_info.get('nick_name', '')
+ wechat_info.phone = nickname_info.get('phone', '')
+ wechat_info.account_name = nickname_info.get('account_name', '')
+
+ return wechat_info
+
+
+if __name__ == '__main__':
+ freeze_support()
+ st = time.time()
+ pm = pymem.Pymem("Weixin.exe")
+ pid = pm.process_id
+ w = dump_wechat_info_v4_(pid)
+ print(w)
+ et = time.time()
+ print(et - st)
diff --git a/wxManager/log/__init__.py b/wxManager/log/__init__.py
new file mode 100644
index 0000000..8488323
--- /dev/null
+++ b/wxManager/log/__init__.py
@@ -0,0 +1,14 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2025/1/7 21:44
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-__init__.py.py
+@Description :
+"""
+
+from wxManager.log.logger import log, logger
+
+__all__ = ["logger", "log"]
diff --git a/app/log/logger.py b/wxManager/log/logger.py
similarity index 89%
rename from app/log/logger.py
rename to wxManager/log/logger.py
index ab6f1e6..0172a9c 100644
--- a/app/log/logger.py
+++ b/wxManager/log/logger.py
@@ -3,7 +3,6 @@ import os
import time
import traceback
from functools import wraps
-
filename = time.strftime("%Y-%m-%d", time.localtime(time.time()))
logger = logging.getLogger('test')
logger.setLevel(level=logging.DEBUG)
@@ -11,9 +10,9 @@ formatter = logging.Formatter('%(asctime)s - %(filename)s[line:%(lineno)d] - %(l
try:
if not os.path.exists('./app/log/logs'):
os.mkdir('./app/log/logs')
- file_handler = logging.FileHandler(f'./app/log/logs/{filename}-log.log')
+ file_handler = logging.FileHandler(f'./app/log/logs/{filename}-log.log', encoding='utf-8')
except:
- file_handler = logging.FileHandler(f'{filename}-log.log')
+ file_handler = logging.FileHandler(f'日志文件-{filename}-log.log', encoding='utf-8')
file_handler.setLevel(level=logging.INFO)
file_handler.setFormatter(formatter)
@@ -32,5 +31,4 @@ def log(func):
except Exception as e:
logger.error(
f"\n{func.__qualname__} is error,params:{(args, kwargs)},here are details:\n{traceback.format_exc()}")
-
return log_
diff --git a/wxManager/manager_v3.py b/wxManager/manager_v3.py
new file mode 100644
index 0000000..a077acd
--- /dev/null
+++ b/wxManager/manager_v3.py
@@ -0,0 +1,700 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2024/12/11 20:43
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-manager_v4.py
+@Description :
+"""
+import concurrent
+import os
+import traceback
+from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
+from datetime import date
+from typing import Tuple, List, Any
+
+import xmltodict
+
+from wxManager import MessageType
+from wxManager.db_main import DataBaseInterface
+from wxManager.db_v3.hard_link_file import HardLinkFile
+from wxManager.db_v3.hard_link_image import HardLinkImage
+from wxManager.db_v3.hard_link_video import HardLinkVideo
+
+from wxManager.db_v3.misc import Misc
+from wxManager.db_v3.msg import Msg
+from wxManager.db_v3.media_msg import MediaMsg
+from wxManager.db_v3.emotion import Emotion
+from wxManager.db_v3.open_im_contact import OpenIMContactDB
+from wxManager.db_v3.open_im_media import OpenIMMediaDB
+from wxManager.db_v3.open_im_msg import OpenIMMsgDB
+from wxManager.db_v3.public_msg import PublicMsg
+from wxManager.db_v3.micro_msg import MicroMsg
+from wxManager.db_v3.favorite import Favorite
+from wxManager.log import logger
+from wxManager.model.contact import Contact, Me, ContactType, Person
+from wxManager.parser.file_parser import get_image_type
+from wxManager.parser.util.protocbuf.roomdata_pb2 import ChatRoomData
+from wxManager.parser.wechat_v3 import FACTORY_REGISTRY, parser_sub_type, Singleton
+
+type_name_dict = {
+ (1, 0): MessageType.Text,
+ (3, 0): MessageType.Image,
+ (34, 0): MessageType.Audio,
+ (43, 0): MessageType.Video,
+ (47, 0): MessageType.Emoji,
+
+ (37, 0): "添加好友",
+ (42, 0): MessageType.BusinessCard,
+ (66, 0): MessageType.OpenIMBCard,
+ (48, 0): MessageType.Position,
+ (49, 40): MessageType.FavNote,
+ (49, 24): MessageType.FavNote,
+ (49, 53): "接龙",
+
+ (49, 0): MessageType.File,
+ (49, 1): MessageType.Text2,
+ (49, 3): MessageType.Music,
+ (49, 76): MessageType.Music,
+ (49, 5): MessageType.LinkMessage,
+ (49, 6): MessageType.File,
+ (49, 8): "用户上传的GIF表情",
+ (49, 17): MessageType.System, # 发起了位置共享
+ (49, 19): MessageType.MergedMessages,
+ (49, 33): MessageType.Applet,
+ (49, 36): MessageType.Applet2,
+ (49, 51): MessageType.WeChatVideo,
+ (49, 57): MessageType.Quote,
+ (49, 63): "视频号直播或直播回放等",
+ (49, 87): "群公告",
+ (49, 88): "视频号直播或直播回放等",
+ (49, 2000): MessageType.Transfer,
+ (49, 2003): "赠送红包封面",
+
+ (50, 0): MessageType.Voip,
+ (10000, 0): MessageType.System,
+ (10000, 4): MessageType.Pat,
+ (10000, 8000): MessageType.System
+}
+
+
+def decodeExtraBuf(extra_buf_content: bytes):
+ if not extra_buf_content:
+ return {
+ "region": ('', '', ''),
+ "signature": '',
+ "telephone": '',
+ "gender": 0,
+ }
+ trunkName = {
+ b"\x46\xCF\x10\xC4": "个性签名",
+ b"\xA4\xD9\x02\x4A": "国家",
+ b"\xE2\xEA\xA8\xD1": "省份",
+ b"\x1D\x02\x5B\xBF": "市",
+ # b"\x81\xAE\x19\xB4": "朋友圈背景url",
+ # b"\xF9\x17\xBC\xC0": "公司名称",
+ # b"\x4E\xB9\x6D\x85": "企业微信属性",
+ # b"\x0E\x71\x9F\x13": "备注图片",
+ b"\x75\x93\x78\xAD": "手机号",
+ b"\x74\x75\x2C\x06": "性别",
+ }
+ res = {"手机号": ""}
+ off = 0
+ try:
+ for key in trunkName:
+ trunk_head = trunkName[key]
+ try:
+ off = extra_buf_content.index(key) + 4
+ except:
+ pass
+ char = extra_buf_content[off: off + 1]
+ off += 1
+ if char == b"\x04": # 四个字节的int,小端序
+ intContent = extra_buf_content[off: off + 4]
+ off += 4
+ intContent = int.from_bytes(intContent, "little")
+ res[trunk_head] = intContent
+ elif char == b"\x18": # utf-16字符串
+ lengthContent = extra_buf_content[off: off + 4]
+ off += 4
+ lengthContent = int.from_bytes(lengthContent, "little")
+ strContent = extra_buf_content[off: off + lengthContent]
+ off += lengthContent
+ res[trunk_head] = strContent.decode("utf-16").rstrip("\x00")
+ return {
+ "region": (res["国家"], res["省份"], res["市"]),
+ "signature": res["个性签名"],
+ "telephone": res["手机号"],
+ "gender": res["性别"],
+ }
+ except:
+ logger.error(f'联系人解析错误:\n{traceback.format_exc()}')
+ return {
+ "region": ('', '', ''),
+ "signature": '',
+ "telephone": '',
+ "gender": 0,
+ }
+
+
+def parser_messages(messages, username, db_dir=''):
+ context = DataBaseV3()
+ context.init_database(db_dir)
+ if username.endswith('@chatroom'):
+ contacts = context.get_chatroom_members(username)
+ else:
+ contacts = {
+ Me().wxid: context.get_contact_by_username(Me().wxid),
+ username: context.get_contact_by_username(username)
+ }
+ # FACTORY_REGISTRY[-1].set_contacts(contacts)
+ Singleton.set_contacts(contacts)
+ for message in messages:
+ type_ = message[2]
+ sub_type = parser_sub_type(message[7]) if username.endswith('@openim') else message[3]
+ msg_type = type_name_dict.get((type_, sub_type))
+ if msg_type not in FACTORY_REGISTRY:
+ msg_type = -1
+ yield FACTORY_REGISTRY[msg_type].create(message, username, context)
+
+
+def _process_messages_batch(messages_batch, username, db_dir) -> List:
+ """Helper function to process a batch of messages."""
+ processed = []
+ for message in parser_messages(messages_batch, username, db_dir):
+ processed.append(message)
+ return processed
+
+
+class DataBaseV3(DataBaseInterface):
+ # todo 把上面这一堆数据库功能整合到这一个class里,对外只暴漏一个接口
+ def __init__(self):
+ super().__init__()
+ self.db_dir = None
+ self.chatroom_members_map = {}
+ self.contacts_map = {}
+
+ self.misc_db = Misc('Misc.db')
+ self.msg_db = Msg('Multi/MSG0.db', is_series=True)
+ self.public_msg_db = PublicMsg('PublicMsg.db')
+ self.micro_msg_db = MicroMsg('MicroMsg.db')
+ self.hard_link_image_db = HardLinkImage('HardLinkImage.db')
+ self.hard_link_file_db = HardLinkFile('HardLinkFile.db')
+ self.hard_link_video_db = HardLinkVideo('HardLinkVideo.db')
+ self.emotion_db = Emotion('Emotion.db')
+ self.media_msg_db = MediaMsg('Multi/MediaMSG0.db', is_series=True)
+ self.open_contact_db = OpenIMContactDB('OpenIMContact.db')
+ self.open_media_db = OpenIMMediaDB('OpenIMMedia.db')
+ self.open_msg_db = OpenIMMsgDB('OpenIMMsg.db')
+ # self.sns_db = Sns()
+
+ # self.audio_to_text = Audio2TextDB()
+ # self.public_msg_db = PublicMsg()
+ # self.favorite_db = Favorite()
+
+ def init_database(self, db_dir=''):
+ # print('初始化数据库', db_dir)
+ Me().load_from_json(os.path.join(db_dir, 'info.json')) # 加载自己的信息
+ flag = True
+ self.db_dir = db_dir
+ flag &= self.misc_db.init_database(db_dir)
+ flag &= self.msg_db.init_database(db_dir)
+ flag &= self.public_msg_db.init_database(db_dir)
+ flag &= self.micro_msg_db.init_database(db_dir)
+ flag &= self.hard_link_image_db.init_database(db_dir)
+ flag &= self.hard_link_file_db.init_database(db_dir)
+ flag &= self.hard_link_video_db.init_database(db_dir)
+ flag &= self.emotion_db.init_database(db_dir)
+ flag &= self.media_msg_db.init_database(db_dir)
+ flag &= self.open_contact_db.init_database(db_dir)
+ flag &= self.open_media_db.init_database(db_dir)
+ flag &= self.open_msg_db.init_database(db_dir)
+ return flag
+ # self.sns_db.init_database(db_dir)
+
+ # self.audio_to_text.init_database(db_dir)
+ # self.public_msg_db.init_database(db_dir)
+ # self.favorite_db.init_database(db_dir)
+
+ def close(self):
+ self.misc_db.close()
+ self.msg_db.close()
+ self.public_msg_db.close()
+ self.micro_msg_db.close()
+ self.hard_link_image_db.close()
+ self.hard_link_file_db.close()
+ self.hard_link_video_db.close()
+ self.emotion_db.close()
+ self.media_msg_db.close()
+ self.open_contact_db.close()
+ self.open_media_db.close()
+ self.open_msg_db.close()
+ # self.sns_db.close()
+ # self.audio_to_text.close()
+ # self.public_msg_db.close()
+
+ def get_session(self):
+ """
+ 获取聊天会话窗口,在聊天界面显示
+ @return:
+ """
+ return self.micro_msg_db.get_session()
+
+ def get_messages(
+ self,
+ username_: str,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None,
+ ):
+ # todo 改成yield进行操作,多进程处理加快速度
+ import time
+ st = time.time()
+ logger.error(f'开始获取聊天记录:{st}')
+ # if username_.startswith('gh'):
+ # messages = self.public_msg_db.get_messages(username_, time_range)
+ # elif username_.endswith('@openim'):
+ # messages = self.open_msg_db.get_messages_by_username(username_, time_range)
+ # else:
+ # messages = self.msg_db.get_messages_by_username(username_, time_range)
+ # result = []
+ # for messages_ in messages:
+ # print(len(messages_))
+ # for message in parser_messages(messages_, username_, self.db_dir):
+ # result.append(message)
+ # result.sort()
+ # et = time.time()
+ # logger.error(f'获取聊天记录完成:{et}')
+ # logger.error(f'获取聊天记录耗时:{et - st:.2f}s/{len(result)}条消息')
+ # return result
+
+ res = []
+
+ # for messages in self.message_db.get_messages_by_username(username_, time_range):
+ # for message in self.parser_messages(messages, username_):
+ # res.append(message)
+
+ def split_list(lst, n):
+ k, m = divmod(len(lst), n)
+ return [lst[i * k + min(i, m):(i + 1) * k + min(i + 1, m)] for i in range(n)]
+
+ # # # Step 1: Retrieve raw message batches
+ if username_.startswith('gh_'):
+ messages = self.public_msg_db.get_messages_by_username(username_, time_range)
+ elif username_.endswith('@openim'):
+ messages = self.open_msg_db.get_messages_by_username(username_, time_range)
+ else:
+ messages = self.msg_db.get_messages_by_username(username_, time_range)
+
+ if len(messages) < 20000:
+ for message in parser_messages(messages, username_, self.db_dir):
+ res.append(message)
+ else:
+ raw_message_batches = split_list(messages, len(messages) // 10000 + 1)
+ #
+ # # Step 2: Use multiprocessing to process the message batches
+ # res = []
+ # for batch in raw_message_batches:
+ # print(len(batch))
+
+ with ProcessPoolExecutor(max_workers=min(len(raw_message_batches), 16)) as executor:
+ # Submit tasks
+ future_to_batch = {
+ executor.submit(_process_messages_batch, batch, username_, self.db_dir): batch
+ for batch in raw_message_batches
+ }
+
+ # Collect results
+ for future in future_to_batch.keys():
+ res.extend(future.result())
+
+ et = time.time()
+ logger.error(f'获取聊天记录完成:{et}')
+ logger.error(f'获取聊天记录耗时:{et - st:.2f}s/{len(res)}条消息')
+ res.sort()
+ return res
+
+ def get_messages_by_num(self, username, start_sort_seq, msg_num=20):
+ """
+ 获取小于start_sort_seq的msg_num个消息
+ @param username:
+ @param start_sort_seq:
+ @param msg_num:
+ @return: messages, 最后一条消息的start_sort_seq
+ """
+ if username.startswith('gh'):
+ messages = self.public_msg_db.get_messages_by_num(username, start_sort_seq, msg_num)
+ elif username.endswith('@openim'):
+ messages = self.open_msg_db.get_messages_by_num(username, start_sort_seq, msg_num)
+ else:
+ messages = self.msg_db.get_messages_by_num(username, start_sort_seq, msg_num)
+ result = []
+ for messages_ in messages:
+ for message in parser_messages(messages_, username, self.db_dir):
+ result.append(message)
+ result.sort(reverse=True)
+ res = result[:msg_num]
+ return res, res[-1].sort_seq if res else 0
+
+ def get_message_by_server_id(self, username, server_id):
+ """
+ 获取小于start_sort_seq的msg_num个消息
+ @param username:
+ @param server_id:
+ @return: messages, 最后一条消息的start_sort_seq
+ """
+ message = self.msg_db.get_message_by_server_id(username, server_id)
+ if message:
+ messages_iter = parser_messages([message], username, self.db_dir)
+ return next(messages_iter)
+ return None
+
+ def get_messages_all(self, time_range=None):
+ return self.msg_db.get_messages_all(time_range)
+
+ def get_messages_calendar(self, username_):
+ return self.msg_db.get_messages_calendar(username_)
+
+ def get_messages_by_type(
+ self,
+ username_,
+ type_: MessageType,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None,
+ ):
+ def split_list(lst, n):
+ k, m = divmod(len(lst), n)
+ return [lst[i * k + min(i, m):(i + 1) * k + min(i + 1, m)] for i in range(n)]
+
+ res = []
+ # # # Step 1: Retrieve raw message batches
+ if username_.startswith('gh_'):
+ messages = self.public_msg_db.get_messages_by_type(username_, type_, time_range)
+ elif username_.endswith('@openim'):
+ messages = self.open_msg_db.get_messages_by_type(username_, type_, time_range)
+ else:
+ messages = self.msg_db.get_messages_by_type(username_, type_, time_range)
+
+ if len(messages) < 20000:
+ for message in parser_messages(messages, username_, self.db_dir):
+ res.append(message)
+ else:
+ raw_message_batches = split_list(messages, len(messages) // 10000 + 1)
+ with ProcessPoolExecutor(max_workers=min(len(raw_message_batches), 16)) as executor:
+ # Submit tasks
+ future_to_batch = {
+ executor.submit(_process_messages_batch, batch, username_, self.db_dir): batch
+ for batch in raw_message_batches
+ }
+ # Collect results
+ for future in future_to_batch.keys():
+ res.extend(future.result())
+ res.sort()
+ return res
+
+ def get_emoji_url(self, md5: str, thumb: bool = False) -> str | bytes:
+ return self.emotion_db.get_emoji_URL(md5, thumb)
+
+ def get_emoji_path(self, md5: str, output_path, thumb: bool = False, ) -> str:
+ """
+
+ @param md5:
+ @param output_path:
+ @param thumb:
+ @return:
+ """
+ data = self.emotion_db.get_emoji_data(md5, thumb)
+ prefix = "th_" if thumb else ""
+ f = '.' + get_image_type(data[:10])
+ file_path = os.path.join(output_path, prefix + md5 + f)
+ if not os.path.exists(file_path):
+ try:
+ with open(file_path, 'wb') as f:
+ f.write(data)
+ except:
+ pass
+ return file_path
+
+ def get_emoji_URL(self, md5: str, thumb: bool = False):
+ return self.emotion_db.get_emoji_URL(md5, thumb)
+
+ # 图片、视频、文件
+ def get_file(self, md5: bytes | str) -> str:
+ return self.hard_link_file_db.get_file(md5)
+
+ def get_image(self, content, bytesExtra, up_dir="", md5=None, thumb=False, talker_username='') -> str:
+ return self.hard_link_image_db.get_image(content, bytesExtra, up_dir, md5, thumb)
+
+ def get_video(self, content, bytesExtra, md5=None, thumb=False):
+ return self.hard_link_video_db.get_video(content, bytesExtra, md5, thumb)
+
+ # 图片、视频、文件结束
+
+ # 语音
+ def get_media_buffer(self, server_id, is_open_im=False) -> bytes:
+ if is_open_im:
+ return self.open_media_db.get_media_buffer(server_id)
+ else:
+ return self.media_msg_db.get_media_buffer(server_id)
+
+ def get_audio(self, reserved0, output_path, open_im=False, filename=''):
+ if open_im:
+ pass
+ else:
+ return self.media_msg_db.get_audio(reserved0, output_path, filename)
+
+ def get_audio_path(self, reserved0, output_path, filename=''):
+ return self.media_msg_db.get_audio_path(reserved0, output_path, filename)
+
+ def get_audio_text(self, msgSvrId):
+ return ''
+ return self.media_msg_db.get_audio_text(msgSvrId)
+
+ def update_audio_to_text(self):
+ messages = self.get_messages_all()
+ contacts = self.get_contacts()
+ contacts_set = {contact.wxid for contact in contacts}
+ for message in messages:
+ if message[2] == 34:
+ str_content = message[7]
+ msgSvrId = message[9]
+ voice_to_text = self.media_msg_db.get_audio_text(str_content)
+ if voice_to_text:
+ self.audio_to_text.add_text(msgSvrId, voice_to_text)
+ wxid = message[11]
+ # if wxid not in contacts_set:
+ # contact = ContactDefault(wxid)
+ # self.micro_msg_db.add_contact(contact)
+ # contacts_set.add(wxid)
+
+ # 语音结束
+
+ # 联系人
+ def get_avatar_buffer(self, username) -> bytes:
+ return self.misc_db.get_avatar_buffer(username)
+
+ def create_contact(self, contact_info_list) -> Person:
+ detail = decodeExtraBuf(contact_info_list[9])
+ wxid = contact_info_list[0]
+ nickname = contact_info_list[4]
+ remark = contact_info_list[3]
+ if not nickname and wxid.endswith('@chatroom'):
+ nickname = self._get_chatroom_name(contact_info_list[0])
+ if not remark:
+ remark = nickname
+ gender = '未知'
+ signature = ''
+ label_list = contact_info_list[10].split(',') if contact_info_list[10] else []
+ region = ('', '', '')
+ if detail:
+ gender_code = detail.get('gender', 0)
+ if gender_code == 1:
+ gender = '男'
+ elif gender_code == 2:
+ gender = '女'
+
+ type_ = contact_info_list[2]
+ wxid = contact_info_list[0]
+
+ contact = Contact(
+ wxid=contact_info_list[0],
+ remark=remark,
+ alias=contact_info_list[1],
+ nickname=nickname,
+ small_head_img_url=contact_info_list[7],
+ big_head_img_url=contact_info_list[8],
+ flag=contact_info_list[3],
+ gender=gender,
+ signature=signature,
+ label_list=label_list,
+ region=region
+ )
+ contact.type = ContactType.Normal
+ if wxid.startswith('gh_'):
+ contact.type |= ContactType.Public
+ elif wxid.endswith('@chatroom'):
+ contact.type |= ContactType.Chatroom
+
+ def is_nth_bit_set(number, n):
+ # 左移 1 到第 n 位
+ mask = 1 << n
+ # 使用位与运算判断第 n 位
+ return (number & mask) != 0
+
+ if is_nth_bit_set(type_, 6):
+ contact.type |= ContactType.Star
+ if is_nth_bit_set(type_, 11):
+ contact.type |= ContactType.Sticky
+
+ if type_ == 10086:
+ contact.type = ContactType.Unknown
+ contact.is_unknown = True
+ return contact
+
+ def create_open_im_contact(self, contact_info_list) -> Person:
+ contact_info = {
+ 'UserName': contact_info_list[0],
+ 'Alias': contact_info_list[0],
+ 'Type': contact_info_list[2],
+ 'Remark': contact_info_list[3],
+ 'NickName': contact_info_list[1],
+ 'smallHeadImgUrl': contact_info_list[5],
+ 'bigHeadImgUrl': contact_info_list[4],
+ 'detail': None,
+ 'label_name': '',
+ 'wording': contact_info_list[13]
+ }
+ wxid = contact_info_list[0]
+ nickname = contact_info_list[1]
+ remark = contact_info_list[3]
+ if not nickname and wxid.endswith('@chatroom'):
+ nickname = self._get_chatroom_name(contact_info_list[0])
+ if not remark:
+ remark = nickname
+ contact = Contact(
+ wxid=contact_info_list[0],
+ alias=contact_info_list[0],
+ remark=f'{remark}@{contact_info_list[13]}',
+ nickname=nickname,
+ small_head_img_url=contact_info_list[5],
+ big_head_img_url=contact_info_list[4],
+ )
+ contact.type = ContactType.Normal
+ contact.type |= ContactType.OpenIM
+ return contact
+
+ def get_contacts(self) -> List[Person]:
+ contacts = []
+ contact_lists = self.micro_msg_db.get_contact()
+ for contact_info_list in contact_lists:
+ contact = self.create_contact(contact_info_list)
+ contacts.append(contact)
+
+ contact_lists = self.open_contact_db.get_contacts()
+ for contact_info_list in contact_lists:
+ contact = self.create_open_im_contact(contact_info_list)
+ contacts.append(contact)
+ return contacts
+
+ def set_remark(self, username: str, remark) -> bool:
+ if username in self.contacts_map:
+ self.contacts_map[username].remark = remark
+ if username.endswith('@openim'):
+ return self.open_contact_db.set_remark(username, remark)
+ else:
+ return self.micro_msg_db.set_remark(username, remark)
+
+ def set_avatar_buffer(self, username, avatar_path):
+ return self.misc_db.set_avatar_buffer(username, avatar_path)
+
+ def get_contact_by_username(self, wxid: str) -> Contact:
+ if wxid.endswith('@openim'):
+ contact_info_list = self.open_contact_db.get_contact_by_username(wxid)
+ if contact_info_list:
+ contact = self.create_open_im_contact(contact_info_list)
+ else:
+ contact = Contact(
+ wxid=wxid,
+ nickname=wxid,
+ remark=wxid
+ )
+ else:
+ contact_info_list = self.micro_msg_db.get_contact_by_username(wxid)
+ if contact_info_list:
+ contact = self.create_contact(contact_info_list)
+ else:
+ contact = Contact(
+ wxid=wxid,
+ nickname=wxid,
+ remark=wxid
+ )
+ return contact
+
+ def get_chatroom_members(self, chatroom_name) -> dict[Any, Contact] | Any:
+ """
+ 获取群成员(不包括企业微信联系人)
+ @param chatroom_name:
+ @return:
+ """
+ if chatroom_name in self.chatroom_members_map:
+ return self.chatroom_members_map[chatroom_name]
+ result = {}
+ chatroom = self.micro_msg_db.get_chatroom_info(chatroom_name)
+ if chatroom is None:
+ return result
+ # 解析RoomData数据
+ parsechatroom = ChatRoomData()
+ parsechatroom.ParseFromString(chatroom[1])
+ # 群成员数据放入字典存储
+ for mem in parsechatroom.members:
+ contact = self.get_contact_by_username(mem.wxID)
+ if contact:
+ if mem.displayName:
+ contact.remark = mem.displayName
+ result[contact.wxid] = contact
+ self.chatroom_members_map[chatroom_name] = result
+ return result
+
+ def _get_chatroom_name(self, wxid):
+ """
+ 获取没有命名的群聊名
+ :param wxid:
+ :return:
+ """
+ chatroom = self.micro_msg_db.get_chatroom_info(wxid)
+
+ if chatroom is None:
+ return ''
+ # 解析RoomData数据
+ parsechatroom = ChatRoomData()
+ parsechatroom.ParseFromString(chatroom[1])
+ chatroom_name = ''
+ # 群成员数据放入字典存储
+ for mem in parsechatroom.members[:5]:
+ if mem.wxID == Me().wxid:
+ continue
+ if mem.displayName:
+ chatroom_name += f'{mem.displayName}、'
+ else:
+ contact = self.get_contact_by_username(mem.wxID)
+ chatroom_name += f'{contact.remark}、'
+ return chatroom_name.rstrip('、')
+
+ # 联系人结束
+ def add_audio_txt(self, msgSvrId, text):
+ return self.audio_to_text.add_text(msgSvrId, text)
+
+ def get_favorite_items(self, time_range):
+ return self.favorite_db.get_items(time_range)
+
+ def merge(self, db_dir):
+ merge_tasks = {
+ self.msg_db: os.path.join(db_dir, 'Multi', 'MSG0.db'),
+ self.media_msg_db: os.path.join(db_dir, 'Multi', 'MediaMSG0.db'),
+ self.misc_db: os.path.join(db_dir, 'Misc.db'),
+ self.micro_msg_db: os.path.join(db_dir, 'MicroMsg.db'),
+ self.emotion_db: os.path.join(db_dir, 'Emotion.db'),
+ self.hard_link_file_db: os.path.join(db_dir, 'HardLinkFile.db'),
+ self.hard_link_image_db: os.path.join(db_dir, 'HardLinkImage.db'),
+ self.hard_link_video_db: os.path.join(db_dir, 'HardLinkVideo.db'),
+ self.open_contact_db: os.path.join(db_dir, 'OpenIMContact.db'),
+ self.open_media_db: os.path.join(db_dir, 'OpenIMMedia.db'),
+ self.open_msg_db: os.path.join(db_dir, 'OpenIMMsg.db'),
+ self.public_msg_db: os.path.join(db_dir, 'PublicMsg.db'),
+ }
+
+ def merge_task(db_instance, db_path):
+ """执行单个数据库的合并任务"""
+ db_instance.merge(db_path)
+
+ # 使用 ThreadPoolExecutor 进行多线程合并
+ with concurrent.futures.ThreadPoolExecutor() as executor:
+ futures = {executor.submit(merge_task, db, path): (db, path) for db, path in merge_tasks.items()}
+
+ # 等待所有任务完成
+ for future in concurrent.futures.as_completed(futures):
+ db, path = futures[future]
+ try:
+ future.result() # 这里会抛出异常(如果有的话)
+ print(f"成功合并数据库: {path}")
+ except Exception as e:
+ print(f"合并 {path} 失败: {e}")
diff --git a/wxManager/manager_v4.py b/wxManager/manager_v4.py
new file mode 100644
index 0000000..5acec81
--- /dev/null
+++ b/wxManager/manager_v4.py
@@ -0,0 +1,478 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2024/12/11 20:43
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-manager_v4.py
+@Description :
+"""
+import concurrent
+import os
+from concurrent.futures import ProcessPoolExecutor, as_completed, ThreadPoolExecutor
+from datetime import date, datetime
+from multiprocessing import Pool, cpu_count
+from typing import Tuple, List, Any
+
+import zstandard as zstd
+
+from wxManager import MessageType
+from wxManager.db_v4.biz_message import BizMessageDB
+from wxManager.db_v4.emotion import EmotionDB
+from wxManager.db_v4.media import MediaDB
+from wxManager.db_v4 import ContactDB, HeadImageDB, SessionDB, MessageDB, HardLinkDB
+from wxManager.db_main import DataBaseInterface, Context
+from wxManager.model.contact import Contact, ContactType, Person
+from wxManager.model import Me
+from wxManager.parser.util.protocbuf.roomdata_pb2 import ChatRoomData
+from wxManager.parser.wechat_v4 import FACTORY_REGISTRY, Singleton
+from wxManager.log import logger
+from wxManager.parser.util.protocbuf import contact_pb2
+from google.protobuf.json_format import MessageToDict
+
+
+def decompress(data):
+ dctx = zstd.ZstdDecompressor() # 创建解压对象
+ x = dctx.decompress(data)
+ return x.decode('utf-8')
+
+
+def parser_messages(messages, username, db_dir=''):
+ context = DataBaseV4()
+ context.init_database(db_dir)
+ if username.endswith('@chatroom'):
+ contacts = context.get_chatroom_members(username)
+ else:
+ contacts = {
+ Me().wxid: context.get_contact_by_username(Me().wxid),
+ username: context.get_contact_by_username(username)
+ }
+ # FACTORY_REGISTRY[-1].set_contacts(contacts) # 不知道为什么用对象修改类属性每个实例对象的contacts不一样
+ Singleton.set_contacts(contacts)
+
+ for message in messages:
+ type_ = message[2]
+ if type_ not in FACTORY_REGISTRY:
+ type_ = -1
+ yield FACTORY_REGISTRY[type_].create(message, username, context)
+
+
+def _process_messages_batch(messages_batch, username, db_dir) -> List:
+ """Helper function to process a batch of messages."""
+ processed = []
+ for message in parser_messages(messages_batch, username, db_dir):
+ processed.append(message)
+ return processed
+
+
+class DataBaseV4(DataBaseInterface):
+ def __init__(self):
+ super().__init__()
+ self.db_dir = ''
+ self.chatroom_members_map = {}
+ self.contacts_map = {}
+
+ # V4
+ self.contact_db = ContactDB('contact/contact.db')
+ self.head_image_db = HeadImageDB('head_image/head_image.db')
+ self.session_db = SessionDB('session/session.db')
+ self.message_db = MessageDB('message/message_0.db', is_series=True)
+ self.biz_message_db = BizMessageDB('message/biz_message_0.db', is_series=True)
+ self.media_db = MediaDB('message/media_0.db', is_series=True)
+ self.hardlink_db = HardLinkDB('hardlink/hardlink.db')
+ self.emotion_db = EmotionDB('emoticon/emoticon.db')
+
+ def init_database(self, db_dir=''):
+ Me().load_from_json(os.path.join(db_dir, 'info.json')) # 加载自己的信息
+ # print('初始化数据库', db_dir)
+ self.db_dir = db_dir
+ flag = True
+ flag &= self.contact_db.init_database(db_dir)
+ flag &= self.head_image_db.init_database(db_dir)
+ flag &= self.session_db.init_database(db_dir)
+ flag &= self.message_db.init_database(db_dir)
+ flag &= self.biz_message_db.init_database(db_dir)
+ flag &= self.media_db.init_database(db_dir)
+ flag &= self.hardlink_db.init_database(db_dir)
+ flag &= self.emotion_db.init_database(db_dir)
+ return flag
+
+ def close(self):
+ pass
+
+ # self.head_image_db.close()
+ # self.contact_db.close()
+
+ def get_session(self):
+ """
+ 获取聊天会话窗口,在聊天界面显示
+ @return:
+ """
+ return self.session_db.get_session()
+
+ def get_messages(
+ self,
+ username_: str,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None,
+ ):
+ # todo 改成yield进行操作,多进程处理加快速度
+ import time
+ st = time.time()
+ logger.error(f'开始获取聊天记录:{st}')
+ res = []
+
+ # messages = self.message_db.get_messages_by_username(username_, time_range)*20
+ # # for messages in self.message_db.get_messages_by_username(username_, time_range):
+ # for messages_ in messages:
+ # for message in parser_messages(messages_, username_, self.db_dir):
+ # res.append(message)
+
+ def split_list(lst, n):
+ k, m = divmod(len(lst), n)
+ return [lst[i * k + min(i, m):(i + 1) * k + min(i + 1, m)] for i in range(n)]
+
+ #
+ # # # Step 1: Retrieve raw message batches
+ if username_.startswith('gh_'):
+ messages = self.biz_message_db.get_messages_by_username(username_, time_range)
+ else:
+ messages = self.message_db.get_messages_by_username(username_, time_range)
+
+ if len(messages) < 20000:
+ for message in parser_messages(messages, username_, self.db_dir):
+ res.append(message)
+ else:
+ raw_message_batches = split_list(messages, len(messages) // 10000 + 1)
+ #
+ # # Step 2: Use multiprocessing to process the message batches
+ # res = []
+ # for batch in raw_message_batches:
+ # print(len(batch))
+
+ with ProcessPoolExecutor(max_workers=min(len(raw_message_batches), 16)) as executor:
+ # Submit tasks
+ future_to_batch = {
+ executor.submit(_process_messages_batch, batch, username_, self.db_dir): batch
+ for batch in raw_message_batches
+ }
+
+ # Collect results
+ for future in future_to_batch.keys():
+ res.extend(future.result())
+
+ et = time.time()
+ logger.error(f'获取聊天记录完成:{et}')
+ logger.error(f'获取聊天记录耗时:{et - st:.2f}s/{len(res)}条消息 {username_}')
+ res.sort()
+ return res
+
+ def get_messages_by_num(self, username, start_sort_seq, msg_num=20):
+ """
+ 获取小于start_sort_seq的msg_num个消息
+ @param username:
+ @param start_sort_seq:
+ @param msg_num:
+ @return: messages, 最后一条消息的start_sort_seq
+ """
+ result = []
+ if username.startswith('gh_'):
+ messages = self.biz_message_db.get_messages_by_num(username, start_sort_seq, msg_num)
+ else:
+ messages = self.message_db.get_messages_by_num(username, start_sort_seq, msg_num)
+ for messages in messages:
+ for message in parser_messages(messages, username, self.db_dir):
+ result.append(message)
+ result.sort(reverse=True)
+ res = result[:msg_num]
+ return res, res[-1].sort_seq if res else 0
+
+ def get_message_by_server_id(self, username, server_id):
+ """
+ 获取小于start_sort_seq的msg_num个消息
+ @param username:
+ @param server_id:
+ @return: messages, 最后一条消息的start_sort_seq
+ """
+ message = self.message_db.get_message_by_server_id(username, server_id)
+ if message:
+ messages_iter = parser_messages([message], username, self.db_dir)
+ return next(messages_iter)
+ return None
+
+ def get_messages_by_type(
+ self,
+ username_,
+ type_: MessageType,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None,
+ ):
+ def split_list(lst, n):
+ k, m = divmod(len(lst), n)
+ return [lst[i * k + min(i, m):(i + 1) * k + min(i + 1, m)] for i in range(n)]
+
+ res = []
+ # # # Step 1: Retrieve raw message batches
+ if username_.startswith('gh_'):
+ messages = self.biz_message_db.get_messages_by_type(username_, time_range)
+ else:
+ messages = self.message_db.get_messages_by_type(username_, type_, time_range)
+
+ if len(messages) < 20000:
+ for message in parser_messages(messages, username_, self.db_dir):
+ res.append(message)
+ else:
+ raw_message_batches = split_list(messages, len(messages) // 10000 + 1)
+ with ProcessPoolExecutor(max_workers=min(len(raw_message_batches), 16)) as executor:
+ # Submit tasks
+ future_to_batch = {
+ executor.submit(_process_messages_batch, batch, username_, self.db_dir): batch
+ for batch in raw_message_batches
+ }
+ # Collect results
+ for future in future_to_batch.keys():
+ res.extend(future.result())
+ res.sort()
+ return res
+
+ def get_messages_calendar(self, username_: str):
+ if username_.startswith('gh_'):
+ return self.biz_message_db.get_messages_calendar(username_)
+ else:
+ return self.message_db.get_messages_calendar(username_)
+
+ def get_chatted_top_contacts(
+ self,
+ time_range: Tuple[int | float | str | date, int | float | str | date] = None,
+ contain_chatroom=False,
+ top_n=10
+ ) -> list:
+ return []
+
+ def get_emoji_url(self, md5: str, thumb: bool = False) -> str | bytes:
+ return self.emotion_db.get_emoji_url(md5, thumb)
+
+ # 图片、视频、文件
+ def get_file(self, md5: bytes | str) -> str:
+ return self.hardlink_db.get_file(md5)
+
+ def get_image(self, content, bytesExtra, up_dir="", md5=None, thumb=False, talker_username='') -> str:
+ return self.hardlink_db.get_image(content, bytesExtra, up_dir, md5, thumb, talker_username)
+
+ def get_video(self, content, bytesExtra, md5=None, thumb=False):
+ return self.hardlink_db.get_video(md5, thumb)
+
+ # 语音
+ def get_audio(self, reserved0, output_path, open_im=False, filename=''):
+ return self.media_db.get_audio(reserved0, output_path, filename)
+
+ def get_media_buffer(self, server_id, is_open_im=False) -> bytes:
+ return self.media_db.get_media_buffer(server_id)
+
+ def get_audio_path(self, reserved0, output_path, filename=''):
+ return self.media_db.get_audio_path(reserved0, output_path, filename)
+
+ def get_audio_text(self, msgSvrId):
+ return ''
+
+ def update_audio_to_text(self):
+ # todo
+ return
+
+ # 语音结束
+
+ # 联系人
+
+ def get_avatar_buffer(self, username) -> bytes:
+ return self.head_image_db.get_avatar_buffer(username)
+
+ def create_contact(self, contact_info_list) -> Person:
+ wxid, local_type, flag = contact_info_list[0], contact_info_list[2], contact_info_list[3]
+ nickname = contact_info_list[5]
+ remark = contact_info_list[4]
+ if not nickname and wxid.endswith('@chatroom'):
+ nickname = self._get_chatroom_name(contact_info_list[0])
+ if not remark:
+ remark = nickname
+ gender = '未知'
+ signature = ''
+ label_list = []
+ region = ('', '', '')
+ if not (wxid.endswith('@openim') or wxid.endswith('@chatroom')):
+ try:
+ # 创建顶级消息对象
+ message = contact_pb2.ContactInfo()
+ # 解析二进制数据
+ message.ParseFromString(contact_info_list[10])
+ # 转换为 JSON 格式
+ detail = MessageToDict(message)
+ gender_code = detail.get('gender', 0)
+ if gender_code == 1:
+ gender = '男'
+ elif gender_code == 2:
+ gender = '女'
+ label_list = detail.get('labelList', '').strip(',').split(',')
+ signature = detail.get('signature', '')
+ region = (detail.get('country', ''), detail.get('province', ''), detail.get('city', ''))
+ label_list = self.contact_db.get_labels(detail.get('labelList')).split(',')
+ except:
+ pass
+ # logger.error(f'{wxid} {contact_info_list[5]}联系人解析失败\n{contact_info_list[10]}')
+ contact = Contact(
+ wxid=contact_info_list[0],
+ remark=remark,
+ alias=contact_info_list[1],
+ nickname=nickname,
+ small_head_img_url=contact_info_list[8],
+ big_head_img_url=contact_info_list[9],
+ flag=contact_info_list[3],
+ gender=gender,
+ signature=signature,
+ label_list=label_list,
+ region=region
+ )
+
+ def is_nth_bit_set(number, n):
+ # 左移 1 到第 n 位
+ mask = 1 << n
+ # 使用位与运算判断第 n 位
+ return (number & mask) != 0
+
+ if local_type == 1:
+ contact.type = ContactType.Normal
+ if wxid.startswith('gh_'):
+ contact.type |= ContactType.Public
+ elif wxid.endswith('@chatroom'):
+ contact.type |= ContactType.Chatroom
+ elif local_type == 2:
+ contact.type = ContactType.Chatroom
+ elif local_type == 3:
+ contact.type = ContactType.Stranger
+ elif local_type == 5:
+ contact.type = ContactType.OpenIM
+ if is_nth_bit_set(flag, 6):
+ contact.type |= ContactType.Star
+ if is_nth_bit_set(flag, 11):
+ contact.type |= ContactType.Sticky
+
+ if local_type == 10086:
+ contact.type = ContactType.Unknown
+ contact.is_unknown = True
+ return contact
+
+ def get_contacts(self) -> List[Person]:
+ contacts = []
+ contact_lists = self.contact_db.get_contacts()
+ for contact_info_list in contact_lists:
+ if contact_info_list:
+ contact = self.create_contact(contact_info_list)
+ contacts.append(contact)
+ return contacts
+
+ def set_remark(self, username: str, remark) -> bool:
+ if username in self.contacts_map:
+ self.contacts_map[username].remark = remark
+ return self.contact_db.set_remark(username, remark)
+
+ def set_avatar_buffer(self, username, avatar_path):
+ return self.head_image_db.set_avatar_buffer(username, avatar_path)
+
+ def get_contact_by_username(self, wxid: str) -> Person:
+ contact_info_list = self.contact_db.get_contact_by_username(wxid)
+ if contact_info_list:
+ contact = self.create_contact(contact_info_list)
+ return contact
+ else:
+ contact = Contact(
+ wxid=wxid,
+ nickname=wxid,
+ remark=wxid
+ )
+ return contact
+
+ def get_chatroom_members(self, chatroom_name) -> dict[Any, Person] | Any:
+ """
+ 获取群成员
+ @param chatroom_name:
+ @return:
+ """
+ if chatroom_name in self.chatroom_members_map:
+ return self.chatroom_members_map[chatroom_name]
+ result = {}
+ chatroom = self.contact_db.get_chatroom_info(chatroom_name)
+
+ if chatroom is None:
+ return result
+ # 解析RoomData数据
+ parsechatroom = ChatRoomData()
+ parsechatroom.ParseFromString(chatroom[1])
+ # 群成员数据放入字典存储
+ for mem in parsechatroom.members:
+ contact = self.get_contact_by_username(mem.wxID)
+ if contact:
+ if mem.displayName:
+ contact.remark = mem.displayName
+ result[contact.wxid] = contact
+ self.chatroom_members_map[chatroom_name] = result
+ return result
+
+ def _get_chatroom_name(self, wxid):
+ chatroom = self.contact_db.get_chatroom_info(wxid)
+
+ if chatroom is None:
+ return ''
+ # 解析RoomData数据
+ parsechatroom = ChatRoomData()
+ parsechatroom.ParseFromString(chatroom[1])
+ chatroom_name = ''
+ # 群成员数据放入字典存储
+ for mem in parsechatroom.members[:5]:
+ if mem.wxID == Me().wxid:
+ continue
+ if mem.displayName:
+ chatroom_name += f'{mem.displayName}、'
+ else:
+ contact = self.get_contact_by_username(mem.wxID)
+ chatroom_name += f'{contact.remark}、'
+ return chatroom_name.rstrip('、')
+
+ # 联系人结束
+
+ def add_audio_txt(self, msgSvrId, text):
+ return self.audio_to_text.add_text(msgSvrId, text)
+
+ def get_favorite_items(self, time_range):
+ return self.favorite_db.get_items(time_range)
+
+ def merge(self, db_dir):
+ """
+ 批量将db_path中的数据合入到数据库中
+ @param db_path:
+ @return:
+ """
+ merge_tasks = {
+ self.head_image_db: os.path.join(db_dir, 'head_image', 'head_image.db'),
+ self.hardlink_db: os.path.join(db_dir, 'hardlink', 'hardlink.db'),
+ self.media_db: os.path.join(db_dir, 'message', 'media_0.db'),
+ self.contact_db: os.path.join(db_dir, 'contact', 'contact.db'),
+ self.emotion_db: os.path.join(db_dir, 'emoticon', 'emoticon.db'),
+ self.message_db: os.path.join(db_dir, 'message', 'message_0.db'),
+ self.biz_message_db: os.path.join(db_dir, 'message', 'biz_message_0.db'),
+ self.session_db: os.path.join(db_dir, 'session', 'session.db'),
+ }
+
+ def merge_task(db_instance, db_path):
+ """执行单个数据库的合并任务"""
+ db_instance.merge(db_path)
+
+ # 使用 ThreadPoolExecutor 进行多线程合并
+ with concurrent.futures.ThreadPoolExecutor() as executor:
+ futures = {executor.submit(merge_task, db, path): (db, path) for db, path in merge_tasks.items()}
+
+ # 等待所有任务完成
+ for future in concurrent.futures.as_completed(futures):
+ db, path = futures[future]
+ try:
+ future.result() # 这里会抛出异常(如果有的话)
+ print(f"成功合并数据库: {path}")
+ except Exception as e:
+ print(f"合并 {path} 失败: {e}")
diff --git a/wxManager/merge.py b/wxManager/merge.py
new file mode 100644
index 0000000..a6452cf
--- /dev/null
+++ b/wxManager/merge.py
@@ -0,0 +1,183 @@
+import os
+import sqlite3
+import traceback
+
+from wxManager.log import logger
+
+
+def table_exists(conn, table_name):
+ """检查表是否存在"""
+ cursor = conn.cursor()
+ cursor.execute("SELECT count(*) FROM sqlite_master WHERE type='table' AND name=?", (table_name,))
+ return cursor.fetchone()[0] > 0
+
+
+def get_create_statements(conn, table_name, object_type):
+ """获取指定表的 CREATE TABLE 或 CREATE INDEX 语句"""
+ cursor = conn.cursor()
+ cursor.execute(f"SELECT sql FROM sqlite_master WHERE type='{object_type}' AND tbl_name=?", (table_name,))
+ return [row[0] for row in cursor.fetchall() if row[0]] # 过滤掉 None 值
+
+
+def increase_data(db_path, src_cursor, src_conn, table_name, col_name, col_index=-1, exclude_first_column=False):
+ """
+ 将db_path数据库的内容增量写入connect数据库中
+ @param db_path: 新的数据库路径
+ @param src_cursor: 待写入数据库游标
+ @param src_conn: 待写入数据库连接
+ @param table_name: 待写入的表名
+ @param col_name: 根据该列进行判断是否是新增数据
+ @param col_index: 待写入的列号
+ @param exclude_first_column: 是否不考虑低一列(针对第一列是自增ID的表)
+ @return:
+ """
+ if not (os.path.exists(db_path) or os.path.isfile(db_path)):
+ print(f'{db_path} 不存在')
+ return
+ if not src_cursor or not src_conn:
+ print(f'{db_path} 数据库连接无效,增量解析失败')
+ return
+ tgt_conn = sqlite3.connect(db_path)
+ tgt_cur = tgt_conn.cursor()
+
+ try:
+ if not table_exists(tgt_conn, table_name):
+ # 复制表结构
+ create_table_sql = get_create_statements(src_conn, table_name, "table")
+ if create_table_sql:
+ tgt_conn.execute(create_table_sql[0]) # 执行 CREATE TABLE 语句
+ print(f"表 {table_name} 结构已复制")
+
+ # 复制索引
+ create_index_sql_list = get_create_statements(src_conn, table_name, "index")
+ for create_index_sql in create_index_sql_list:
+ tgt_conn.execute(create_index_sql) # 执行 CREATE INDEX 语句
+ print(f"索引已复制: {create_index_sql}")
+ # 获取列名
+ src_cursor.execute(f"PRAGMA table_info({table_name})")
+ columns_info = src_cursor.fetchall()
+ if columns_info and exclude_first_column:
+ columns_info = columns_info[1:]
+ column_names = [info[1] for info in columns_info]
+ num_columns = len(column_names)
+
+ if col_index == -1:
+ try:
+ col_index = column_names.index(col_name)
+ except ValueError:
+ print(f"错误: 列 {col_name} 在表 {table_name} 中不存在")
+ return
+ # 从数据库B中选择主键不在数据库A中的行
+ query = f"""
+ SELECT {', '.join([name for name in column_names])}
+ FROM {table_name}
+ """
+ tgt_cur.execute(query)
+ target_rows = tgt_cur.fetchall()
+ query = f'''
+ SELECT {col_name}
+ FROM {table_name}
+ '''
+ src_cursor.execute(query)
+ source_rows = src_cursor.fetchall()
+
+ source_rows = {r[0] for r in source_rows}
+ rows_to_insert = [row for row in target_rows if row[col_index] not in source_rows]
+
+ if rows_to_insert:
+ insert_query = f"""
+ INSERT INTO {table_name} ({', '.join(column_names)})
+ VALUES ({', '.join(['?'] * num_columns)})
+ """
+ src_cursor.executemany(insert_query, rows_to_insert)
+ src_conn.commit()
+ print(f"{len(rows_to_insert)} 行已插入到 {table_name} 表中")
+ else:
+ print(f"没有需要插入的数据,{table_name} 表已是最新")
+ except sqlite3.Error as e:
+ print(f"{db_path} 数据库操作错误: {e}")
+ finally:
+ tgt_cur.close()
+ tgt_conn.close()
+
+
+def increase_update_data(db_path, src_cur, src_conn, table_name, col_name, col_index=-1, exclude_first_column=False):
+ """
+ 将 db_path 数据库的内容增量写入 src_conn 连接的数据库,如果有冲突则删除旧数据并更新
+ :param db_path: 目标数据库文件路径
+ :param src_cur: 源数据库游标
+ :param src_conn: 源数据库连接
+ :param table_name: 需要同步的表名
+ :param col_name: 用于匹配的列名
+ :param col_index: 指定列的索引(默认为 -1,即自动检测)
+ :param exclude_first_column: 是否排除第一列
+ """
+ if not (os.path.exists(db_path) or os.path.isfile(db_path)):
+ print(f'{db_path} 不存在')
+ return
+
+ tgt_conn = sqlite3.connect(db_path)
+ tgt_cur = tgt_conn.cursor()
+ try:
+ if not table_exists(tgt_conn, table_name):
+ # 复制表结构
+ create_table_sql = get_create_statements(src_conn, table_name, "table")
+ if create_table_sql:
+ tgt_conn.execute(create_table_sql[0]) # 执行 CREATE TABLE 语句
+ print(f"表 {table_name} 结构已复制")
+
+ # 复制索引
+ create_index_sql_list = get_create_statements(src_conn, table_name, "index")
+ for create_index_sql in create_index_sql_list:
+ tgt_conn.execute(create_index_sql) # 执行 CREATE INDEX 语句
+ print(f"索引已复制: {create_index_sql}")
+
+ # 获取列名
+ src_cur.execute(f"PRAGMA table_info({table_name})")
+ columns_info = src_cur.fetchall()
+ if exclude_first_column:
+ columns_info = columns_info[1:]
+
+ column_names = [info[1] for info in columns_info]
+ num_columns = len(column_names)
+
+ if col_index == -1:
+ try:
+ col_index = column_names.index(col_name)
+ except ValueError:
+ print(f"错误: 列 {col_name} 在 {table_name} 表中不存在。")
+ return
+
+ # 查询目标数据库的数据
+ query = f"SELECT {', '.join(column_names)} FROM {table_name}"
+ tgt_cur.execute(query)
+ source_rows = set(tgt_cur.fetchall()) # 使用 set() 加速查询
+
+ # 查询源数据库已有的数据
+ src_cur.execute(query)
+ existing_rows = set(src_cur.fetchall())
+
+ # 需要删除并重新插入的行
+ rows_to_insert = [row for row in source_rows if row not in existing_rows]
+
+ if rows_to_insert:
+ delete_query = f"DELETE FROM {table_name} WHERE {col_name} = ?"
+ src_cur.executemany(delete_query, [(row[col_index],) for row in rows_to_insert])
+ src_conn.commit()
+
+ insert_query = f"INSERT INTO {table_name} ({', '.join(column_names)}) VALUES ({', '.join(['?'] * num_columns)})"
+ src_cur.executemany(insert_query, rows_to_insert)
+ src_conn.commit()
+ print(f"{len(rows_to_insert)} 行已更新到 {table_name} 表中。")
+ else:
+ print(f"没有需要插入的数据,{table_name} 表已是最新。")
+ except sqlite3.Error as e:
+ print(f"{db_path} 数据库操作错误: {e}")
+ finally:
+ tgt_cur.close()
+ tgt_conn.close()
+
+
+if __name__ == "__main__":
+ # 源数据库文件列表
+ source_databases = ["Msg0/MSG2.db", "Msg/MSG2.db", "Msg/MSG3.db"]
diff --git a/wxManager/model/__init__.py b/wxManager/model/__init__.py
new file mode 100644
index 0000000..4f5de09
--- /dev/null
+++ b/wxManager/model/__init__.py
@@ -0,0 +1,18 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2024/12/10 21:02
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-__init__.py.py
+@Description : 定义抽象的数据模型如聊天记录,联系人或基类
+"""
+
+from .message import Message, MessageType, TextMessage, ImageMessage, FileMessage, VideoMessage, AudioMessage, \
+ EmojiMessage, QuoteMessage, MergedMessage, LinkMessage, PositionMessage
+from .db_model import DataBaseBase
+from .contact import Person, Contact, OpenIMContact, Me
+
+if __name__ == '__main__':
+ pass
diff --git a/wxManager/model/contact.py b/wxManager/model/contact.py
new file mode 100644
index 0000000..5795943
--- /dev/null
+++ b/wxManager/model/contact.py
@@ -0,0 +1,181 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2024/12/10 21:03
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-contact.py
+@Description : 定义各种联系人
+"""
+from dataclasses import dataclass
+import json
+import os
+
+import os.path
+import re
+from enum import Enum
+from typing import Dict, List, Tuple
+
+
+def remove_illegal_characters(text):
+ # 去除 ASCII 控制字符(除了合法的制表符、换行符和回车符)
+ illegal_chars = re.compile(r'[\x00-\x08\x0B\x0C\x0E-\x1F]')
+ return illegal_chars.sub('', text)
+
+
+class Gender:
+ MAN = 1
+ WOMAN = 2
+ UNKNOWN = 0
+
+
+class ContactType:
+ Sticky = 1 << 0 # 1 置顶
+ Star = 1 << 1 # 2 星标
+ Chatroom = 1 << 2 # 4 群聊
+ Normal = 1 << 3 # 8 普通联系人
+ Stranger = 1 << 4 # 16 陌生人
+ OpenIM = 1 << 5 # 32 企业微信联系人
+ Public = 1 << 6 # 64 公众号
+ Unknown = 1 << 8 # 已解散或者退出的群聊
+
+
+@dataclass
+class Person:
+ wxid: str
+ remark: str
+ nickname: str
+ alias: str = ''
+ small_head_img_url: str = ''
+ small_head_img_blog: bytes = b''
+ big_head_img_url: str = ''
+ type: int = ContactType.Normal
+ flag: int = 0
+ gender: str = '未知'
+ signature: str = ''
+ label_list: List[str] = None
+ region: Tuple[str, str, str] = ('', '', '') # 地区 (国家,省份,城市)
+
+ def is_chatroom(self):
+ return self.wxid.endswith('@chatroom') # 是否是群聊
+
+ def is_public(self):
+ return self.wxid.startswith('gh') # 是否是公众号
+
+ def is_open_im(self):
+ return self.wxid.endswith('@openim') # 是否是企业微信联系人
+
+ def label_name(self):
+ if self.label_list:
+ return ','.join(self.label_list)
+ else:
+ return ''
+
+ def __str__(self):
+ return f'''
+wxid:{self.wxid}
+alias:{self.alias}
+nickname:{self.nickname}
+gender:{self.gender}
+region:{self.region}
+signature:{self.signature}
+'''
+
+ def to_json(self):
+ return {
+ 'wxid': self.wxid,
+ 'alias': self.alias,
+ 'nickname': self.nickname,
+ 'remark': self.remark,
+ 'type': self.type,
+ 'gender': self.gender,
+ }
+
+
+@dataclass
+class Contact(Person):
+ is_unknown: bool = False # 是否是联系人表中没有的数据
+ # def __init__(self, contact_info: Dict):
+ # super().__init__()
+ # self.wxid: str = contact_info.get('UserName')
+ # self.is_chatroom = self.wxid.__contains__('@chatroom') # 是否是群聊
+ # self.is_open_im = self.wxid.endswith('@openim') # 是否是企业微信联系人
+ # self.is_public = self.wxid.startswith('gh')
+ # self.is_unknown = False # 是否是联系人表中没有的数据
+ # if self.wxid.endswith('@stranger'):
+ # self.wxid = self.wxid[-16:]
+ # self.remark = contact_info.get('Remark')
+ # # Alias,Type,Remark,NickName,PYInitial,RemarkPYInitial,ContactHeadImgUrl.smallHeadImgUrl,ContactHeadImgUrl,bigHeadImgUrl
+ # self.alias = contact_info.get('Alias')
+ # self.nickname = remove_illegal_characters(contact_info.get('NickName'))
+ # if not self.nickname:
+ # self.nickname = '未命名'
+ # self.wording = contact_info.get('wording') # 企业联系人的企业名
+ # if not self.remark:
+ # self.remark = self.nickname
+ # if self.is_open_im:
+ # self.remark += f'@{self.wording}'
+ # self.remark = re.sub(r'[\\/:*?"<>|\s\.]', '_', self.remark)
+ # self.small_head_img_url = contact_info.get('smallHeadImgUrl')
+ # self.big_head_img_url = contact_info.get('bigHeadImgUrl')
+ # self.small_head_img_blog = b''
+ #
+ # self.type = contact_info.get('Type', 0)
+ # self.flag = contact_info.get('flag', 0)
+ #
+ # self.gender = contact_info.get('gender', '')
+ # self.label_name = contact_info.get('label_name', '') # 联系人的标签分类
+ # self.region = contact_info.get('region', ('', '', ''))
+ # self.signature = contact_info.get('signature', '')
+
+
+class OpenIMContact(Person):
+ def __init__(self, contact_info: Dict):
+ super().__init__()
+
+
+def singleton(cls):
+ _instance = {}
+
+ def inner():
+ if cls not in _instance:
+ _instance[cls] = cls()
+ return _instance[cls]
+
+ return inner
+
+
+@singleton
+@dataclass
+class Me:
+ def __init__(self):
+ self.wxid = 'wxid_00112233'
+ self.wx_dir = ''
+ self.name = ''
+ self.mobile = ''
+ self.small_head_img_url = ''
+ self.nickname = self.name
+ self.remark = self.nickname
+ self.xor_key = -1
+
+ def to_json(self) -> dict:
+ return {
+ 'username': self.wxid,
+ 'nickname': self.name,
+ 'wx_dir': self.wx_dir,
+ 'xor_key': self.xor_key
+ }
+
+ def load_from_json(self, json_file):
+ if os.path.exists(json_file):
+ with open(json_file, 'r', encoding='utf-8') as f:
+ dic = json.load(f)
+ self.name = dic.get('nickname', '')
+ self.wxid = dic.get('username', '')
+ self.wx_dir = dic.get('wx_dir', '')
+ self.xor_key = dic.get('xor_key', '')
+
+ def save_to_json(self, json_file):
+ with open(json_file, 'w', encoding='utf-8') as f:
+ json.dump(self.to_json(), f, ensure_ascii=False, indent=4)
diff --git a/wxManager/model/db_model.py b/wxManager/model/db_model.py
new file mode 100644
index 0000000..8dacd43
--- /dev/null
+++ b/wxManager/model/db_model.py
@@ -0,0 +1,92 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2024/12/5 22:47
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-db_model.py
+@Description :
+"""
+import os
+import sqlite3
+import traceback
+
+
+class DataBaseBase:
+ def __init__(self, db_file_name, is_series=False):
+ self.DB = None
+ self.cursor = None
+ self.open_flag = False
+ self.db_file_name = db_file_name
+ self.is_series = is_series # 是否是一系列数据库,例如MSG0、MSG1、MSG2······
+ self.db_dir = ''
+
+ def init_database(self, db_dir=''):
+ self.db_dir = db_dir
+ db_path = os.path.join(db_dir, self.db_file_name)
+ if not os.path.exists(db_path):
+ return False
+ db_file_name = self.db_file_name
+ self.db_file_name = []
+ if self.is_series:
+ self.DB = []
+ self.cursor = []
+ for i in range(100):
+ new_file_name = db_file_name.replace('0', f'{i}')
+ db_path = os.path.join(db_dir, new_file_name)
+ if os.path.exists(db_path):
+ self.db_file_name.append(os.path.basename(new_file_name))
+ # print('初始化数据库:', db_path)
+ DB = sqlite3.connect(db_path, check_same_thread=False)
+ cursor = DB.cursor()
+ self.DB.append(DB)
+ self.cursor.append(cursor)
+ self.open_flag = True
+ else:
+ if os.path.exists(db_path):
+ self.DB = sqlite3.connect(db_path, check_same_thread=False)
+ # '''创建游标'''
+ self.cursor = self.DB.cursor()
+ self.open_flag = True
+ # print('初始化数据库完成:', db_path)
+ self.self_init()
+ return True
+
+ def self_init(self):
+ pass
+
+ def commit(self):
+ if self.is_series:
+ for db in self.DB:
+ db.commit()
+ else:
+ self.DB.commit()
+
+ def execute(self, sql, args):
+ self.cursor.execute(sql, args)
+
+ def close(self):
+ if self.open_flag:
+ try:
+ self.open_flag = False
+ if self.is_series:
+ for db in self.DB:
+ db.close()
+ else:
+ if self.DB:
+ self.DB.close()
+ except:
+ print(traceback.format_exc())
+ finally:
+ pass
+
+ def merge(self, db_path):
+ pass
+
+ def __del__(self):
+ self.close()
+
+
+if __name__ == '__main__':
+ pass
diff --git a/wxManager/model/message.py b/wxManager/model/message.py
new file mode 100644
index 0000000..508928a
--- /dev/null
+++ b/wxManager/model/message.py
@@ -0,0 +1,653 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2024/12/10 21:03
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-message.py
+@Description :
+"""
+from dataclasses import dataclass
+from typing import List
+from datetime import datetime
+
+import xmltodict
+
+
+class MessageType:
+ Unknown = -1
+ Text = 1
+ Text2 = 2
+ Image = 3
+ Audio = 34
+ BusinessCard = 42
+ Video = 43
+ Emoji = 47
+ Position = 48
+ Voip = 50
+ OpenIMBCard = 66
+ System = 10000
+ File = 25769803825
+ LinkMessage = 21474836529
+ LinkMessage2 = 292057776177
+ Music = 12884901937
+ LinkMessage4 = 4294967345
+ LinkMessage5 = 326417514545
+ LinkMessage6 = 17179869233
+ RedEnvelope = 8594229559345
+ Transfer = 8589934592049
+ Quote = 244813135921
+ MergedMessages = 81604378673
+ Applet = 141733920817
+ Applet2 = 154618822705
+ WeChatVideo = 219043332145
+ FavNote = 103079215153
+ Pat = 266287972401
+
+ @classmethod
+ def name(cls, type_):
+ type_name_map = {
+ cls.Unknown: '未知类型',
+ cls.Text: '文本',
+ cls.Image: '图片',
+ cls.Video: '视频',
+ cls.Audio: '语音',
+ cls.Emoji: '表情包',
+ cls.Voip: '音视频通话',
+ cls.File: '文件',
+ cls.Position: '位置分享',
+ cls.LinkMessage: '分享链接',
+ cls.LinkMessage2: '分享链接',
+ cls.LinkMessage4: '分享链接',
+ cls.LinkMessage5: '分享链接',
+ cls.LinkMessage6: '分享链接',
+ cls.RedEnvelope: '红包',
+ cls.Transfer: '转账',
+ cls.Quote: '引用消息',
+ cls.MergedMessages: '合并转发的聊天记录',
+ cls.Applet: '小程序',
+ cls.Applet2: '小程序',
+ cls.WeChatVideo: '视频号',
+ cls.Music: '音乐分享',
+ cls.FavNote: '收藏笔记',
+ cls.BusinessCard: '个人/公众号名片',
+ cls.OpenIMBCard: '企业微信名片',
+ cls.System: '系统消息',
+ cls.Pat: '拍一拍'
+ }
+ return type_name_map.get(type_, '未知类型')
+
+
+@dataclass
+class Message:
+ local_id: int # 消息ID
+ server_id: int # 消息的唯一ID
+ sort_seq: int # 排序用的id
+ timestamp: int # 发送秒级时间戳
+ str_time: str # 格式化时间 2024-12-01 12:00:00
+ type: MessageType # 消息类型(文本、图片、视频等)
+ talker_id: str # 聊天对象的wxid,好友的wxid或者群聊的wxid
+ is_sender: bool # 自己是否是发送者
+ sender_id: str # 消息发送者的ID
+ display_name: str # 消息发送者的对外展示的昵称(备注名,群昵称)
+ avatar_src: str # 消息发送者头像
+ status: int # 消息状态
+ xml_content: str # xml数据
+
+ def is_chatroom(self) -> bool:
+ return self.talker_id.endswith('@chatroom')
+
+ def to_json(self) -> dict:
+ try:
+ xml_dict = xmltodict.parse(self.xml_content)
+ except:
+ xml_dict = {}
+ return {
+ 'type': str(self.type),
+ 'is_send': self.is_sender,
+ 'timestamp': self.timestamp,
+ 'server_id': str(self.server_id),
+ 'display_name': self.display_name,
+ 'avatar_src': self.avatar_src,
+ 'xml_dict': xml_dict
+ }
+
+ def type_name(self):
+ # 获取消息类型的文字描述
+ return MessageType.name(self.type)
+
+ def to_text(self):
+ try:
+ return f'{self.type}\n{xmltodict.parse(self.xml_content)}'
+ except:
+ print(self.xml_content)
+ return f'{self.type}\n{self.xml_content}'
+
+ def __lt__(self, other):
+ return self.sort_seq < other.sort_seq
+
+
+@dataclass
+class TextMessage(Message):
+ # 文本消息
+ content: str
+
+ def to_text(self):
+ return self.content
+
+ def to_json(self) -> dict:
+ data = super().to_json()
+ data['text'] = self.content
+ return data
+
+
+@dataclass
+class QuoteMessage(TextMessage):
+ # 引用消息
+ quote_message: Message
+
+ def to_json(self) -> dict:
+ data = super().to_json()
+ data.update(
+ {
+ "text": self.content,
+ 'quote_server_id': f'{self.quote_message.server_id}',
+ 'quote_type': self.quote_message.type,
+ }
+ )
+ if self.quote_message.type == MessageType.Quote:
+ # 防止递归引用
+ data['quote_text'] = f'{self.quote_message.display_name}: {self.quote_message.content}'
+ else:
+ data['quote_text'] = f'{self.quote_message.display_name}: {self.quote_message.to_text()}'
+ return data
+
+ def to_text(self):
+ if self.quote_message.type == MessageType.Quote:
+ # 防止递归引用
+ return f'{self.content}\n引用:{self.quote_message.display_name}: {self.quote_message.content}'
+ else:
+ return f'{self.content}\n引用:{self.quote_message.display_name}: {self.quote_message.to_text()}'
+
+
+@dataclass
+class FileMessage(Message):
+ # 文件消息
+ path: str
+ md5: str
+ file_size: int
+ file_name: str
+ file_type: str
+
+ def to_json(self) -> dict:
+ data = super().to_json()
+ data.update(
+ {
+ 'path': self.path,
+ 'file_name': self.file_name,
+ 'file_size': self.file_size,
+ 'file_type': self.file_type
+ }
+ )
+ return data
+
+ def get_file_size(self, format_='MB'):
+ # 定义转换因子
+ units = {
+ 'B': 1,
+ 'KB': 1024,
+ 'MB': 1024 ** 2,
+ 'GB': 1024 ** 3,
+ }
+
+ # 将文件大小转换为指定格式
+ if format_ in units:
+ size_in_format = self.file_size / units[format_]
+ return f'{size_in_format:.2f} {format_}'
+ else:
+ raise ValueError(f'Unsupported format: {format_}')
+
+ def set_file_name(self, file_name=''):
+ if file_name:
+ self.file_name = file_name
+ return True
+ # 把时间戳转换为格式化时间
+ time_struct = datetime.fromtimestamp(self.timestamp) # 首先把时间戳转换为结构化时间
+ str_time = time_struct.strftime("%Y%m%d_%H%M%S") # 把结构化时间转换为格式化时间
+ str_time = f'{str_time}_{str(self.server_id)[:6]}'
+ if self.is_sender:
+ str_time += '_1'
+ else:
+ str_time += '_0'
+ self.file_name = str_time
+ return True
+
+ def to_text(self):
+ return f'【文件】{self.file_name} {self.get_file_size()} {self.path} {self.file_type} {self.md5}'
+
+
+@dataclass
+class ImageMessage(FileMessage):
+ # 图片消息
+ thumb_path: str
+
+ def to_json(self) -> dict:
+ data = super().to_json()
+ data['path'] = self.path
+ data['thumb_path'] = self.thumb_path
+ return data
+
+ def to_text(self):
+ return f'【图片】'
+
+
+@dataclass
+class EmojiMessage(ImageMessage):
+ # 表情包
+ url: str
+ thumb_url: str
+ description: str
+
+ def to_json(self) -> dict:
+ data = super().to_json()
+ data.update(
+ {
+ 'path': self.url,
+ 'desc': self.description
+ }
+ )
+ return data
+
+ def to_text(self):
+ return f'【表情包】 {self.description}'
+
+
+@dataclass
+class VideoMessage(FileMessage):
+ # 视频消息
+ thumb_path: str
+ duration: int
+ raw_md5: str
+
+ def to_text(self):
+ return '【视频】'
+
+ def to_json(self) -> dict:
+ data = super().to_json()
+ data.update(
+ {
+ 'path': self.path,
+ 'thumb_path': self.thumb_path,
+ 'duration': self.duration
+ }
+ )
+ return data
+
+
+@dataclass
+class AudioMessage(FileMessage):
+ # 语音消息
+ duration: int
+ audio_text: str
+
+ def set_file_name(self):
+ # 把时间戳转换为格式化时间
+ time_struct = datetime.fromtimestamp(self.timestamp) # 首先把时间戳转换为结构化时间
+ str_time = time_struct.strftime("%Y%m%d_%H%M%S") # 把结构化时间转换为格式化时间
+ str_time = f'{str_time}_{str(self.server_id)[:6]}'
+ if self.is_sender:
+ str_time += '_1'
+ else:
+ str_time += '_0'
+ self.file_name = str_time
+
+ def get_file_name(self):
+ return self.file_name
+
+ def to_json(self) -> dict:
+ data = super().to_json()
+ data.update(
+ {
+ 'path': self.path,
+ 'voice_to_text': self.audio_text,
+ 'duration': self.duration,
+ }
+ )
+ return data
+
+ def to_text(self):
+ # return f'{self.server_id}\n{self.type}\n{xmltodict.parse(self.xml_content)}'
+ return f'【语音】{self.audio_text}'
+
+
+@dataclass
+class LinkMessage(Message):
+ # 链接消息
+ href: str # 跳转链接
+ title: str # 标题
+ description: str # 描述/音乐作者
+ cover_path: str # 本地封面路径
+ cover_url: str # 封面地址
+ app_name: str # 应用名
+ app_icon: str # 应用logo
+ app_id: str # app ip
+
+ def to_text(self):
+ return f'''【分享链接】
+标题:{self.title}
+描述:{self.description}
+链接: {self.href}
+应用:{self.app_name}
+'''
+
+ def to_json(self) -> dict:
+ data = super().to_json()
+ data.update(
+ {
+ 'url': self.href,
+ 'title': self.title,
+ 'description': self.description,
+ 'cover_url': self.cover_url,
+ 'app_logo': self.app_icon,
+ 'app_name': self.app_name,
+ }
+ )
+ return data
+
+
+@dataclass
+class WeChatVideoMessage(Message):
+ # 视频号消息
+ url: str # 下载地址
+ publisher_nickname: str # 视频发布者昵称
+ publisher_avatar: str # 视频发布者头像
+ description: str # 视频描述
+ media_count: int # 视频个数
+ cover_path: str # 封面本地路径
+ cover_url: str # 封面网址
+ thumb_url: str # 缩略图
+ duration: int # 视频时长,单位(秒)
+ width: int # 视频宽度
+ height: int # 视频高度
+
+ def to_text(self):
+ return f'''【视频号】
+描述: {self.description}
+发布者: {self.publisher_nickname}
+'''
+
+ def to_json(self) -> dict:
+ data = super().to_json()
+ data.update(
+ {
+ 'url': self.url,
+ 'title': self.description,
+ 'cover_url': self.cover_url,
+ 'duration': self.duration,
+ 'publisher_nickname': self.publisher_nickname,
+ 'publisher_avatar': self.publisher_avatar
+ }
+ )
+ return data
+
+
+@dataclass
+class MergedMessage(Message):
+ # 合并转发的聊天记录
+ title: str
+ description: str
+ messages: List[Message] # 嵌套子消息
+ level: int # 嵌套层数
+
+ def to_text(self):
+ res = f'【合并转发的聊天记录】\n\n'
+ for message in self.messages:
+ res += f"{' ' * self.level * 4}- {message.str_time} {message.display_name}: {message.to_text()}\n"
+ return res
+
+ def to_json(self) -> dict:
+ data = super().to_json()
+ data.update(
+ {
+ 'title': self.title,
+ 'description': self.description,
+ 'messages': [msg.to_json() for msg in self.messages],
+ }
+ )
+ return data
+
+
+@dataclass
+class VoipMessage(Message):
+ # 音视频通话
+ invite_type: int # -1,1:语音通话,0:视频通话
+ display_content: str # 界面显示内容
+ duration: int
+
+ def to_text(self):
+ return f'【音视频通话】\n{self.display_content}'
+
+ def to_json(self) -> dict:
+ data = super().to_json()
+ data.update(
+ {
+ 'invite_type': self.invite_type,
+ 'display_content': self.display_content,
+ 'duration': self.duration
+ }
+ )
+ return data
+
+
+@dataclass
+class PositionMessage(Message):
+ # 位置分享
+ x: float # 经度
+ y: float # 维度
+ label: str # 详细标签
+ poiname: str # 位置点标记名
+ scale: float # 缩放率
+
+ def to_text(self):
+ return f'''【位置分享】
+坐标: ({self.x},{self.y})
+名称: {self.poiname}
+标签: {self.label}
+'''
+
+ def to_json(self) -> dict:
+ data = super().to_json()
+ data.update(
+ {
+ 'x': self.x, # 经度
+ 'y': self.y, # 维度
+ 'label': self.label, # 详细标签
+ 'poiname': self.poiname, # 位置点标记名
+ 'scale': self.scale, # 缩放率
+ }
+ )
+ return data
+
+
+@dataclass
+class BusinessCardMessage(Message):
+ # 名片消息
+ is_open_im: bool # 是否是企业微信
+ username: str # 名片的wxid
+ nickname: str # 名片昵称
+ alias: str # 名片微信号
+ province: str # 省份
+ city: str # 城市
+ sign: str # 签名
+ sex: int # 性别 0:未知,1:男,2:女
+ small_head_url: str # 头像
+ big_head_url: str # 头像原图
+ open_im_desc: str # 公司名
+ open_im_desc_icon: str # 公司logo
+
+ def _sex_name(self):
+ if self.sex == 0:
+ return '未知'
+ elif self.sex == 1:
+ return '男'
+ else:
+ return '女'
+
+ def to_text(self):
+ if self.is_open_im:
+ return f'''【名片】
+公司: {self.open_im_desc}
+昵称: {self.nickname}
+性别: {self._sex_name()}
+'''
+ else:
+ return f'''【名片】
+微信号:{self.alias}
+昵称: {self.nickname}
+签名: {self.sign}
+性别: {self._sex_name()}
+地区: {self.province} {self.city}
+'''
+
+ def to_json(self) -> dict:
+ data = super().to_json()
+ data.update(
+ {
+ 'is_open_im': self.is_open_im,
+ 'big_head_url': self.big_head_url, # 头像原图
+ 'small_head_url': self.small_head_url, # 小头像
+ 'username': self.username, # wxid
+ 'nickname': self.nickname, # 昵称
+ 'alias': self.alias, # 微信号
+ 'province': self.province, # 省份
+ 'city': self.city, # 城市
+ 'sex': self._sex_name(), # int :性别 0:未知,1:男,2:女
+ 'open_im_desc': self.open_im_desc, # 公司名
+ 'open_im_desc_icon': self.open_im_desc_icon, # 公司名前面的图标
+ }
+ )
+ return data
+
+
+@dataclass
+class TransferMessage(Message):
+ # 转账
+ fee_desc: str # 金额
+ pay_memo: str # 备注
+ receiver_username: str # 收款人
+ pay_subtype: int # 状态
+
+ def display_content(self):
+ text_info_map = {
+ 1: "发起转账",
+ 3: "已收款",
+ 4: "已退还",
+ 5: "非实时转账收款",
+ 7: "发起非实时转账",
+ 8: "未知",
+ 9: "未知",
+ }
+ return text_info_map.get(self.pay_subtype, '未知')
+
+ def to_text(self):
+ return f'''【{self.display_content()}】:{self.fee_desc}
+备注: {self.pay_memo}
+'''
+
+ def to_json(self) -> dict:
+ data = super().to_json()
+ data.update(
+ {
+ 'text': self.display_content(), # 显示文本
+ 'pay_subtype': self.pay_subtype, # 当前状态
+ 'pay_memo': self.pay_memo, # 备注
+ 'fee_desc': self.fee_desc # 金额
+ }
+ )
+ return data
+
+
+@dataclass
+class RedEnvelopeMessage(Message):
+ # 红包
+ icon_url: str # 红包logo
+ title: str
+ inner_type: int
+
+ def to_text(self):
+ return f'''【红包】: {self.title}'''
+
+ def to_json(self) -> dict:
+ data = super().to_json()
+ data.update(
+ {
+ 'text': self.title, # 显示文本
+ 'inner_type': self.inner_type, # 当前状态
+ }
+ )
+ return data
+
+
+@dataclass
+class FavNoteMessage(Message):
+ # 收藏笔记
+ title: str
+ description: str
+ record_item: str
+
+ def to_text(self):
+ return f'''【笔记】
+{self.description}
+{self.record_item}
+'''
+
+ def to_json(self) -> dict:
+ data = super().to_json()
+ data.update(
+ {
+ 'text': self.title, # 显示文本
+ 'description': self.description, # 内容
+ 'record_item': self.record_item
+ }
+ )
+ return data
+
+
+@dataclass
+class PatMessage(Message):
+ # 拍一拍
+ title: str
+ from_username: str
+ chat_username: str
+ patted_username: str
+ template: str
+
+ def to_text(self):
+ return self.title
+
+ def to_json(self) -> dict:
+ data = super().to_json()
+ data.update(
+ {
+ 'type': MessageType.System,
+ 'text': self.title, # 显示文本
+ }
+ )
+ return data
+
+
+if __name__ == '__main__':
+ msg = TextMessage(
+ local_id=1,
+ server_id=101,
+ timestamp=1678901234,
+ type="text",
+ talker_id="wxid_12345",
+ is_sender=True,
+ sender_id="wxid_67890",
+ display_name="John Doe",
+ status=3,
+ content="Hello, world!"
+ )
+ print(msg.status) # 输出:3
diff --git a/wxManager/parser/__init__.py b/wxManager/parser/__init__.py
new file mode 100644
index 0000000..2b393d7
--- /dev/null
+++ b/wxManager/parser/__init__.py
@@ -0,0 +1,13 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2024/12/11 1:26
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-__init__.py.py
+@Description :
+"""
+
+if __name__ == '__main__':
+ pass
diff --git a/wxManager/parser/audio_parser.py b/wxManager/parser/audio_parser.py
new file mode 100644
index 0000000..2a0a536
--- /dev/null
+++ b/wxManager/parser/audio_parser.py
@@ -0,0 +1,39 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2024/12/12 16:55
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-audio_parser.py
+@Description :
+"""
+import xmltodict
+
+
+def parser_audio(xml_content):
+ result = {
+ 'audio_length': 0,
+ 'audio_text':''
+ }
+ xml_content = xml_content.strip()
+ try:
+ xml_dict = xmltodict.parse(xml_content)
+ voice_length = xml_dict.get('msg', {}).get('voicemsg', {}).get('@voicelength', 0)
+ audio_text = xml_dict.get('msg',{}).get('voicetrans',{}).get('@transtext','')
+ result = {
+ 'audio_length': voice_length,
+ 'audio_text':audio_text
+ }
+ except:
+ if xml_content and ':' in xml_content:
+ voice_length = int(xml_content.split(':')[1])
+ result = {
+ 'audio_length': voice_length
+ }
+ finally:
+ return result
+
+
+if __name__ == '__main__':
+ pass
diff --git a/wxManager/parser/emoji_parser.py b/wxManager/parser/emoji_parser.py
new file mode 100644
index 0000000..a9af038
--- /dev/null
+++ b/wxManager/parser/emoji_parser.py
@@ -0,0 +1,65 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2024/12/12 18:10
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-emoji_parser.py
+@Description :
+"""
+import base64
+import traceback
+
+import xmltodict
+from google.protobuf.json_format import MessageToDict
+
+from wxManager.log import logger
+from wxManager.parser.util.protocbuf import emoji_desc_pb2
+
+
+def parser_emoji(xml_content):
+ result = {
+ 'md5': 0,
+ 'url': '',
+ 'width': 0,
+ 'height': 0,
+ 'desc': ''
+ }
+ xml_content = xml_content.strip()
+ try:
+ xml_dict = xmltodict.parse(xml_content)
+ emoji_dic = xml_dict.get('msg', {}).get('emoji', {})
+ if '@androidmd5' in emoji_dic:
+ md5 = emoji_dic.get('@androidmd5', '')
+ else:
+ md5 = emoji_dic.get('@md5', '')
+ # logger.error(xml_dict)
+ desc_bs64 = emoji_dic.get('@desc', '')
+ desc = ''
+ if desc_bs64:
+ # 逆天微信,竟然把protobuf数据用base64编码后放入xml里
+ desc_bytes_proto = base64.b64decode(desc_bs64)
+ message = emoji_desc_pb2.EmojiDescData()
+ # 解析二进制数据
+ message.ParseFromString(desc_bytes_proto)
+ dict_output = MessageToDict(message)
+ for item in dict_output.get('descItem', []):
+ desc = item.get('desc', '')
+ if desc:
+ break
+ result = {
+ 'md5': md5,
+ 'url': emoji_dic.get('@cdnurl', ''),
+ 'width': emoji_dic.get('@width', 0),
+ 'height': emoji_dic.get('@height', 0),
+ 'desc': desc,
+ }
+ except:
+ logger.error(traceback.format_exc())
+ finally:
+ return result
+
+
+if __name__ == '__main__':
+ pass
diff --git a/wxManager/parser/file_parser.py b/wxManager/parser/file_parser.py
new file mode 100644
index 0000000..cecd8da
--- /dev/null
+++ b/wxManager/parser/file_parser.py
@@ -0,0 +1,61 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2024/12/12 22:52
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-file_parser.py
+@Description :
+"""
+
+import xmltodict
+
+from wxManager.log import logger
+
+
+def get_image_type(header):
+ # 根据文件头判断图片类型
+ if header.startswith(b'\xFF\xD8'):
+ return 'jepg'
+ elif header.startswith(b'\x89PNG'):
+ return 'png'
+ elif header[:6] in (b'GIF87a', b'GIF89a'):
+ return 'gif'
+ elif header.startswith(b'BM'):
+ return 'bmp'
+ elif header.startswith(b'\x00\x00\x01\x00'):
+ return 'ico'
+ elif header.startswith(b'\x49\x49\x2A\x00') or header.startswith(b'\x4D\x4D\x00\x2A'):
+ return 'tiff'
+ elif header.startswith(b'RIFF') and header[8:12] == b'WEBP':
+ return 'webp'
+ else:
+ return 'png'
+
+
+def parse_video(xml_content):
+ result = {
+ 'md5': 0
+ }
+ xml_content = xml_content.strip()
+ try:
+ xml_dict = xmltodict.parse(xml_content)
+ # logger.error(json.dumps(xml_dict))
+ video_dic = xml_dict.get('msg', {}).get('videomsg', {})
+ md5 = video_dic.get('@md5', '') # 下载后压缩视频的md5
+ rawmd5 = video_dic.get('@rawmd5', '') # 原视频md5
+ result = {
+ 'md5': md5,
+ 'rawmd5': rawmd5,
+ 'length': video_dic.get('@playlength', 0),
+ 'size': video_dic.get('@length', 0)
+ }
+ except:
+ logger.error(f'视频解析失败\n{xml_content}')
+ finally:
+ return result
+
+
+if __name__ == '__main__':
+ pass
diff --git a/wxManager/parser/link_parser.py b/wxManager/parser/link_parser.py
new file mode 100644
index 0000000..5078126
--- /dev/null
+++ b/wxManager/parser/link_parser.py
@@ -0,0 +1,1232 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2025/1/10 2:02
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : wxManager-link_parser.py
+@Description :
+"""
+import html
+import traceback
+from datetime import datetime, timedelta
+import xml.etree.ElementTree as ET
+from typing import List
+
+import xmltodict
+
+from wxManager.log import logger
+from wxManager.model import *
+
+
+def parser_link(xml_content):
+ result = {
+ 'title': '',
+ 'desc': '',
+ 'url': '',
+ 'appname': '',
+ 'appid': '',
+ 'cover_url': '',
+ 'sourcedisplayname': '',
+ 'sourceusername': ''
+ }
+ xml_content = xml_content.strip()
+ try:
+ xml_dict = xmltodict.parse(xml_content)
+ dic = xml_dict.get('msg', {})
+ cover_url = dic.get('appmsg', {}).get('thumburl', '')
+ if not cover_url:
+ cover_url = dic.get('appmsg', {}).get('songalbumurl', '')
+
+ result = {
+ 'title': dic.get('appmsg', {}).get('title', ''),
+ 'desc': dic.get('appmsg', {}).get('des', ''),
+ 'url': dic.get('appmsg', {}).get('url', ''),
+ 'cover_url': cover_url,
+ 'sourcedisplayname': dic.get('appmsg', {}).get('sourcedisplayname', ''),
+ 'appname': dic.get('appinfo', {}).get('appname', ''),
+ 'appid': dic.get('appmsg', {}).get('@appid', ''),
+ 'sourceusername': dic.get('appmsg', {}).get('sourceusername', ''),
+ }
+ except:
+ logger.error(traceback.format_exc())
+ finally:
+ return result
+
+
+def parser_voip(xml_content):
+ result = {
+ 'invite_type': 0,
+ 'duration': 0,
+ 'display_content': ''
+ }
+ if not xml_content:
+ return result
+ try:
+ xml_content = xml_content.strip()
+ xml_dict = xmltodict.parse(f'{xml_content}')
+ dic = xml_dict.get('voipdata', {})
+ type_ = dic.get('voipmsg', {}).get('@type')
+ duration = 0
+ if type_ == 'VoIPBubbleMsg':
+ invite_type = -1
+ display_content = dic.get('voipmsg', {}).get('VoIPBubbleMsg', {}).get('msg', '')
+ else:
+ invite_type = dic.get('voipinvitemsg', {}).get('invite_type', '0')
+ duration = dic.get('voiplocalinfo', {}).get('duration', '0')
+ display_content = dic.get('voiplocalinfo', {}).get('diaplay_content', '')
+ result = {
+ 'invite_type': int(invite_type),
+ 'duration': duration,
+ 'display_content': display_content
+ }
+ except:
+ logger.error(traceback.format_exc())
+ finally:
+ return result
+
+
+def parser_applet(xml_content):
+ result = {
+ 'title': '',
+ 'desc': '',
+ 'url': '',
+ 'app_icon': ''
+ }
+ xml_content = xml_content.strip()
+ try:
+ xml_dict = xmltodict.parse(xml_content)
+ dic = xml_dict.get('msg', {})
+ weappinfo = dic.get('appmsg', {}).get('weappinfo', {})
+ cover_url = weappinfo.get('weapppagethumbrawurl', '')
+ if not cover_url:
+ cover_url = weappinfo.get('weapppagethumbrawurl', '')
+ if not cover_url:
+ page_path = weappinfo.get('pagepath', '')
+ # 按 '&' 分割字符串
+ parts = page_path.split('&')
+
+ # 遍历每个部分,找到以 'cover=' 开头的部分
+ for part in parts:
+ if part.startswith('cover='):
+ # 提取 cover 后面的连接
+ cover_url = part.split('=')[1]
+
+ result = {
+ 'title': dic.get('appmsg', {}).get('title', ''),
+ 'desc': dic.get('appmsg', {}).get('des', ''),
+ 'url': dic.get('appmsg', {}).get('url', ''),
+ 'appname': dic.get('appmsg', {}).get('sourcedisplayname', ''),
+ 'appid': weappinfo.get('@appid', ''),
+ 'app_icon': weappinfo.get('weappiconurl', ''),
+ 'cover_url': cover_url,
+ }
+ except:
+ logger.error(traceback.format_exc())
+ finally:
+ return result
+
+
+def parser_music(xml_content):
+ if not xml_content:
+ return {"type": 3, "title": "发生错误", "is_error": True}
+ try:
+ root = ET.XML(xml_content)
+ appmsg = root.find("appmsg")
+ msg_type = int(appmsg.find("type").text)
+ title = appmsg.find("title").text
+ if len(title) >= 39:
+ title = title[:38] + "..."
+ artist = appmsg.find("des").text
+ link_url = appmsg.find("url").text # 链接地址
+ try:
+ songalbumurl = appmsg.find('songalbumurl').text # 封面地址
+ except:
+ songalbumurl = ''
+ try:
+ website_name = root.find('appinfo').find('appname').text
+ except:
+ website_name = 'QQ音乐'
+ return {
+ "type": msg_type,
+ "title": title,
+ "artist": artist,
+ "url": link_url,
+ "songalbumurl": songalbumurl,
+ "appname": website_name,
+ "is_error": False,
+ }
+ except Exception as e:
+ logger.error(f'音乐分享解析失败\n{traceback.format_exc()}')
+ print(f"Music Share Error: {e}")
+ return {"type": 3, "title": "发生错误", "is_error": True}
+
+
+def parser_business(xml_content):
+ result = {
+ 'bigheadimgurl': '', # 头像原图
+ 'smallheadimgurl': '', # 小头像
+ 'username': '', # wxid
+ 'nickname': '', # 昵称
+ 'alias': '', # 微信号
+ 'province': '', # 省份
+ 'city': '', # 城市
+ 'sex': 1, # int :性别 0:未知,1:男,2:女
+ 'sign': '', # 签名
+ 'openimdesc': '', # 公司名
+ 'openimdescicon': '', # 公司名前面的图标
+ }
+ xml_content = xml_content.strip()
+ try:
+ data = xmltodict.parse(xml_content.replace('&', '&'))
+ if data and data.get('msg'):
+ data = data['msg']
+ result['bigheadimgurl'] = data.get('@bigheadimgurl')
+ result['smallheadimgurl'] = data.get('@smallheadimgurl')
+ result['username'] = data.get('@username')
+ result['nickname'] = data.get('@nickname')
+ result['alias'] = data.get('@alias')
+ result['province'] = data.get('@province')
+ result['city'] = data.get('@city')
+ result['sign'] = data.get('@sign')
+ result['sex'] = int(data.get('@sex', ''))
+ result['openimdesc'] = data.get('@openimdesc')
+ result['openimdescicon'] = data.get('@openimdescicon')
+ return result
+ except:
+ logger.error(f'名片解析错误\n{traceback.format_exc()}\n{xml_content}')
+ result.update(
+ {
+ 'type': 1,
+ 'text': '【名片解析错误】'
+ }
+ )
+ finally:
+ return result
+
+
+def parser_record_item(recorditem, output_dir, wxid, msg_time, level=0):
+ xml_string = recorditem
+ if isinstance(xml_string, dict):
+ recorditem_dic = xml_string
+ else:
+ recorditem_dic = xmltodict.parse(xml_string)
+
+ # logger.error(recorditem_dic)
+ datalist = recorditem_dic.get('recordinfo', {}).get('datalist', {})
+ count = datalist.get('@count', 0)
+ dataitem = datalist.get('dataitem', [])
+ result = []
+ if isinstance(dataitem, dict):
+ # 转发单条消息
+ dataitem = [dataitem]
+ # logger.info(dataitem)
+ for item in dataitem:
+ # logger.info(item)
+ type_ = item.get('@datatype')
+ timestamp = item.get('srcMsgCreateTime')
+ if timestamp:
+ timestamp = int(timestamp)
+ else:
+ timestamp = 0
+ str_time = item.get('sourcetime')
+ if not timestamp:
+ try:
+ # 将字符串转换为datetime对象
+ dt = datetime.strptime(str_time, "%Y-%m-%d %H:%M:%S")
+ except:
+
+ if '上午' in str_time:
+ str_time = str_time.replace('上午 ', '上午')
+ time_format = '%Y-%m-%d 上午%H:%M'
+ dt = datetime.strptime(str_time, time_format) + timedelta(hours=12)
+ elif '下午' in str_time:
+ str_time = str_time.replace('下午 ', '下午')
+ time_format = '%Y-%m-%d 下午%H:%M'
+ # 解析后需要加12小时来转换成24小时制
+ dt = datetime.strptime(str_time, time_format) + timedelta(hours=12)
+ else:
+ try:
+ import dateparser
+ str_time = str_time.replace(' ', ' ')
+ dt = dateparser.parse(str_time)
+ if dt is None:
+ raise ValueError("无法解析时间字符串")
+ timestamp = dt.timestamp()
+ except:
+ logger.error(f'未知的时间格式:{str_time}')
+ dt = datetime.strptime('1970-01-01 00:00:00', '%Y-%m-%d %H:%M:%S')
+ try:
+ # 将datetime对象转换为时间戳
+ timestamp = int(dt.timestamp())
+ except:
+ logger.error(f'未知的时间格式:{str_time}')
+ dt = datetime.strptime('1970-01-01 00:00:00', '%Y-%m-%d %H:%M:%S')
+
+ if type_ == '1':
+ # 纯文本
+ content = item.get('datadesc')
+ if item.get('refermsgitem'):
+ refermsg = item.get('refermsgitem', {}).get('referdesc', '')
+ content = f"{content}\n{refermsg}"
+ result.append(
+ TextMessage(
+ local_id=0,
+ server_id=0,
+ sort_seq=0,
+ timestamp=timestamp,
+ str_time=str_time,
+ type=MessageType.Text,
+ talker_id='',
+ is_sender=False,
+ sender_id='',
+ display_name=item.get('sourcename'),
+ avatar_src=item.get('sourceheadurl'),
+ status=0,
+ xml_content='',
+ content=content
+ )
+ )
+ elif type_ == '2':
+ """
+ 合并转发的聊天记录
+ """
+ # 图片 & 表情包
+ md5 = item.get('fullmd5', '')
+ msg = ImageMessage(
+ local_id=0,
+ server_id=0,
+ sort_seq=0,
+ timestamp=timestamp,
+ str_time=str_time,
+ type=MessageType.Image,
+ talker_id='',
+ is_sender=False,
+ sender_id='',
+ display_name=item.get('sourcename'),
+ avatar_src=item.get('sourceheadurl'),
+ status=0,
+ xml_content='',
+ md5=md5,
+ path='',
+ thumb_path='',
+ file_size=0,
+ file_name='',
+ file_type='png'
+ )
+ result.append(
+ msg
+ )
+ elif type_ == '37':
+ """
+ 合并转发的聊天记录
+ """
+ #表情包
+ md5 = item.get('fullmd5', '')
+ msg = EmojiMessage(
+ local_id=0,
+ server_id=0,
+ sort_seq=0,
+ timestamp=timestamp,
+ str_time=str_time,
+ type=MessageType.Emoji,
+ talker_id='',
+ is_sender=False,
+ sender_id='',
+ display_name=item.get('sourcename'),
+ avatar_src=item.get('sourceheadurl'),
+ status=0,
+ xml_content='',
+ md5=md5,
+ path='',
+ thumb_path='',
+ file_size=0,
+ file_name='',
+ file_type='png',
+ url='',
+ thumb_url='',
+ description=''
+ )
+ emoji_item = item.get('emojiitem', {})
+ msg.url = emoji_item.get('cdnurlstring', '')
+ msg.thumb_url = emoji_item.get('cdnurlstring', '')
+ result.append(
+ msg
+ )
+ elif type_ == '3':
+ # 语音
+ result.append(
+ TextMessage(
+ local_id=0,
+ server_id=0,
+ sort_seq=0,
+ timestamp=timestamp,
+ str_time=str_time,
+ type=MessageType.Audio,
+ talker_id='',
+ is_sender=False,
+ sender_id='',
+ display_name=item.get('sourcename'),
+ avatar_src=item.get('sourceheadurl'),
+ status=0,
+ xml_content='',
+ content='【转发语音不可播放】'
+ )
+ )
+ elif type_ == '4':
+ # 视频
+ md5 = item.get('fullmd5', '')
+ path = item.get('datasourcepath', '')
+ result.append(
+ VideoMessage(
+ local_id=0,
+ server_id=0,
+ sort_seq=0,
+ timestamp=timestamp,
+ str_time=str_time,
+ type=MessageType.Video,
+ talker_id='',
+ is_sender=False,
+ sender_id='',
+ display_name=item.get('sourcename'),
+ avatar_src=item.get('sourceheadurl'),
+ status=0,
+ xml_content='',
+ md5=md5,
+ path=path,
+ file_size=0,
+ file_name='',
+ file_type='mp4',
+ thumb_path='',
+ duration=0,
+ raw_md5=md5
+ )
+ )
+ elif type_ == '5':
+ # 链接
+ web_item = item.get('weburlitem', {})
+ result.append(
+ LinkMessage(
+ local_id=0,
+ server_id=0,
+ sort_seq=0,
+ timestamp=timestamp,
+ str_time=str_time,
+ type=MessageType.LinkMessage,
+ talker_id='',
+ is_sender=False,
+ sender_id='',
+ display_name=item.get('sourcename'),
+ avatar_src=item.get('sourceheadurl'),
+ status=0,
+ xml_content='',
+ href=web_item.get('url', ''),
+ title=web_item.get('title', ''),
+ description=web_item.get('desc', ''),
+ cover_path='',
+ cover_url='',
+ app_name=web_item.get('appmsgshareitem', {}).get('srcdisplayname'),
+ app_icon='',
+ app_id=''
+ )
+ )
+ elif type_ == '6':
+ # 位置分享
+ locitem = item.get('locitem', {})
+ label = locitem.get('label', '')
+ poiname = locitem.get('poiname', '')
+ try:
+ x = float(locitem.get('lng', '0'))
+ y = float(locitem.get('lat', '0'))
+ scale = float(locitem.get('scale', '0'))
+ except:
+ x, y, scale = 0, 0, 0
+ result.append(
+ PositionMessage(
+ local_id=0,
+ server_id=0,
+ sort_seq=0,
+ timestamp=timestamp,
+ str_time=str_time,
+ type=MessageType.Position,
+ talker_id='',
+ is_sender=False,
+ sender_id='',
+ display_name=item.get('sourcename'),
+ avatar_src=item.get('sourceheadurl'),
+ status=0,
+ xml_content='',
+ x=x,
+ y=y,
+ label=label,
+ poiname=poiname,
+ scale=scale
+ )
+ )
+
+ elif type_ == '8':
+ # 文件
+ md5 = item.get('fullmd5', '')
+ datasize = item.get('datasize')
+ if datasize:
+ datasize = int(datasize)
+ else:
+ datasize = 0
+ result.append(
+ FileMessage(
+ local_id=0,
+ server_id=0,
+ sort_seq=0,
+ timestamp=timestamp,
+ str_time=str_time,
+ type=MessageType.File,
+ talker_id='',
+ is_sender=False,
+ sender_id='',
+ display_name=item.get('sourcename'),
+ avatar_src=item.get('sourceheadurl'),
+ status=0,
+ xml_content='',
+ path='',
+ md5=md5,
+ file_type=item.get('datafmt', ''),
+ file_name=item.get('datatitle', ''),
+ file_size=datasize
+ )
+ )
+ elif type_ == '17':
+ # 嵌套的消息
+ result.append(
+ MergedMessage(
+ local_id=0,
+ server_id=0,
+ sort_seq=0,
+ timestamp=timestamp,
+ str_time=str_time,
+ type=MessageType.MergedMessages,
+ talker_id='',
+ is_sender=False,
+ sender_id='',
+ display_name=item.get('sourcename'),
+ avatar_src=item.get('sourceheadurl'),
+ status=0,
+ xml_content='',
+ title=item.get('datatitle'),
+ description=item.get('datadesc'),
+ messages=parser_record_item(item.get('recordxml'), output_dir, wxid,
+ msg_time, level + 1),
+ level=level
+ )
+ )
+ return result
+
+
+def parser_merged_messages(xml, output_dir, wxid, msg_time, level=0):
+ try:
+ try:
+ data_dic = xmltodict.parse(xml).get('msg', {})
+ except:
+ new_xml1 = html.unescape(xml)
+ new_xml2 = new_xml1.replace('&', '&')
+ # xml = xml.replace(' ', ' ').replace('�', '').replace('
', '\n').replace('\xa0',' ') # 搞不懂这帮人在干嘛,有些转义,有些不转义
+ # html.unescape(xml)
+ data_dic = xmltodict.parse(new_xml2).get('msg', {})
+ app_msg_dic = data_dic.get('appmsg', {})
+ desc = app_msg_dic.get('des', '')
+ title = app_msg_dic.get('title', '')
+ recorditem = app_msg_dic.get('recorditem', '')
+ return {
+ 'title': title, # 标题
+ 'desc': desc, # 描述
+ 'messages': parser_record_item(recorditem, output_dir, wxid, msg_time, level), # List[dict] 消息内容
+ }
+ except:
+ logger.error(xml)
+ logger.error(new_xml1)
+ logger.error(new_xml2)
+ logger.error(traceback.format_exc())
+ # raise ValueError('合并转发的消息解析失败')
+ return {
+ 'title': '解析失败', # 标题
+ 'desc': '合并转发的消息解析失败', # 描述
+ 'messages': []
+ }
+
+
+def parser_wechat_video(xml_content):
+ result = {
+ 'appid': '', # 暂时不用
+ 'title': '', # 标题
+ 'sourcedisplayname': '', # 视频号名称
+ 'weappiconurl': '', # 视频号logo
+ 'authIconUrl': '', # 视频号认证URL,昵称后缀
+ 'cover': '', # 封面url
+ 'duration': 0
+ }
+ xml_content = xml_content.strip()
+ try:
+ dic_data = xmltodict.parse(xml_content).get('msg', {}).get('appmsg', {}).get('finderFeed', {})
+ sourcedisplayname = dic_data.get('nickname', '')
+ weappiconurl = dic_data.get('avatar', '')
+ authIconUrl = dic_data.get('authIconUrl', '')
+ title = dic_data.get('desc', '')
+ media_count = dic_data.get('mediaCount', '0')
+ if media_count > '1':
+ cover = dic_data.get('mediaList', {}).get('media', [])[0].get('thumbUrl', '')
+ duration = 0
+ else:
+ cover = dic_data.get('mediaList', {}).get('media', {}).get('coverUrl', '')
+ duration = dic_data.get('mediaList', {}).get('media', {}).get('videoPlayDuration', 0)
+ result = {
+ 'title': title,
+ 'url': '',
+ 'sourcedisplayname': sourcedisplayname,
+ 'weappiconurl': weappiconurl,
+ 'cover': cover,
+ 'authIconUrl': authIconUrl,
+ 'duration': duration
+ }
+ except:
+ logger.error(traceback.format_exc())
+ finally:
+ return result
+
+
+def parser_position(xml_content):
+ result = {
+ 'x': '0', # 经度
+ 'y': '0', # 维度
+ 'label': '', # 详细标签
+ 'poiname': '', # 位置点标记名
+ 'scale': '0', # 缩放率
+ }
+ try:
+ data = xmltodict.parse(xml_content)
+ if data and data.get('msg'):
+ data = data['msg']
+ result['x'] = data['location']['@x']
+ result['y'] = data['location']['@y']
+ result['label'] = data['location'].get('@label')
+ result['poiname'] = data['location'].get('@poiname')
+ result['scale'] = data['location'].get('@scale')
+ except:
+ logger.error(f'位置分享解析错误\n{traceback.format_exc()} \n{xml_content}')
+ result.update(
+ {
+ 'type': 1,
+ 'text': '【位置分享解析错误】'
+ }
+ )
+ finally:
+ return result
+
+
+def parser_reply(xml_content):
+ """
+ @param data:
+ @return: {
+ "text": '发生错误', 发送内容
+ 'svrid': '', 引用消息id
+ 'refermsg_type': -1, 引用消息类型
+ "refer_text": '引用错误', 引用内容
+ }
+ """
+ if not xml_content:
+ return {
+ # "type": msg_type,
+ "text": '发生错误',
+ 'svrid': '',
+ 'refermsg_type': -1,
+ "refer_text": '引用错误',
+ }
+ xml_content = xml_content.replace("�", "").replace('�', '')
+ try:
+ data = xmltodict.parse(xml_content).get('msg', {}).get('appmsg', {})
+ refermsg_type = int(data.get('refermsg', {}).get('type', '1'))
+ title = data.get('title', '')
+ displayname = data.get('refermsg', {}).get('displayname', '')
+ svrid = data.get('refermsg', {}).get('svrid', 0)
+ return {
+ "text": title,
+ 'svrid': svrid,
+ 'refermsg_type': refermsg_type,
+ }
+ # if refermsg_type == 1:
+ # return {
+ # # "type": msg_type,
+ # "text": title,
+ # 'svrid': data.get('refermsg', {}).get('svrid', 0),
+ # 'refermsg_type': refermsg_type,
+ # "refer_text": f"{refermsg_displayname}:{refermsg_content}",
+ # }
+ # elif refermsg_type == 3:
+ # return {
+ # # "type": msg_type,
+ # "text": title,
+ # 'svrid': data.get('refermsg', {}).get('svrid', 0),
+ # 'refermsg_type': refermsg_type,
+ # "refer_text": f"{displayname}:【图片消息】",
+ # }
+ # elif refermsg_type == 34:
+ # return {
+ # # "type": msg_type,
+ # "text": title,
+ # 'svrid': data.get('refermsg', {}).get('svrid', 0),
+ # 'refermsg_type': refermsg_type,
+ # "refer_text": f"{displayname}:【语音消息】",
+ # }
+ # elif refermsg_type == 43:
+ # return {
+ # # "type": msg_type,
+ # "text": title,
+ # 'svrid': data.get('refermsg', {}).get('svrid', 0),
+ # 'refermsg_type': refermsg_type,
+ # "refer_text": f"{displayname}:【视频消息】",
+ # }
+ # elif refermsg_type == 47:
+ # return {
+ # # "type": msg_type,
+ # "text": title,
+ # 'svrid': data.get('refermsg', {}).get('svrid', 0),
+ # 'refermsg_type': refermsg_type,
+ # "refer_text": f"{displayname}:【表情包】",
+ # }
+ # elif refermsg_type == 49:
+ # content = data.get('refermsg', {}).get('content', '')
+ # content = xmltodict.parse(content).get('msg', {}).get('appmsg', {})
+ # refermsg_content = content.get('title', '')
+ # return {
+ # # "type": msg_type,
+ # "text": title,
+ # 'svrid': data.get('refermsg', {}).get('svrid', 0),
+ # 'refermsg_type': refermsg_type,
+ # "refer_text": f"{displayname}:{refermsg_content}",
+ # "url": content.get('url', ''),
+ # }
+ # elif refermsg_type == 0:
+ # return {
+ # # "type": msg_type,
+ # "text": title,
+ # 'svrid': data.get('refermsg', {}).get('svrid', 0),
+ # 'refermsg_type': refermsg_type,
+ # "refer_text": data.get('refermsg', {}).get('ref_msg_text', ''),
+ # }
+ # elif refermsg_type == 66:
+ # return {
+ # # "type": msg_type,
+ # "text": title,
+ # 'svrid': data.get('refermsg', {}).get('svrid', 0),
+ # 'refermsg_type': refermsg_type,
+ # "refer_text": f"{displayname}:【名片分享】",
+ # }
+ # elif refermsg_type == 42:
+ # return {
+ # # "type": msg_type,
+ # "text": title,
+ # 'svrid': data.get('refermsg', {}).get('svrid', 0),
+ # 'refermsg_type': refermsg_type,
+ # "refer_text": f"{displayname}:【名片分享】",
+ # }
+ # elif refermsg_type == 48:
+ # position_dict = xmltodict.parse(data.get('refermsg', {}).get('content', '')).get('msg')
+ # return {
+ # # "type": msg_type,
+ # "text": title,
+ # 'svrid': data.get('refermsg', {}).get('svrid', 0),
+ # 'refermsg_type': refermsg_type,
+ # "refer_text": f"{displayname}:{position_dict['location'].get('@poiname')}",
+ # }
+ # else:
+ # logger.info(f'发现未知的引用消息\n{data}')
+ # return {
+ # # "type": msg_type,
+ # "text": title,
+ # 'svrid': data.get('refermsg', {}).get('svrid', 0),
+ # 'refermsg_type': refermsg_type,
+ # "refer_text": f"{displayname}:【其他消息】",
+ # }
+ except:
+ logger.error(f'{xml_content}\n\n引用消息解析错误\n{traceback.format_exc()}')
+ return {
+ # "type": msg_type,
+ "text": '发生错误',
+ 'svrid': '',
+ 'refermsg_type': -1,
+ "refer_text": '引用错误',
+ }
+
+
+def parser_transfer(xml_content):
+ result = {
+ 'pay_subtype': 0,
+ 'pay_memo': '',
+ 'fee_desc': '',
+ 'receiver_username': ''
+ }
+ try:
+ data = xmltodict.parse(xml_content).get('msg', {}).get('appmsg', {})
+ result = {
+ 'pay_subtype': int(data.get('wcpayinfo', {}).get('paysubtype', '-1')),
+ 'pay_memo': data.get('wcpayinfo', {}).get('pay_memo', ''),
+ 'fee_desc': data.get('wcpayinfo', {}).get('feedesc', ''),
+ 'receiver_username': data.get('wcpayinfo', {}).get('receiver_username', ''),
+ }
+ except:
+ logger.error(f'转账解析错误\n{traceback.format_exc()}')
+ result.update(
+ {
+ 'type': 1,
+ 'text': '【位置分享解析错误】'
+ }
+ )
+ finally:
+ return result
+
+
+def parser_red_envelop(xml_content):
+ result = {
+ 'icon_url': '',
+ 'title': '',
+ 'inner_type': 0
+ }
+ try:
+ data = xmltodict.parse(xml_content).get('msg', {}).get('appmsg', {})
+ result = {
+ 'icon_url': data.get('wcpayinfo', {}).get('iconurl', ''),
+ 'title': data.get('wcpayinfo', {}).get('receivertitle', ''),
+ 'inner_type': int(data.get('wcpayinfo', {}).get('innertype', '0')),
+ }
+ except:
+ logger.error(f'红包解析错误\n{traceback.format_exc()}')
+ result.update(
+ {
+ 'type': 1,
+ 'text': '【位置分享解析错误】'
+ }
+ )
+ finally:
+ return result
+
+
+def parser_file(xml_content):
+ result = {
+ 'file_name': '',
+ 'file_size': 0,
+ 'md5': '',
+ 'file_type': '',
+ 'app_name': ''
+ }
+ try:
+ data0 = xmltodict.parse(xml_content).get('msg', {})
+ data = data0.get('appmsg', {})
+ totallen = data.get('appattach', {}).get('totallen')
+ if isinstance(totallen, list):
+ totallen = totallen[0]
+ if not totallen:
+ totallen = '0'
+ result = {
+ 'file_name': data.get('title', ''),
+ 'file_size': int(totallen),
+ 'md5': data.get('md5', ''),
+ 'file_type': data.get('appattach', {}).get('fileext', ''),
+ 'app_name': data.get('appinfo', {}).get('appname', ''),
+ }
+ except:
+ logger.error(f'文件解析错误\n{traceback.format_exc()}\n{xml_content}')
+ finally:
+ return result
+
+
+def parser_favorite_note(xml_content):
+ result = {
+ 'title': '',
+ 'desc': '',
+ 'recorditem': '',
+ }
+ try:
+ data = xmltodict.parse(xml_content).get('msg', {}).get('appmsg', {})
+ recorditem = data.get('recorditem', '')
+ xml_string = recorditem
+ if isinstance(xml_string, dict):
+ recorditem_dic = xml_string
+ else:
+ recorditem_dic = xmltodict.parse(xml_string)
+ result = {
+ 'title': data.get('title', ''),
+ 'desc': data.get('des', ''),
+ 'recorditem': recorditem_dic,
+ }
+ except:
+ logger.error(f'笔记解析错误\n{traceback.format_exc()}')
+ finally:
+ return result
+
+
+def parser_pat(xml_content):
+ result = {
+ 'title': '',
+ 'from_username': '',
+ 'patted_username': '',
+ 'chat_username': '',
+ 'template': ''
+ }
+ try:
+ data = xmltodict.parse(xml_content).get('msg', {}).get('appmsg', {})
+ patinfo = data.get('patinfo', {})
+ result = {
+ 'title': data.get('title', ''),
+ 'from_username': patinfo.get('fromusername', ''),
+ 'patted_username': patinfo.get('pattedusername', ''),
+ 'chat_username': patinfo.get('chatusername', ''),
+ 'template': patinfo.get('template', ''),
+ }
+ except:
+ logger.error(f'拍一拍解析错误\n{traceback.format_exc()}\n{xml_content}')
+ finally:
+ return result
+
+
+if __name__ == '__main__':
+ pass
+
+
+def wx_sport(xml):
+ dic_data = {}
+ more = ''
+ try:
+ dic_data = xmltodict.parse(xml).get('msg', {}).get('appmsg', {})
+ hardwareinfo = dic_data.get('hardwareinfo', {})
+ rankinfo = hardwareinfo.get('messagenodeinfo', {}).get('rankinfo', {})
+ rank = rankinfo.get('rank', {}).get('rankdisplay', '')
+ score = rankinfo.get('score', {}).get('scoredisplay', '')
+ rankinfolist = hardwareinfo.get('rankview', {}).get('rankinfolist', {}).get('rankinfo', [])
+ rank_list = []
+ for rank_info in rankinfolist:
+ username = rank_info.get('username', '')
+ rank1 = rank_info.get('rank', {}).get('rankdisplay', '')
+ score1 = rank_info.get('score', {}).get('scoredisplay', '')
+ rank_list.append(
+ {
+ 'rank': rank1,
+ 'score': score1,
+ 'username': username
+ }
+ )
+ return {
+ 'rank': rank,
+ 'score': score,
+ 'rank_list': rank_list,
+ 'data': f'{dic_data}'
+ }
+ except:
+ logger.error(traceback.format_exc())
+ logger.error(dic_data)
+ return []
+
+
+def wx_EMS_data(bytesExtra, compress_content_):
+ dic_data = {}
+ send_city = ''
+ send_name = ''
+ express_id = ''
+ send_time = ''
+ send_address = ''
+ courier = ''
+ courier_phone = ''
+ expect_handle = ''
+ sign_time = ''
+ sign_result = ''
+ remark = ''
+ update_time = ''
+
+ try:
+ if isinstance(compress_content_, bytes):
+ xml = decompress_CompressContent(compress_content_)
+ else:
+ xml = compress_content_
+ dic_data = xmltodict.parse(xml).get('msg', {}).get('appmsg', {})
+
+ mmreader = dic_data.get('mmreader', {})
+ template_header = mmreader.get('template_header', {})
+ template_detail = mmreader.get('template_detail', {})
+ if not template_header or not template_detail:
+ return {}
+ title = template_header.get('title', '')
+ digest = template_header.get('first_data', '')
+ display_name = template_header.get('display_name', '')
+ if not title:
+ title = dic_data.get('title', '')
+ if not display_name:
+ display_name = dic_data.get('title')
+ line_content = template_detail.get('line_content', {})
+ lines = line_content.get('lines', {}).get('line')
+
+ if isinstance(lines, List):
+ for line in lines:
+ key = line.get('key').get('word')
+ value = line.get('value').get('word')
+ if key.startswith('寄件城市'):
+ send_city += value
+ elif key.startswith('寄件人'):
+ send_name += value
+ elif key.startswith('快递单号') or key == '运单号':
+ express_id += value
+ elif key.startswith('寄件时间'):
+ send_time += value
+ elif key.startswith('派送地址'):
+ send_address += value
+ elif key.startswith('快递员'):
+ courier += value
+ elif key.startswith('快递员电话'):
+ courier_phone += value
+ elif key.startswith('预计派送处理'):
+ expect_handle += value
+ elif key.startswith('签收时间'):
+ sign_time += value
+ elif key.startswith('签收结果'):
+ sign_result += value
+ elif key == '备注:':
+ remark += value
+ elif key == '更新时间:':
+ update_time += value
+ else:
+ return {}
+ return {
+ 'title': title,
+ 'digest': digest,
+ 'display_name': display_name,
+ 'send_city': send_city,
+ 'send_name': send_name,
+ 'express_id': express_id,
+ 'send_time': send_time,
+ 'send_address': send_address,
+ 'courier': courier,
+ 'courier_phone': courier_phone,
+ 'expect_handle': expect_handle,
+ 'sign_time': sign_time,
+ 'sign_result': sign_result,
+ 'remark': remark,
+ 'update_time': update_time,
+ 'data': f'{dic_data}',
+ }
+ except:
+ logger.error(traceback.format_exc())
+ logger.error(dic_data)
+ return {}
+
+
+def wx_pdd_data(bytesExtra, compress_content_):
+ title = ''
+ display_name = ''
+ dic_data = {}
+ product = ''
+ order_id = ''
+ express = ''
+ express_id = ''
+ sign_time = ''
+ product_num = ''
+ pdd_member = ''
+ order_status = ''
+ refund_money = ''
+ refund_status = ''
+ audit_explain = ''
+ problem_type = ''
+ submit_time = ''
+ handle_result = ''
+ phone_number = ''
+ recharge_money = ''
+ refund_method = ''
+ user_name = ''
+ order_money = ''
+
+ try:
+ if isinstance(compress_content_, bytes):
+ xml = decompress_CompressContent(compress_content_)
+ else:
+ xml = compress_content_
+ dic_data = xmltodict.parse(xml).get('msg', {}).get('appmsg', {})
+
+ mmreader = dic_data.get('mmreader', {})
+ template_header = mmreader.get('template_header', {})
+ template_detail = mmreader.get('template_detail', {})
+ if not template_header or not template_detail:
+ return {}
+ title = template_header.get('title', '')
+ display_name = template_header.get('display_name', '')
+ if not title:
+ title = dic_data.get('title', '')
+ if not display_name:
+ display_name = dic_data.get('title')
+ line_content = template_detail.get('line_content', {})
+ lines = line_content.get('lines', {}).get('line')
+ if isinstance(lines, List):
+ for line in lines:
+ key = line.get('key').get('word')
+ value = line.get('value').get('word')
+ if key == '商品名称:' or key == '商品信息:' or key == '商品:' or key == '商品详情:' or key.startswith(
+ '商品名'):
+ product += value
+ elif key == '订单编号:' or key == '订单号:':
+ order_id += value
+ elif key == '物流服务:' or key == '快递公司:':
+ express += value
+ elif key == '快递单号:':
+ express_id += value
+ elif key == '签收时间:':
+ sign_time += value
+ elif key == '商品数量:':
+ product_num += value
+ elif key == '拼单成员:':
+ pdd_member += value
+ elif key == '订单状态:':
+ order_status += value
+ elif key == '退款金额:':
+ refund_money += value
+ elif key == '退款状态:':
+ refund_status += value
+ elif key == '审核说明:':
+ audit_explain += value
+ elif key == '问题类型:':
+ problem_type += value
+ elif key == '提交时间:':
+ submit_time += value
+ elif key == '处理结果:':
+ handle_result += value
+ elif key == '充值号码:':
+ phone_number += value
+ elif key == '充值金额:':
+ recharge_money += value
+ elif key == '退款方式:':
+ refund_method += value
+ elif key == '用户名:':
+ user_name += value
+ elif key == '订单金额:':
+ order_money += value
+ except:
+ logger.error(traceback.format_exc())
+ logger.error(dic_data)
+ finally:
+ return {
+ 'title': title,
+ 'display_name': display_name,
+ 'product': product,
+ 'order_id': order_id,
+ 'express': express,
+ 'express_id': express_id,
+ 'sign_time': sign_time,
+ 'product_num': product_num,
+ 'pdd_member': pdd_member,
+ 'order_status': order_status,
+ 'refund_money': refund_money,
+ 'refund_status': refund_status,
+ 'audit_explain': audit_explain,
+ 'problem_type': problem_type,
+ 'submit_time': submit_time,
+ 'handle_result': handle_result,
+ 'phone_number': phone_number,
+ 'recharge_money': recharge_money,
+ 'refund_method': refund_method,
+ 'user_name': user_name,
+ 'order_money': order_money,
+ 'data': f'{dic_data}',
+ }
+
+
+def wx_collection_data(xml):
+ dic_data = {}
+ summary = ''
+ more = ''
+ try:
+ dic_data = xmltodict.parse(xml).get('msg', {}).get('appmsg', {})
+ # logger.error(dic_data)
+ mmreader = dic_data.get('mmreader', {})
+ template_header = mmreader.get('template_header', {})
+ template_detail = mmreader.get('template_detail', {})
+ title = template_header.get('title', '')
+ display_name = template_header.get('display_name', '')
+ if not title:
+ title = dic_data.get('title', '')
+ if not display_name:
+ display_name = dic_data.get('title')
+ template_id = dic_data.get('template_id', '')
+ line_content = template_detail.get('line_content', {})
+ money = line_content.get('topline', {}).get('value', {}).get('word', '').strip('¥')
+ lines = line_content.get('lines', {}).get('line')
+ if isinstance(lines, List):
+ for line in lines:
+ key = line.get('key').get('word')
+ value = line.get('value').get('word')
+ if key == '汇总':
+ summary += value
+ elif key == '备注':
+ more += value
+
+ return {
+ 'title': title,
+ 'display_name': display_name,
+ 'template_id': template_id,
+ 'money': money,
+ 'summary': summary,
+ 'data': f'{dic_data}',
+ 'more': more
+ }
+
+ except:
+ logger.error(traceback.format_exc())
+ logger.error(dic_data)
+ return {}
+
+
+def wx_pay_data(xml):
+ dic_data = {}
+ more = ''
+ try:
+ dic_data = xmltodict.parse(xml).get('msg', {}).get('appmsg', {})
+ # logger.error(dic_data)
+ mmreader = dic_data.get('mmreader', {})
+ template_header = mmreader.get('template_header', {})
+ template_detail = mmreader.get('template_detail', {})
+ title = template_header.get('title', '')
+ display_name = template_header.get('display_name', '')
+ if not title:
+ title = dic_data.get('title', '')
+ if not display_name:
+ display_name = dic_data.get('title')
+ template_id = dic_data.get('template_id', '')
+ line_content = template_detail.get('line_content', {})
+ money = line_content.get('topline', {}).get('value', {}).get('word', '').strip('¥')
+ lines = line_content.get('lines', {}).get('line')
+ payment_type = ''
+ acquiring_institution = ''
+ if isinstance(lines, List):
+ for line in lines:
+ key = line.get('key').get('word')
+ value = line.get('value').get('word')
+ if key == '付款方式' or key == '支付方式' or key == '收款账户' or key == '退款方式':
+ payment_type = value
+ elif key == '收单机构' or key == '收款方':
+ acquiring_institution = value
+ elif key == '退款方式':
+ payment_type = value
+ elif key == '退款原因':
+ acquiring_institution = value
+ elif key == '备注' or key == '退款原因':
+ more += value
+ else:
+ payment_type = line_content.get('topline', {}).get('key', {}).get('word', '')
+ acquiring_institution = '个体商户'
+ return {
+ 'title': title,
+ 'display_name': display_name,
+ 'template_id': template_id,
+ 'money': money,
+ 'payment_type': payment_type,
+ 'acquiring_institution': acquiring_institution,
+ 'data': f'{dic_data}',
+ 'more': more
+ }
+ except:
+ logger.error(traceback.format_exc())
+ logger.error(dic_data)
+ return {}
diff --git a/app/ui/tool/__init__.py b/wxManager/parser/util/__init__.py
similarity index 100%
rename from app/ui/tool/__init__.py
rename to wxManager/parser/util/__init__.py
diff --git a/app/util/region_conversion.py b/wxManager/parser/util/common.py
similarity index 89%
rename from app/util/region_conversion.py
rename to wxManager/parser/util/common.py
index afbad63..2a6d489 100644
--- a/app/util/region_conversion.py
+++ b/wxManager/parser/util/common.py
@@ -1,47 +1,69 @@
-# 中国省份拼音到中文的映射字典
-province_mapping = {
- 'Anhui': '安徽',
- 'Beijing': '北京',
- 'Chongqing': '重庆',
- 'Fujian': '福建',
- 'Gansu': '甘肃',
- 'Guangdong': '广东',
- 'Guangxi': '广西',
- 'Guizhou': '贵州',
- 'Hainan': '海南',
- 'Hebei': '河北',
- 'Heilongjiang': '黑龙江',
- 'Henan': '河南',
- 'Hong Kong': '香港',
- 'Hubei': '湖北',
- 'Hunan': '湖南',
- 'Inner Mongolia': '内蒙古',
- 'Jiangsu': '江苏',
- 'Jiangxi': '江西',
- 'Jilin': '吉林',
- 'Liaoning': '辽宁',
- 'Macau': '澳门',
- 'Ningxia': '宁夏',
- 'Qinghai': '青海',
- 'Shaanxi': '陕西',
- 'Shandong': '山东',
- 'Shanghai': '上海',
- 'Shanxi': '山西',
- 'Sichuan': '四川',
- 'Taiwan': '台湾',
- 'Tianjin': '天津',
- 'Tibet': '西藏',
- 'Xinjiang': '新疆',
- 'Yunnan': '云南',
- 'Zhejiang': '浙江',
- 'Taipei': '台北',
-}
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
-country_mapping = {
- 'CN': '中国大陆',
- 'TW': '中国台湾',
- 'GB': "英国",
-}
+"""
+@Time : 2025/1/8 0:58
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : wxManager-common.py
+@Description :
+"""
+
+import re
+
+
+def remove_privacy_info(text):
+ # 正则表达式模式
+ patterns = {
+ 'phone': r'\b(\+?86[-\s]?)?1[3-9]\d{9}\b', # 手机号
+ 'email': r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b', # 邮箱
+ 'id_card': r'\b\d{15}|\d{18}|\d{17}X\b', # 身份证号
+ 'password': r'\b(?:password|pwd|pass|psw)[\s=:]*\S+\b', # 密码
+ 'account': r'\b(?:account|username|user|acct)[\s=:]*\S+\b' # 账号
+ }
+
+ for key, pattern in patterns.items():
+ text = re.sub(pattern, f'[{key} xxx]', text)
+
+ return text
+
+
+def remove_illegal_characters(text):
+ # 去除 ASCII 控制字符(除了合法的制表符、换行符和回车符)
+ illegal_chars = re.compile(r'[\x00-\x08\x0B\x0C\x0E-\x1F]')
+ return illegal_chars.sub('', text)
+
+
+def conversion_region_to_chinese(region: tuple):
+ area = ''
+ if not region:
+ return area
+ if region[2]:
+ if region[2] in city_mapping:
+ area = city_mapping[region[2]]
+ else:
+ area = region[2]
+ if region[1]:
+ if region[1] in province_mapping:
+ area = f'{province_mapping[region[1]]} {area}'
+ else:
+ area = f'{region[1]} {area}'
+ if region[0]:
+ if region[0] in country_mapping:
+ area = f'{country_mapping[region[0]]} {area}'
+ else:
+ area = f'{region[0]} {area}'
+ return area
+
+
+def conversion_province_to_chinese(province):
+ area = ''
+ if province in province_mapping:
+ area = f'{province_mapping[province]}'
+ return area
+
+
+# 中国省份拼音到中文的映射字典
city_mapping = {
"Beijing": "北京",
"Tianjin": "天津",
@@ -303,7 +325,7 @@ city_mapping = {
"Hanzhoung": "汉中",
"Ankang": "安康",
"Shangluo": "商洛",
- "Yulin": "榆林",
+ # "Yulin": "榆林",
"Lanzhou": "兰州",
"Tianshui": "天水",
"Pingliang": "平凉",
@@ -326,36 +348,49 @@ city_mapping = {
"Pingxiang": "萍乡",
"Jingdezhen": "景德镇",
"Xinyu": "新余",
- "Yichun": "宜春",
- "Fuzhou": "抚州",
+ # "Yichun": "宜春",
+ # "Fuzhou": "抚州",
"Tin Shui": "天水"
}
-
-
-def conversion_province_to_chinese(province):
- area = ''
- if province in province_mapping:
- area = f'{province_mapping[province]}'
- return area
-
-
-def conversion_region_to_chinese(region: tuple):
- area = ''
- if not region:
- return area
- if region[2]:
- if region[2] in city_mapping:
- area = city_mapping[region[2]]
- else:
- area = region[2]
- if region[1]:
- if region[1] in province_mapping:
- area = f'{province_mapping[region[1]]} {area}'
- else:
- area = f'{region[1]} {area}'
- if region[0]:
- if region[0] in country_mapping:
- area = f'{country_mapping[region[0]]} {area}'
- else:
- area = f'{region[0]} {area}'
- return area
+country_mapping = {
+ 'CN': '中国大陆',
+ 'TW': '中国台湾',
+ 'GB': "英国",
+}
+province_mapping = {
+ 'Anhui': '安徽',
+ 'Beijing': '北京',
+ 'Chongqing': '重庆',
+ 'Fujian': '福建',
+ 'Gansu': '甘肃',
+ 'Guangdong': '广东',
+ 'Guangxi': '广西',
+ 'Guizhou': '贵州',
+ 'Hainan': '海南',
+ 'Hebei': '河北',
+ 'Heilongjiang': '黑龙江',
+ 'Henan': '河南',
+ 'Hong Kong': '香港',
+ 'Hubei': '湖北',
+ 'Hunan': '湖南',
+ 'Inner Mongolia': '内蒙古',
+ 'Jiangsu': '江苏',
+ 'Jiangxi': '江西',
+ 'Jilin': '吉林',
+ 'Liaoning': '辽宁',
+ 'Macau': '澳门',
+ 'Ningxia': '宁夏',
+ 'Qinghai': '青海',
+ 'Shaanxi': '陕西',
+ 'Shandong': '山东',
+ 'Shanghai': '上海',
+ 'Shanxi': '山西',
+ 'Sichuan': '四川',
+ 'Taiwan': '台湾',
+ 'Tianjin': '天津',
+ 'Tibet': '西藏',
+ 'Xinjiang': '新疆',
+ 'Yunnan': '云南',
+ 'Zhejiang': '浙江',
+ 'Taipei': '台北',
+}
diff --git a/app/analysis/__init__.py b/wxManager/parser/util/protocbuf/__init__.py
similarity index 100%
rename from app/analysis/__init__.py
rename to wxManager/parser/util/protocbuf/__init__.py
diff --git a/wxManager/parser/util/protocbuf/contact.proto b/wxManager/parser/util/protocbuf/contact.proto
new file mode 100644
index 0000000..19a4956
--- /dev/null
+++ b/wxManager/parser/util/protocbuf/contact.proto
@@ -0,0 +1,89 @@
+syntax = "proto3";
+
+package example;
+
+// 顶级消息定义
+message ContactInfo {
+ // varint 类型字段,根据数值范围选用 uint32 或 uint64
+ uint32 gender = 2; // 性别:1 男 2:女 0:未知
+ uint32 field3 = 3;
+ string signature = 4; // 自助者天助!!!
+ string country = 5; // CN
+ string province = 6; // Shaanxi
+ string city = 7; // Xi'an
+ uint32 field8 = 8;
+ string field9 = 9;
+ uint32 field10 = 10; // 4294967295
+ uint32 field11 = 11;
+ uint32 field12 = 12;
+
+ // 修改后的嵌套消息,对应 JSON 中 field 14 的数据结构
+ MessageField14 phone_info = 14;
+
+ string field15 = 15;
+ uint32 field16 = 16;
+ uint32 field17 = 17;
+ uint32 field18 = 18;
+ uint32 field19 = 19;
+ string field20 = 20;
+ string field21 = 21;
+ uint32 field22 = 22;
+ uint32 field23 = 23;
+ uint32 field24 = 24;
+ string field25 = 25;
+ string field26 = 26;
+
+ // 嵌套消息,朋友圈背景
+ MessageField27 moments_info = 27;
+
+ string field28 = 28;
+ string field29 = 29;
+ string label_list = 30;
+ string field31 = 31;
+ string field32 = 32;
+
+ // 嵌套消息,对应 JSON 中 field 33 的 length_delimited 数据
+ MessageField33 field33 = 33;
+
+ string field34 = 34;
+ string field35 = 35;
+ MessageField36 field36 = 36;
+ uint32 field37 = 37;
+ uint32 field38 = 38; // 4294967295
+}
+
+// 定义 field14 对应的嵌套消息
+// 修改后的嵌套消息,用于 field 14
+message MessageField14 {
+ uint32 field1 = 1; // varint 类型字段,存储数字
+ repeated MessageField14_Result2 field2 = 2; // 这是一个 length_delimited 类型的字段,包含多个结果
+}
+
+
+message MessageField14_Result2 {
+ string phone_numer = 1; // string 类型字段,存储电话号码
+}
+
+// 定义 field27 对应的嵌套消息
+
+message MessageField27 {
+ uint32 field1 = 1;
+ string background_url = 2; // 图片 URL
+ uint64 field3 = 3; // 14588734692813845087(大数,用 uint64)
+ uint32 field4 = 4; // 6785
+ uint32 field5 = 5; // 4320
+}
+
+// 定义 field33 对应的嵌套消息
+
+message MessageField33 {
+ string field1 = 1;
+}
+
+message MessageField36 {
+ MessageField36_Result results = 1;
+}
+
+message MessageField36_Result {
+ string field1 = 1;
+}
\ No newline at end of file
diff --git a/wxManager/parser/util/protocbuf/contact_pb2.py b/wxManager/parser/util/protocbuf/contact_pb2.py
new file mode 100644
index 0000000..6d38dac
--- /dev/null
+++ b/wxManager/parser/util/protocbuf/contact_pb2.py
@@ -0,0 +1,37 @@
+# -*- coding: utf-8 -*-
+# Generated by the protocol buffer compiler. DO NOT EDIT!
+# source: contact.proto
+"""Generated protocol buffer code."""
+from google.protobuf.internal import builder as _builder
+from google.protobuf import descriptor as _descriptor
+from google.protobuf import descriptor_pool as _descriptor_pool
+from google.protobuf import symbol_database as _symbol_database
+# @@protoc_insertion_point(imports)
+
+_sym_db = _symbol_database.Default()
+
+
+
+
+DESCRIPTOR = _descriptor_pool.Default().AddSerializedFile(b'\n\rcontact.proto\x12\x07\x65xample\"\xd7\x05\n\x0b\x43ontactInfo\x12\x0e\n\x06gender\x18\x02 \x01(\r\x12\x0e\n\x06\x66ield3\x18\x03 \x01(\r\x12\x11\n\tsignature\x18\x04 \x01(\t\x12\x0f\n\x07\x63ountry\x18\x05 \x01(\t\x12\x10\n\x08province\x18\x06 \x01(\t\x12\x0c\n\x04\x63ity\x18\x07 \x01(\t\x12\x0e\n\x06\x66ield8\x18\x08 \x01(\r\x12\x0e\n\x06\x66ield9\x18\t \x01(\t\x12\x0f\n\x07\x66ield10\x18\n \x01(\r\x12\x0f\n\x07\x66ield11\x18\x0b \x01(\r\x12\x0f\n\x07\x66ield12\x18\x0c \x01(\r\x12+\n\nphone_info\x18\x0e \x01(\x0b\x32\x17.example.MessageField14\x12\x0f\n\x07\x66ield15\x18\x0f \x01(\t\x12\x0f\n\x07\x66ield16\x18\x10 \x01(\r\x12\x0f\n\x07\x66ield17\x18\x11 \x01(\r\x12\x0f\n\x07\x66ield18\x18\x12 \x01(\r\x12\x0f\n\x07\x66ield19\x18\x13 \x01(\r\x12\x0f\n\x07\x66ield20\x18\x14 \x01(\t\x12\x0f\n\x07\x66ield21\x18\x15 \x01(\t\x12\x0f\n\x07\x66ield22\x18\x16 \x01(\r\x12\x0f\n\x07\x66ield23\x18\x17 \x01(\r\x12\x0f\n\x07\x66ield24\x18\x18 \x01(\r\x12\x0f\n\x07\x66ield25\x18\x19 \x01(\t\x12\x0f\n\x07\x66ield26\x18\x1a \x01(\t\x12(\n\x07\x66ield27\x18\x1b \x01(\x0b\x32\x17.example.MessageField27\x12\x0f\n\x07\x66ield28\x18\x1c \x01(\t\x12\x0f\n\x07\x66ield29\x18\x1d \x01(\t\x12\x12\n\nlabel_list\x18\x1e \x01(\t\x12\x0f\n\x07\x66ield31\x18\x1f \x01(\t\x12\x0f\n\x07\x66ield32\x18 \x01(\t\x12(\n\x07\x66ield33\x18! \x01(\x0b\x32\x17.example.MessageField33\x12\x0f\n\x07\x66ield34\x18\" \x01(\t\x12\x0f\n\x07\x66ield35\x18# \x01(\t\x12(\n\x07\x66ield36\x18$ \x01(\x0b\x32\x17.example.MessageField36\x12\x0f\n\x07\x66ield37\x18% \x01(\r\x12\x0f\n\x07\x66ield38\x18& \x01(\r\"Q\n\x0eMessageField14\x12\x0e\n\x06\x66ield1\x18\x01 \x01(\r\x12/\n\x06\x66ield2\x18\x02 \x03(\x0b\x32\x1f.example.MessageField14_Result2\"-\n\x16MessageField14_Result2\x12\x13\n\x0bphone_numer\x18\x01 \x01(\t\"h\n\x0eMessageField27\x12\x0e\n\x06\x66ield1\x18\x01 \x01(\r\x12\x16\n\x0e\x62\x61\x63kground_url\x18\x02 \x01(\t\x12\x0e\n\x06\x66ield3\x18\x03 \x01(\x04\x12\x0e\n\x06\x66ield4\x18\x04 \x01(\r\x12\x0e\n\x06\x66ield5\x18\x05 \x01(\r\" \n\x0eMessageField33\x12\x0e\n\x06\x66ield1\x18\x01 \x01(\t\"A\n\x0eMessageField36\x12/\n\x07results\x18\x01 \x01(\x0b\x32\x1e.example.MessageField36_Result\"\'\n\x15MessageField36_Result\x12\x0e\n\x06\x66ield1\x18\x01 \x01(\tb\x06proto3')
+
+_builder.BuildMessageAndEnumDescriptors(DESCRIPTOR, globals())
+_builder.BuildTopDescriptorsAndMessages(DESCRIPTOR, 'contact_pb2', globals())
+if _descriptor._USE_C_DESCRIPTORS == False:
+
+ DESCRIPTOR._options = None
+ _CONTACTINFO._serialized_start=27
+ _CONTACTINFO._serialized_end=754
+ _MESSAGEFIELD14._serialized_start=756
+ _MESSAGEFIELD14._serialized_end=837
+ _MESSAGEFIELD14_RESULT2._serialized_start=839
+ _MESSAGEFIELD14_RESULT2._serialized_end=884
+ _MESSAGEFIELD27._serialized_start=886
+ _MESSAGEFIELD27._serialized_end=990
+ _MESSAGEFIELD33._serialized_start=992
+ _MESSAGEFIELD33._serialized_end=1024
+ _MESSAGEFIELD36._serialized_start=1026
+ _MESSAGEFIELD36._serialized_end=1091
+ _MESSAGEFIELD36_RESULT._serialized_start=1093
+ _MESSAGEFIELD36_RESULT._serialized_end=1132
+# @@protoc_insertion_point(module_scope)
diff --git a/wxManager/parser/util/protocbuf/emoji_desc.proto b/wxManager/parser/util/protocbuf/emoji_desc.proto
new file mode 100644
index 0000000..21e7462
--- /dev/null
+++ b/wxManager/parser/util/protocbuf/emoji_desc.proto
@@ -0,0 +1,12 @@
+syntax = "proto3";
+
+package example;
+
+message EmojiDescData {
+ repeated EmojiDescItem descItem = 1;
+}
+
+message EmojiDescItem {
+ string language = 1;
+ string desc = 2;
+}
\ No newline at end of file
diff --git a/wxManager/parser/util/protocbuf/emoji_desc_pb2.py b/wxManager/parser/util/protocbuf/emoji_desc_pb2.py
new file mode 100644
index 0000000..b4a1c9c
--- /dev/null
+++ b/wxManager/parser/util/protocbuf/emoji_desc_pb2.py
@@ -0,0 +1,27 @@
+# -*- coding: utf-8 -*-
+# Generated by the protocol buffer compiler. DO NOT EDIT!
+# source: emoji_desc.proto
+"""Generated protocol buffer code."""
+from google.protobuf.internal import builder as _builder
+from google.protobuf import descriptor as _descriptor
+from google.protobuf import descriptor_pool as _descriptor_pool
+from google.protobuf import symbol_database as _symbol_database
+# @@protoc_insertion_point(imports)
+
+_sym_db = _symbol_database.Default()
+
+
+
+
+DESCRIPTOR = _descriptor_pool.Default().AddSerializedFile(b'\n\x10\x65moji_desc.proto\x12\x07\x65xample\"9\n\rEmojiDescData\x12(\n\x08\x64\x65scItem\x18\x01 \x03(\x0b\x32\x16.example.EmojiDescItem\"/\n\rEmojiDescItem\x12\x10\n\x08language\x18\x01 \x01(\t\x12\x0c\n\x04\x64\x65sc\x18\x02 \x01(\tb\x06proto3')
+
+_builder.BuildMessageAndEnumDescriptors(DESCRIPTOR, globals())
+_builder.BuildTopDescriptorsAndMessages(DESCRIPTOR, 'emoji_desc_pb2', globals())
+if _descriptor._USE_C_DESCRIPTORS == False:
+
+ DESCRIPTOR._options = None
+ _EMOJIDESCDATA._serialized_start=29
+ _EMOJIDESCDATA._serialized_end=86
+ _EMOJIDESCITEM._serialized_start=88
+ _EMOJIDESCITEM._serialized_end=135
+# @@protoc_insertion_point(module_scope)
diff --git a/wxManager/parser/util/protocbuf/file_info.proto b/wxManager/parser/util/protocbuf/file_info.proto
new file mode 100644
index 0000000..d783622
--- /dev/null
+++ b/wxManager/parser/util/protocbuf/file_info.proto
@@ -0,0 +1,8 @@
+syntax = "proto3";
+
+package example;
+
+message FileInfoData {
+ string dir3 = 1;
+ uint32 file_size = 2;
+}
diff --git a/wxManager/parser/util/protocbuf/file_info_pb2.py b/wxManager/parser/util/protocbuf/file_info_pb2.py
new file mode 100644
index 0000000..f781f80
--- /dev/null
+++ b/wxManager/parser/util/protocbuf/file_info_pb2.py
@@ -0,0 +1,25 @@
+# -*- coding: utf-8 -*-
+# Generated by the protocol buffer compiler. DO NOT EDIT!
+# source: file_info.proto
+"""Generated protocol buffer code."""
+from google.protobuf.internal import builder as _builder
+from google.protobuf import descriptor as _descriptor
+from google.protobuf import descriptor_pool as _descriptor_pool
+from google.protobuf import symbol_database as _symbol_database
+# @@protoc_insertion_point(imports)
+
+_sym_db = _symbol_database.Default()
+
+
+
+
+DESCRIPTOR = _descriptor_pool.Default().AddSerializedFile(b'\n\x0f\x66ile_info.proto\x12\x07\x65xample\"/\n\x0c\x46ileInfoData\x12\x0c\n\x04\x64ir3\x18\x01 \x01(\t\x12\x11\n\tfile_size\x18\x02 \x01(\rb\x06proto3')
+
+_builder.BuildMessageAndEnumDescriptors(DESCRIPTOR, globals())
+_builder.BuildTopDescriptorsAndMessages(DESCRIPTOR, 'file_info_pb2', globals())
+if _descriptor._USE_C_DESCRIPTORS == False:
+
+ DESCRIPTOR._options = None
+ _FILEINFODATA._serialized_start=28
+ _FILEINFODATA._serialized_end=75
+# @@protoc_insertion_point(module_scope)
diff --git a/app/util/protocbuf/msg.proto b/wxManager/parser/util/protocbuf/msg.proto
similarity index 100%
rename from app/util/protocbuf/msg.proto
rename to wxManager/parser/util/protocbuf/msg.proto
diff --git a/app/util/protocbuf/msg_pb2.py b/wxManager/parser/util/protocbuf/msg_pb2.py
similarity index 100%
rename from app/util/protocbuf/msg_pb2.py
rename to wxManager/parser/util/protocbuf/msg_pb2.py
diff --git a/wxManager/parser/util/protocbuf/packed_info_data.proto b/wxManager/parser/util/protocbuf/packed_info_data.proto
new file mode 100644
index 0000000..78671dd
--- /dev/null
+++ b/wxManager/parser/util/protocbuf/packed_info_data.proto
@@ -0,0 +1,18 @@
+syntax = "proto3";
+
+package example;
+
+// 顶级消息定义
+message PackedInfoData {
+ // varint 类型字段,根据数值范围选用 uint32 或 uint64
+ uint32 field1 = 1;
+ uint32 field2 = 2;
+ MessageField5 info = 5;
+}
+
+// 定义 field14 对应的嵌套消息
+// 修改后的嵌套消息,用于 field 14
+message MessageField5 {
+ uint32 field1 = 1;
+ string audioTxt = 2; // 语音转文字结果
+}
diff --git a/wxManager/parser/util/protocbuf/packed_info_data_img.proto b/wxManager/parser/util/protocbuf/packed_info_data_img.proto
new file mode 100644
index 0000000..337dd20
--- /dev/null
+++ b/wxManager/parser/util/protocbuf/packed_info_data_img.proto
@@ -0,0 +1,7 @@
+syntax = "proto3";
+// 2025年3月微信测试版修改了img命名方式才有了这个东西
+message PackedInfoDataImg {
+ int32 field1 = 1;
+ int32 field2 = 2;
+ string filename = 3;
+}
\ No newline at end of file
diff --git a/wxManager/parser/util/protocbuf/packed_info_data_img_pb2.py b/wxManager/parser/util/protocbuf/packed_info_data_img_pb2.py
new file mode 100644
index 0000000..dbab5ff
--- /dev/null
+++ b/wxManager/parser/util/protocbuf/packed_info_data_img_pb2.py
@@ -0,0 +1,25 @@
+# -*- coding: utf-8 -*-
+# Generated by the protocol buffer compiler. DO NOT EDIT!
+# source: packed_info_data_img.proto
+"""Generated protocol buffer code."""
+from google.protobuf.internal import builder as _builder
+from google.protobuf import descriptor as _descriptor
+from google.protobuf import descriptor_pool as _descriptor_pool
+from google.protobuf import symbol_database as _symbol_database
+# @@protoc_insertion_point(imports)
+
+_sym_db = _symbol_database.Default()
+
+
+
+
+DESCRIPTOR = _descriptor_pool.Default().AddSerializedFile(b'\n\x1apacked_info_data_img.proto\"E\n\x11PackedInfoDataImg\x12\x0e\n\x06\x66ield1\x18\x01 \x01(\x05\x12\x0e\n\x06\x66ield2\x18\x02 \x01(\x05\x12\x10\n\x08\x66ilename\x18\x03 \x01(\tb\x06proto3')
+
+_builder.BuildMessageAndEnumDescriptors(DESCRIPTOR, globals())
+_builder.BuildTopDescriptorsAndMessages(DESCRIPTOR, 'packed_info_data_img_pb2', globals())
+if _descriptor._USE_C_DESCRIPTORS == False:
+
+ DESCRIPTOR._options = None
+ _PACKEDINFODATAIMG._serialized_start=30
+ _PACKEDINFODATAIMG._serialized_end=99
+# @@protoc_insertion_point(module_scope)
diff --git a/wxManager/parser/util/protocbuf/packed_info_data_merged.proto b/wxManager/parser/util/protocbuf/packed_info_data_merged.proto
new file mode 100644
index 0000000..506ec59
--- /dev/null
+++ b/wxManager/parser/util/protocbuf/packed_info_data_merged.proto
@@ -0,0 +1,29 @@
+syntax = "proto3";
+
+message PackedInfoData {
+ int32 field1 = 1;
+ int32 field2 = 2;
+ NestedMessage field7 = 7;
+ AnotherNestedMessage info = 9;
+}
+
+message NestedMessage {
+ SubMessage1 field1 = 1;
+ SubMessage2 field2 = 2;
+ string field3 = 3;
+}
+
+message SubMessage1 {
+ int32 field1 = 1;
+ string field2 = 2;
+}
+
+message SubMessage2 {
+ string field1 = 1;
+ string field2 = 2;
+ string field3 = 3;
+}
+
+message AnotherNestedMessage {
+ string dir = 1;
+}
diff --git a/wxManager/parser/util/protocbuf/packed_info_data_merged_pb2.py b/wxManager/parser/util/protocbuf/packed_info_data_merged_pb2.py
new file mode 100644
index 0000000..fa43faa
--- /dev/null
+++ b/wxManager/parser/util/protocbuf/packed_info_data_merged_pb2.py
@@ -0,0 +1,33 @@
+# -*- coding: utf-8 -*-
+# Generated by the protocol buffer compiler. DO NOT EDIT!
+# source: packed_info_data_merged.proto
+"""Generated protocol buffer code."""
+from google.protobuf.internal import builder as _builder
+from google.protobuf import descriptor as _descriptor
+from google.protobuf import descriptor_pool as _descriptor_pool
+from google.protobuf import symbol_database as _symbol_database
+# @@protoc_insertion_point(imports)
+
+_sym_db = _symbol_database.Default()
+
+
+
+
+DESCRIPTOR = _descriptor_pool.Default().AddSerializedFile(b'\n\x1dpacked_info_data_merged.proto\"u\n\x0ePackedInfoData\x12\x0e\n\x06\x66ield1\x18\x01 \x01(\x05\x12\x0e\n\x06\x66ield2\x18\x02 \x01(\x05\x12\x1e\n\x06\x66ield7\x18\x07 \x01(\x0b\x32\x0e.NestedMessage\x12#\n\x04info\x18\t \x01(\x0b\x32\x15.AnotherNestedMessage\"[\n\rNestedMessage\x12\x1c\n\x06\x66ield1\x18\x01 \x01(\x0b\x32\x0c.SubMessage1\x12\x1c\n\x06\x66ield2\x18\x02 \x01(\x0b\x32\x0c.SubMessage2\x12\x0e\n\x06\x66ield3\x18\x03 \x01(\t\"-\n\x0bSubMessage1\x12\x0e\n\x06\x66ield1\x18\x01 \x01(\x05\x12\x0e\n\x06\x66ield2\x18\x02 \x01(\t\"=\n\x0bSubMessage2\x12\x0e\n\x06\x66ield1\x18\x01 \x01(\t\x12\x0e\n\x06\x66ield2\x18\x02 \x01(\t\x12\x0e\n\x06\x66ield3\x18\x03 \x01(\t\"#\n\x14\x41notherNestedMessage\x12\x0b\n\x03\x64ir\x18\x01 \x01(\tb\x06proto3')
+
+_builder.BuildMessageAndEnumDescriptors(DESCRIPTOR, globals())
+_builder.BuildTopDescriptorsAndMessages(DESCRIPTOR, 'packed_info_data_merged_pb2', globals())
+if _descriptor._USE_C_DESCRIPTORS == False:
+
+ DESCRIPTOR._options = None
+ _PACKEDINFODATA._serialized_start=33
+ _PACKEDINFODATA._serialized_end=150
+ _NESTEDMESSAGE._serialized_start=152
+ _NESTEDMESSAGE._serialized_end=243
+ _SUBMESSAGE1._serialized_start=245
+ _SUBMESSAGE1._serialized_end=290
+ _SUBMESSAGE2._serialized_start=292
+ _SUBMESSAGE2._serialized_end=353
+ _ANOTHERNESTEDMESSAGE._serialized_start=355
+ _ANOTHERNESTEDMESSAGE._serialized_end=390
+# @@protoc_insertion_point(module_scope)
diff --git a/wxManager/parser/util/protocbuf/packed_info_data_pb2.py b/wxManager/parser/util/protocbuf/packed_info_data_pb2.py
new file mode 100644
index 0000000..6874670
--- /dev/null
+++ b/wxManager/parser/util/protocbuf/packed_info_data_pb2.py
@@ -0,0 +1,27 @@
+# -*- coding: utf-8 -*-
+# Generated by the protocol buffer compiler. DO NOT EDIT!
+# source: packed_info_data.proto
+"""Generated protocol buffer code."""
+from google.protobuf.internal import builder as _builder
+from google.protobuf import descriptor as _descriptor
+from google.protobuf import descriptor_pool as _descriptor_pool
+from google.protobuf import symbol_database as _symbol_database
+# @@protoc_insertion_point(imports)
+
+_sym_db = _symbol_database.Default()
+
+
+
+
+DESCRIPTOR = _descriptor_pool.Default().AddSerializedFile(b'\n\x16packed_info_data.proto\x12\x07\x65xample\"V\n\x0ePackedInfoData\x12\x0e\n\x06\x66ield1\x18\x01 \x01(\r\x12\x0e\n\x06\x66ield2\x18\x02 \x01(\r\x12$\n\x04info\x18\x05 \x01(\x0b\x32\x16.example.MessageField5\"1\n\rMessageField5\x12\x0e\n\x06\x66ield1\x18\x01 \x01(\r\x12\x10\n\x08\x61udioTxt\x18\x02 \x01(\tb\x06proto3')
+
+_builder.BuildMessageAndEnumDescriptors(DESCRIPTOR, globals())
+_builder.BuildTopDescriptorsAndMessages(DESCRIPTOR, 'packed_info_data_pb2', globals())
+if _descriptor._USE_C_DESCRIPTORS == False:
+
+ DESCRIPTOR._options = None
+ _PACKEDINFODATA._serialized_start=35
+ _PACKEDINFODATA._serialized_end=121
+ _MESSAGEFIELD5._serialized_start=123
+ _MESSAGEFIELD5._serialized_end=172
+# @@protoc_insertion_point(module_scope)
diff --git a/app/util/protocbuf/readme.md b/wxManager/parser/util/protocbuf/readme.md
similarity index 100%
rename from app/util/protocbuf/readme.md
rename to wxManager/parser/util/protocbuf/readme.md
diff --git a/app/util/protocbuf/roomdata.proto b/wxManager/parser/util/protocbuf/roomdata.proto
similarity index 100%
rename from app/util/protocbuf/roomdata.proto
rename to wxManager/parser/util/protocbuf/roomdata.proto
diff --git a/app/util/protocbuf/roomdata_pb2.py b/wxManager/parser/util/protocbuf/roomdata_pb2.py
similarity index 100%
rename from app/util/protocbuf/roomdata_pb2.py
rename to wxManager/parser/util/protocbuf/roomdata_pb2.py
diff --git a/wxManager/parser/wechat_v3.py b/wxManager/parser/wechat_v3.py
new file mode 100644
index 0000000..b233ca0
--- /dev/null
+++ b/wxManager/parser/wechat_v3.py
@@ -0,0 +1,898 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2024/12/11 1:26
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-wechat_v4.py
+@Description :
+"""
+import hashlib
+import os
+from abc import ABC, abstractmethod
+import lz4.block
+import xmltodict
+
+from wxManager.model.message import BusinessCardMessage, VoipMessage, MergedMessage, WeChatVideoMessage, \
+ PositionMessage, TransferMessage, RedEnvelopeMessage, FavNoteMessage, PatMessage
+from wxManager.parser.link_parser import parser_link, parser_applet, parser_business, parser_voip, \
+ parser_merged_messages, parser_wechat_video, parser_position, parser_reply, parser_transfer, parser_red_envelop, \
+ parser_file, parser_favorite_note, parser_pat, parser_music
+from wxManager.parser.util.protocbuf.msg_pb2 import MessageBytesExtra
+from wxManager.parser.wechat_v4 import LimitedDict
+from .audio_parser import parser_audio
+from .emoji_parser import parser_emoji
+from .file_parser import parse_video
+from wxManager.log import logger
+from wxManager.model import Message, TextMessage, ImageMessage, VideoMessage, EmojiMessage, LinkMessage, FileMessage, \
+ AudioMessage, QuoteMessage, MessageType
+from wxManager.model import Me
+from ..db_main import DataBaseInterface
+
+'''
+local_id,server_id,local_type,sort_seq,sender_username,
+create_time,StrTime,status,upload_status,server_seq,origin_source,
+source,message_content,compress_content"
+'''
+
+
+def decompress(data):
+ """
+ 解压缩Msg:CompressContent内容
+ :param data:
+ :return:
+ """
+ if data is None:
+ return ""
+ if isinstance(data, str):
+ return data
+ if not isinstance(data, bytes):
+ return ""
+ try:
+ dst = lz4.block.decompress(data, uncompressed_size=len(data) << 10)
+ decoded_string = dst.decode().replace("\x00", "") # Remove any null characters
+ except:
+ print(
+ "Decompression failed: potentially corrupt input or insufficient buffer size."
+ )
+ return ""
+ return decoded_string
+
+
+# 定义抽象工厂基类
+class MessageFactory(ABC):
+ @abstractmethod
+ def create(self, data, username: str, database_manager: DataBaseInterface):
+ """
+ 创建一个Message实例
+ @param data: 从数据库获得的元组数据
+ @param username: 聊天对象的wxid
+ @param database_manager: 数据库管理接口
+ @return:
+ """
+ pass
+
+
+# 单例基类
+class Singleton:
+ _instances = {}
+ contacts = {}
+ messages = LimitedDict(100)
+
+ def __new__(cls, *args, **kwargs):
+ if cls not in cls._instances:
+ cls._instances[cls] = super().__new__(cls, *args, **kwargs)
+ return cls._instances[cls]
+
+ @classmethod
+ def set_shared_data(cls, data):
+ cls._shared_data = data
+
+ @classmethod
+ def get_shared_data(cls):
+ return cls._shared_data
+
+ @classmethod
+ def set_contacts(cls, contacts):
+ cls.contacts.update(contacts)
+
+ @classmethod
+ def get_contact(cls, wxid, database_manager: DataBaseInterface):
+ if wxid in cls.contacts:
+ return cls.contacts[wxid]
+ else:
+ contact = database_manager.get_contact_by_username(wxid)
+ cls.contacts[wxid] = contact
+ return contact
+
+ def common_attribute(self, message, username, manager):
+ """
+
+ :param message:
+ :param username:
+ :param manager:
+ :return: wxid,is_sender,xml_content
+ """
+ is_sender = message[4]
+ wxid = ''
+ if is_sender:
+ wxid = Me().wxid
+ else:
+ if username.endswith('@chatroom'):
+ msgbytes = MessageBytesExtra()
+ msgbytes.ParseFromString(message[10])
+ for tmp in msgbytes.message2:
+ if tmp.field1 != 1:
+ continue
+ wxid = tmp.field2
+ # todo 解析还是有问题,会出现这种带:的东西
+ if ':' in wxid: # wxid_ewi8gfgpp0eu22:25319:1
+ wxid = wxid.split(':')[0]
+ else:
+ wxid = username
+ if wxid not in self.contacts:
+ self.contacts[wxid] = manager.get_contact_by_username(wxid)
+ if username.endswith('@openim'):
+ xml_content = message[7]
+ else:
+ xml_content = decompress(message[11])
+ xml_content = xml_content.replace('�', '').replace(' ', ' ') if xml_content else ''
+ return is_sender, wxid, xml_content if xml_content else message[7]
+
+ @classmethod
+ def get_message_by_server_id(cls, server_id, username, manager):
+ if server_id and isinstance(server_id, str):
+ server_id = int(server_id)
+ if server_id in cls.messages:
+ return cls.messages.get(server_id)
+ else:
+ msg = manager.get_message_by_server_id(username, server_id) # todo 非常耗时
+ if msg:
+ cls.add_message(msg)
+ else:
+ msg = TextMessage(
+ local_id=0,
+ server_id=0,
+ sort_seq=0,
+ timestamp=0,
+ str_time='',
+ type=MessageType.Text,
+ talker_id=username,
+ is_sender=False,
+ sender_id=username,
+ display_name=username,
+ avatar_src='',
+ status=0,
+ xml_content='',
+ content='无效的消息'
+ )
+ return msg
+
+ @classmethod
+ def reset_messages(cls):
+ cls.messages = {}
+
+ @classmethod
+ def add_message(cls, message: Message):
+ if message:
+ cls.messages[message.server_id] = message
+
+
+class UnknownMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, xml_content = self.common_attribute(message, username, manager)
+ return Message(
+ local_id=message[0],
+ server_id=message[9],
+ sort_seq=message[5],
+ timestamp=message[5],
+ str_time=message[8],
+ type=MessageType.Unknown,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=wxid,
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[6],
+ xml_content=xml_content
+ )
+
+
+class TextMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, xml_content = self.common_attribute(message, username, manager)
+ sub_type = parser_sub_type(message[7]) if username.endswith('@openim') else message[3]
+ if sub_type == 1:
+ content = xmltodict.parse(xml_content).get('msg', {}).get('appmsg', {}).get('title', '')
+ else:
+ content = message[7]
+ msg = TextMessage(
+ local_id=message[0],
+ server_id=message[9],
+ sort_seq=message[5],
+ timestamp=message[5],
+ str_time=message[8],
+ type=MessageType.Text,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=wxid,
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[6],
+ xml_content='',
+ content=content
+ )
+ self.add_message(msg)
+ return msg
+
+
+class ImageMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, xml_content = self.common_attribute(message, username, manager)
+ str_content = message[7]
+ BytesExtra = message[10]
+ msg = ImageMessage(
+ local_id=message[0],
+ server_id=message[9],
+ sort_seq=message[5],
+ timestamp=message[5],
+ str_time=message[8],
+ type=MessageType.Image,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=wxid,
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[6],
+ xml_content=str_content,
+ md5='',
+ path='',
+ thumb_path='',
+ file_size=0,
+ file_name='',
+ file_type='png'
+ )
+
+ path = manager.get_image(content=str_content, bytesExtra=BytesExtra, up_dir='',
+ thumb=False, talker_username=username)
+ msg.path = path
+ msg.thumb_path = manager.get_image(content=str_content, bytesExtra=BytesExtra, up_dir='',
+ thumb=True, talker_username=username)
+ self.add_message(msg)
+ return msg
+
+
+class AudioMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, xml_content = self.common_attribute(message, username, manager)
+ msg = AudioMessage(
+ local_id=message[0],
+ server_id=message[9],
+ sort_seq=message[5],
+ timestamp=message[5],
+ str_time=message[8],
+ type=MessageType.Audio,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=wxid,
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[6],
+ xml_content=xml_content,
+ md5='',
+ path='',
+ file_size=0,
+ file_name='',
+ file_type='mp3',
+ audio_text='',
+ duration=0
+ )
+ msg.set_file_name()
+ audio_dic = parser_audio(msg.xml_content)
+ msg.duration = audio_dic.get('audio_length', 0)
+ msg.audio_text = audio_dic.get('audio_text', '')
+ self.add_message(msg)
+ return msg
+
+
+class VideoMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, xml_content = self.common_attribute(message, username, manager)
+ msg = VideoMessage(
+ local_id=message[0],
+ server_id=message[9],
+ sort_seq=message[5],
+ timestamp=message[5],
+ str_time=message[8],
+ type=MessageType.Video,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=wxid,
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[6],
+ xml_content=xml_content,
+ md5='',
+ path='',
+ file_size=0,
+ file_name='',
+ file_type='mp4',
+ thumb_path='',
+ duration=0,
+ raw_md5=''
+ )
+ str_content = message[7]
+ BytesExtra = message[10]
+ video_dic = parse_video(xml_content)
+ msg.duration = video_dic.get('length', 0)
+ msg.file_size = video_dic.get('size', 0)
+ msg.md5 = video_dic.get('md5', '')
+ msg.raw_md5 = video_dic.get('rawmd5', '')
+ msg.path = manager.get_video(str_content, BytesExtra, md5=msg.md5, thumb=False)
+ msg.thumb_path = manager.get_video(str_content, BytesExtra, md5=msg.md5, thumb=True)
+ if not msg.path:
+ msg.path = manager.get_video(str_content, BytesExtra, thumb=False)
+ msg.thumb_path = manager.get_video(str_content, BytesExtra, thumb=True)
+ # logger.error(f'{msg.path} {msg.thumb_path}')
+ self.add_message(msg)
+ return msg
+
+
+class EmojiMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, xml_content = self.common_attribute(message, username, manager)
+ msg = EmojiMessage(
+ local_id=message[0],
+ server_id=message[9],
+ sort_seq=message[5],
+ timestamp=message[5],
+ str_time=message[8],
+ type=MessageType.Emoji,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=wxid,
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[6],
+ xml_content=message[7],
+ md5='',
+ path='',
+ thumb_path='',
+ file_size=0,
+ file_name='',
+ file_type='png',
+ url='',
+ thumb_url='',
+ description=''
+ )
+ emoji_info = parser_emoji(xml_content)
+ if not emoji_info.get('url'):
+ msg.url = manager.get_emoji_url(emoji_info.get('md5'))
+ else:
+ msg.url = emoji_info.get('url')
+ msg.md5 = emoji_info.get('md5', '')
+ msg.description = emoji_info.get('desc')
+ self.add_message(msg)
+ return msg
+
+
+def parser_sub_type(xml_content):
+ """
+ 解析sub_type(用于企业微信特殊消息)
+ @param xml_content:
+ @return:
+ """
+ sub_type = 0
+ try:
+ data = xmltodict.parse(xml_content)
+ if data and data.get('msg'):
+ data = data['msg']['appmsg']
+ sub_type = int(data['type'])
+ except:
+ sub_type = 0
+ return sub_type
+
+
+# 工厂注册表
+class LinkMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ msg = LinkMessage(
+ local_id=message[0],
+ server_id=message[9],
+ sort_seq=message[5],
+ timestamp=message[5],
+ str_time=message[8],
+ type=MessageType.LinkMessage,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=wxid,
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ href='',
+ title='',
+ description='',
+ cover_path='',
+ cover_url='',
+ app_name='',
+ app_icon='',
+ app_id=''
+ )
+ type_ = message[2]
+ sub_type = parser_sub_type(message[7]) if username.endswith('@openim') else message[3]
+ if (type_, sub_type) in {(49, 5)}:
+ info = parser_link(message_content)
+ msg.title = info.get('title', '')
+ msg.href = info.get('url', '')
+ msg.app_name = info.get('appname', '')
+ msg.app_id = info.get('appid', '')
+ msg.description = info.get('desc', '')
+ msg.cover_url = info.get('cover_url')
+ if not msg.app_name:
+ msg.app_name = info.get('sourcedisplayname')
+ if not msg.app_name:
+ source_username = info.get('sourceusername')
+ if source_username:
+ contact = manager.get_contact_by_username(source_username)
+ msg.app_name = contact.nickname
+ msg.app_icon = contact.small_head_img_url
+ elif (type_, sub_type) in {(49, 33), (49, 36)}:
+ # 小程序
+ msg.type = MessageType.Applet
+ info = parser_applet(message_content)
+ msg.title = info.get('title', '')
+ msg.href = info.get('url', '')
+ msg.app_name = info.get('appname', '')
+ msg.app_id = info.get('appid', '')
+ msg.description = info.get('desc', '')
+ msg.app_icon = info.get('app_icon', '')
+ msg.cover_url = info.get('cover_url', '')
+ elif (type_, sub_type) in {(49, 3), (49, 76)}:
+ # 音乐分享
+ info = parser_music(message_content)
+ msg.type = MessageType.Music
+ msg.title = info.get('title', '')
+ msg.href = info.get('url', '')
+ msg.app_name = info.get('appname', '')
+ # msg.app_id = info.get('appid', '')
+ msg.description = info.get('artist', '')
+ # msg.app_icon = info.get('songalbumurl', '')
+ msg.cover_url = info.get('songalbumurl', '')
+ # logger.error(xmltodict.parse(message_content))
+ self.add_message(msg)
+ return msg
+
+
+class BusinessCardMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ info = parser_business(message_content)
+ msg = BusinessCardMessage(
+ local_id=message[0],
+ server_id=message[9],
+ sort_seq=message[5],
+ timestamp=message[5],
+ str_time=message[8],
+ type=MessageType.BusinessCard,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=wxid,
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ username=info.get('username', ''),
+ nickname=info.get('nickname', ''),
+ alias=info.get('alias', ''),
+ small_head_url=info.get('smallheadimgurl', ''),
+ big_head_url=info.get('bigheadimgurl', ''),
+ sex=info.get('sex', 0),
+ sign=info.get('sign', ''),
+ province=info.get('province', ''),
+ city=info.get('city', ''),
+ is_open_im=message[2] == MessageType.OpenIMBCard,
+ open_im_desc=info.get('openimdescicon', ''),
+ open_im_desc_icon=info.get('openimdesc', '')
+ )
+ self.add_message(msg)
+ return msg
+
+
+class VoipMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ info = parser_voip(message_content)
+ msg = VoipMessage(
+ local_id=message[0],
+ server_id=message[9],
+ sort_seq=message[5],
+ timestamp=message[5],
+ str_time=message[8],
+ type=MessageType.Voip,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=wxid,
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ invite_type=info.get('invite_type', 0),
+ display_content=info.get('display_content', ''),
+ duration=info.get('duration', 0)
+ )
+ self.add_message(msg)
+ return msg
+
+
+class MergedMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ info = parser_merged_messages(message_content, '', username, message[5])
+ msg = MergedMessage(
+ local_id=message[0],
+ server_id=message[9],
+ sort_seq=message[5],
+ timestamp=message[5],
+ str_time=message[8],
+ type=MessageType.MergedMessages,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=wxid,
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ title=info.get('title', ''),
+ description=info.get('desc', ''),
+ messages=info.get('messages', []),
+ level=0
+ )
+ dir0 = ''
+ month = msg.str_time[:7] # 2025-03
+
+ def parser_merged(merged_messages, level):
+ for index, inner_msg in enumerate(merged_messages):
+ if inner_msg.type == MessageType.Image:
+ if dir0:
+ img_suffix = f'FileStorage/MsgAttach/{hashlib.md5(username.encode("utf-8")).hexdigest()}/Thumb/{month}/{inner_msg.md5}_2.dat'
+ origin_img_path = os.path.join(Me().wx_dir,
+ img_suffix)
+ else:
+ path = manager.get_image(content='', md5=inner_msg.md5, bytesExtra=b'', up_dir='',
+ thumb=False, talker_username=username)
+ inner_msg.path = path
+ inner_msg.thumb_path = manager.get_image(content='', md5=inner_msg.md5, bytesExtra=b'',
+ up_dir='',
+ thumb=True, talker_username=username)
+ if not os.path.exists(os.path.join(Me().wx_dir, inner_msg.path)) or inner_msg.path == '.':
+ inner_msg.path = f'FileStorage/MsgAttach/{hashlib.md5(username.encode("utf-8")).hexdigest()}/Thumb/{month}/{inner_msg.md5}_{2}.dat'
+ print(inner_msg.path)
+ elif inner_msg.type == MessageType.Video:
+ if dir0:
+ inner_msg.path = os.path.join('msg', 'attach',
+ hashlib.md5(username.encode("utf-8")).hexdigest(),
+ month,
+ 'Rec', dir0, 'V', f"{level}{'_' if level else ''}{index}.mp4")
+ else:
+ inner_msg.path = manager.get_video('', '', md5=inner_msg.md5, thumb=False)
+ inner_msg.thumb_path = manager.get_video('', '', md5=inner_msg.md5, thumb=True)
+ elif inner_msg.type == MessageType.File:
+ if dir0:
+ inner_msg.path = os.path.join('msg', 'attach',
+ hashlib.md5(username.encode("utf-8")).hexdigest(),
+ month,
+ 'Rec', dir0, 'F', f"{level}{'_' if level else ''}{index}",
+ inner_msg.file_name)
+ else:
+ inner_msg.path = manager.get_file(inner_msg.md5)
+ elif inner_msg.type == MessageType.MergedMessages:
+ parser_merged(inner_msg.messages, f'{index}')
+
+ parser_merged(msg.messages, '')
+ self.add_message(msg)
+ return msg
+
+
+class WeChatVideoMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ msg = WeChatVideoMessage(
+ local_id=message[0],
+ server_id=message[9],
+ sort_seq=message[5],
+ timestamp=message[5],
+ str_time=message[8],
+ type=MessageType.WeChatVideo,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=wxid,
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ url='',
+ publisher_nickname='',
+ publisher_avatar='',
+ description='',
+ media_count=1,
+ cover_url='',
+ thumb_url='',
+ cover_path='',
+ width=0,
+ height=0,
+ duration=0
+ )
+ info = parser_wechat_video(message_content)
+ msg.publisher_nickname = info.get('sourcedisplayname', '')
+ msg.publisher_avatar = info.get('weappiconurl', '')
+ msg.description = info.get('title', '')
+ msg.cover_url = info.get('cover', '')
+ self.add_message(msg)
+ return msg
+
+
+class PositionMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ msg = PositionMessage(
+ local_id=message[0],
+ server_id=message[9],
+ sort_seq=message[5],
+ timestamp=message[5],
+ str_time=message[8],
+ type=MessageType.Position,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=wxid,
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ x=0,
+ y=0,
+ poiname='',
+ label='',
+ scale=0
+ )
+ info = parser_position(message_content)
+ msg.x = eval(info.get('x', ''))
+ msg.y = eval(info.get('y', ''))
+ msg.poiname = info.get('poiname', '')
+ msg.label = info.get('label', '')
+ msg.scale = eval(info.get('scale', ''))
+ self.add_message(msg)
+ return msg
+
+
+class QuoteMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ info = parser_reply(message_content)
+ # quote_message = manager.get_message_by_server_id(username, info.get('svrid', '')) # todo 非常耗时
+ quote_message = self.get_message_by_server_id(info.get('svrid', ''), username, manager)
+ msg = QuoteMessage(
+ local_id=message[0],
+ server_id=message[9],
+ sort_seq=message[5],
+ timestamp=message[5],
+ str_time=message[8],
+ type=MessageType.Quote,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=wxid,
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ content=info.get('text'),
+ quote_message=quote_message,
+ )
+ self.add_message(msg)
+ return msg
+
+
+class SystemMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ wxid = ''
+ sub_type = parser_sub_type(message[7]) if username.endswith('@openim') else message[3]
+ if sub_type == 17:
+ xml_content = decompress(message[11])
+ content = xmltodict.parse(xml_content).get('msg', {}).get('appmsg', {}).get('title', '')
+ else:
+ content = message[7]
+ msg = TextMessage(
+ local_id=message[0],
+ server_id=message[9],
+ sort_seq=message[5],
+ timestamp=message[5],
+ str_time=message[8],
+ type=MessageType.System,
+ talker_id=username,
+ is_sender=message[4],
+ sender_id=wxid,
+ display_name='',
+ avatar_src='',
+ status=message[7],
+ xml_content=message[7],
+ content=content,
+ )
+ self.add_message(msg)
+ return msg
+
+
+class TransferMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ info = parser_transfer(message_content)
+ msg = TransferMessage(
+ local_id=message[0],
+ server_id=message[9],
+ sort_seq=message[5],
+ timestamp=message[5],
+ str_time=message[8],
+ type=MessageType.Transfer,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=wxid,
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ pay_subtype=info.get('pay_subtype', 0),
+ fee_desc=info.get('fee_desc', ''),
+ receiver_username=info.get('receiver_username', ''),
+ pay_memo=info.get('pay_memo')
+ )
+ self.add_message(msg)
+ return msg
+
+
+class RedEnvelopeMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ info = parser_red_envelop(message_content)
+ msg = RedEnvelopeMessage(
+ local_id=message[0],
+ server_id=message[9],
+ sort_seq=message[5],
+ timestamp=message[5],
+ str_time=message[8],
+ type=MessageType.RedEnvelope,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=wxid,
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ title=info.get('title', ''),
+ icon_url=info.get('icon_url', ''),
+ inner_type=info.get('inner_type', 0)
+ )
+ self.add_message(msg)
+ return msg
+
+
+class FileMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ info = parser_file(message_content)
+ md5 = info.get('md5', '')
+ file_path = manager.get_file(md5)
+ msg = FileMessage(
+ local_id=message[0],
+ server_id=message[9],
+ sort_seq=message[5],
+ timestamp=message[5],
+ str_time=message[8],
+ type=MessageType.File,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=wxid,
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ path=file_path,
+ md5=md5,
+ file_type=info.get('file_type', ''),
+ file_name=info.get('file_name', ''),
+ file_size=info.get('file_size', 0)
+ )
+ self.add_message(msg)
+ return msg
+
+
+class FavNoteMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ info = parser_favorite_note(message_content)
+
+ msg = FavNoteMessage(
+ local_id=message[0],
+ server_id=message[9],
+ sort_seq=message[5],
+ timestamp=message[5],
+ str_time=message[8],
+ type=MessageType.FavNote,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=wxid,
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ title=info.get('title', ''),
+ description=info.get('desc', ''),
+ record_item=info.get('recorditem', '')
+ )
+ self.add_message(msg)
+ return msg
+
+
+class PatMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ # info = parser_pat(message_content)
+
+ msg = PatMessage(
+ local_id=message[0],
+ server_id=message[9],
+ sort_seq=message[5],
+ timestamp=message[5],
+ str_time=message[8],
+ type=MessageType.Pat,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=wxid,
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ title=message_content,
+ from_username='',
+ patted_username='',
+ chat_username=username,
+ template=''
+ )
+ self.add_message(msg)
+ return msg
+
+
+# 工厂注册表
+FACTORY_REGISTRY = {
+ -1: UnknownMessageFactory(),
+ MessageType.Text: TextMessageFactory(),
+ MessageType.Text2: TextMessageFactory(),
+ MessageType.Image: ImageMessageFactory(),
+ MessageType.Audio: AudioMessageFactory(),
+ MessageType.Video: VideoMessageFactory(),
+ MessageType.Emoji: EmojiMessageFactory(),
+ MessageType.File: FileMessageFactory(),
+ MessageType.Position: PositionMessageFactory(),
+ MessageType.System: SystemMessageFactory(),
+ MessageType.LinkMessage: LinkMessageFactory(),
+ MessageType.LinkMessage2: LinkMessageFactory(),
+ MessageType.LinkMessage4: LinkMessageFactory(),
+ MessageType.LinkMessage5: LinkMessageFactory(),
+ MessageType.LinkMessage6: LinkMessageFactory(),
+ MessageType.Music: LinkMessageFactory(),
+ MessageType.Applet: LinkMessageFactory(),
+ MessageType.Applet2: LinkMessageFactory(),
+ MessageType.Voip: VoipMessageFactory(),
+ MessageType.BusinessCard: BusinessCardMessageFactory(),
+ MessageType.OpenIMBCard: BusinessCardMessageFactory(),
+ MessageType.MergedMessages: MergedMessageFactory(),
+ MessageType.WeChatVideo: WeChatVideoMessageFactory(),
+ MessageType.Quote: QuoteMessageFactory(),
+ MessageType.Transfer: TransferMessageFactory(),
+ MessageType.RedEnvelope: RedEnvelopeMessageFactory(),
+ MessageType.FavNote: FavNoteMessageFactory(),
+ MessageType.Pat: PatMessageFactory(),
+}
+
+if __name__ == '__main__':
+ pass
diff --git a/wxManager/parser/wechat_v4.py b/wxManager/parser/wechat_v4.py
new file mode 100644
index 0000000..141bba6
--- /dev/null
+++ b/wxManager/parser/wechat_v4.py
@@ -0,0 +1,947 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+"""
+@Time : 2024/12/11 1:26
+@Author : SiYuan
+@Email : 863909694@qq.com
+@File : MemoTrace-wechat_v4.py
+@Description :
+"""
+import hashlib
+import html
+import os.path
+from collections import OrderedDict
+
+from abc import ABC, abstractmethod
+
+import xmltodict
+import zstandard as zstd
+from google.protobuf.json_format import MessageToDict
+
+from wxManager.model.message import VoipMessage, BusinessCardMessage, MergedMessage, WeChatVideoMessage, \
+ PositionMessage, TransferMessage, RedEnvelopeMessage, FavNoteMessage, PatMessage
+from wxManager.parser.link_parser import parser_link, parser_voip, parser_applet, parser_business, \
+ parser_merged_messages, parser_wechat_video, parser_position, parser_reply, parser_transfer, parser_red_envelop, \
+ parser_file, parser_favorite_note, parser_pat
+from wxManager.parser.util.protocbuf import packed_info_data_pb2, packed_info_data_merged_pb2,packed_info_data_img_pb2
+from .audio_parser import parser_audio
+from .emoji_parser import parser_emoji
+from .file_parser import parse_video
+from wxManager.log import logger
+from wxManager.model import *
+from wxManager.model import Me
+from ..db_main import DataBaseInterface
+
+'''
+local_id,server_id,local_type,sort_seq,sender_username,
+create_time,StrTime,status,upload_status,server_seq,origin_source,
+source,message_content,compress_content"
+'''
+
+
+def decompress(data):
+ dctx = zstd.ZstdDecompressor() # 创建解压对象
+ x = dctx.decompress(data).strip(b'\x00').strip()
+ return x.decode('utf-8').strip()
+
+
+class LimitedDict:
+ # 数据缓存,最多存储k条数据,超出自动删除
+ def __init__(self, k):
+ self.k = k
+ self.messages = OrderedDict()
+
+ def __setitem__(self, key, value):
+ if key in self.messages:
+ # 如果键已存在,先删除再插入
+ del self.messages[key]
+ elif len(self.messages) >= self.k:
+ # 超过限制,删除最早插入的项
+ self.messages.popitem(last=False)
+ self.messages[key] = value
+
+ def __getitem__(self, key):
+ return self.messages[key]
+
+ def __delitem__(self, key):
+ del self.messages[key]
+
+ def __contains__(self, key):
+ return key in self.messages
+
+ def __repr__(self):
+ return repr(self.messages)
+
+ def get(self, key):
+ return self.messages.get(key)
+
+
+# 定义抽象工厂基类
+class MessageFactory(ABC):
+ @abstractmethod
+ def create(self, data, username: str, database_manager: DataBaseInterface):
+ """
+ 创建一个Message实例
+ @param data: 从数据库获得的元组数据
+ @param username: 聊天对象的wxid
+ @param database_manager: 数据库管理接口
+ @return:
+ """
+ pass
+
+
+# 单例基类
+class Singleton:
+ _instances = {}
+ contacts = {}
+ messages = LimitedDict(100)
+
+ def __new__(cls, *args, **kwargs):
+ if cls not in cls._instances:
+ cls._instances[cls] = super().__new__(cls, *args, **kwargs)
+ return cls._instances[cls]
+
+ @classmethod
+ def set_shared_data(cls, data):
+ cls._shared_data = data
+
+ @classmethod
+ def get_shared_data(cls):
+ return cls._shared_data
+
+ @classmethod
+ def set_contacts(cls, contacts):
+ cls.contacts.update(contacts)
+
+ @classmethod
+ def get_contact(cls, wxid, database_manager: DataBaseInterface):
+ if wxid in cls.contacts:
+ return cls.contacts[wxid]
+ else:
+ contact = database_manager.get_contact_by_username(wxid)
+ cls.contacts[wxid] = contact
+ return contact
+
+ @classmethod
+ def get_message_by_server_id(cls, server_id, username, manager):
+ if not server_id:
+ msg = TextMessage(
+ local_id=0,
+ server_id=0,
+ sort_seq=0,
+ timestamp=0,
+ str_time='',
+ type=MessageType.Text,
+ talker_id=username,
+ is_sender=False,
+ sender_id=username,
+ display_name=username,
+ avatar_src='',
+ status=0,
+ xml_content='',
+ content='无效的消息'
+ )
+ return msg
+ if server_id and isinstance(server_id, str):
+ server_id = int(server_id)
+ if server_id in cls.messages:
+ return cls.messages.get(server_id)
+ else:
+ msg = manager.get_message_by_server_id(username, server_id) # todo 非常耗时
+ if msg:
+ cls.add_message(msg)
+ else:
+ msg = TextMessage(
+ local_id=0,
+ server_id=0,
+ sort_seq=0,
+ timestamp=0,
+ str_time='',
+ type=MessageType.Text,
+ talker_id=username,
+ is_sender=False,
+ sender_id=username,
+ display_name=username,
+ avatar_src='',
+ status=0,
+ xml_content='',
+ content='无效的消息'
+ )
+ return msg
+
+ @classmethod
+ def reset_messages(cls):
+ cls.messages = {}
+
+ @classmethod
+ def add_message(cls, message: Message):
+ if message:
+ cls.messages[message.server_id] = message
+
+ def common_attribute(self, message, username, manager):
+ is_sender = message[4] == Me().wxid
+ wxid = message[4]
+ if wxid not in self.contacts:
+ self.contacts[wxid] = manager.get_contact_by_username(wxid)
+ if isinstance(message[12], bytes):
+ message_content = decompress(message[12])
+ message_content = message_content.replace('�', '').replace(' ', ' ')
+ # logger.error(message_content)
+ else:
+ message_content = message[12]
+ if username.endswith('@chatroom') and isinstance(message_content, str) and not is_sender and message[
+ 2] != MessageType.Pat:
+ # 群聊文字消息格式::
+ message_content = ':'.join(message_content.split(':')[1:]).strip()
+
+ return is_sender, wxid, message_content
+
+
+class UnknownMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ msg = Message(
+ local_id=message[0],
+ server_id=message[1],
+ sort_seq=message[3],
+ timestamp=message[5],
+ str_time=message[6],
+ type=message[2],
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=message[4],
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ )
+ self.add_message(msg)
+ return msg
+
+
+class TextMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ msg = TextMessage(
+ local_id=message[0],
+ server_id=message[1],
+ sort_seq=message[3],
+ timestamp=message[5],
+ str_time=message[6],
+ type=MessageType.Text,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=message[4],
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content='',
+ content=message_content
+ )
+ self.add_message(msg)
+ return msg
+
+
+class ImageMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ filename = ''
+ try:
+ # 2025年3月微信测试版修改了img命名方式才有了这个东西
+ packed_info_data_proto = packed_info_data_img_pb2.PackedInfoDataImg()
+ packed_info_data_proto.ParseFromString(message[14])
+ # 转换为 JSON 格式
+ packed_info_data = MessageToDict(packed_info_data_proto)
+ filename = packed_info_data.get('filename', '').strip().strip('"').strip()
+ except:
+ pass
+ msg = ImageMessage(
+ local_id=message[0],
+ server_id=message[1],
+ sort_seq=message[3],
+ timestamp=message[5],
+ str_time=message[6],
+ type=MessageType.Image,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=message[4],
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ md5='',
+ path='',
+ thumb_path='',
+ file_size=0,
+ file_name=filename,
+ file_type='png'
+ )
+ # with open(f'{msg.str_time}{msg.server_id}.bin', 'wb') as f:
+ # f.write(message[14])
+ path = manager.get_image(content=message_content, bytesExtra=msg, up_dir='',
+ thumb=False, talker_username=username)
+ msg.path = path
+ msg.thumb_path = manager.get_image(content=message_content, bytesExtra=msg, up_dir='',
+ thumb=True, talker_username=username)
+ self.add_message(msg)
+ return msg
+
+
+class AudioMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ audio_dic = parser_audio(message_content)
+ audio_length = audio_dic.get('audio_length', 0)
+ audio_text = audio_dic.get('audio_text', '')
+ if not audio_text:
+ packed_info_data_proto = packed_info_data_pb2.PackedInfoData()
+ packed_info_data_proto.ParseFromString(message[14])
+ # 转换为 JSON 格式
+ packed_info_data = MessageToDict(packed_info_data_proto)
+ audio_text = packed_info_data.get('info', {}).get('audioTxt', '')
+ msg = AudioMessage(
+ local_id=message[0],
+ server_id=message[1],
+ sort_seq=message[3],
+ timestamp=message[5],
+ str_time=message[6],
+ type=MessageType.Audio,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=message[4],
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ md5='',
+ path='',
+ file_size=0,
+ file_name='',
+ file_type='mp3',
+ audio_text=audio_text,
+ duration=audio_length
+ )
+ msg.set_file_name()
+ self.add_message(msg)
+ return msg
+
+
+class VideoMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ msg = VideoMessage(
+ local_id=message[0],
+ server_id=message[1],
+ sort_seq=message[3],
+ timestamp=message[5],
+ str_time=message[6],
+ type=MessageType.Video,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=message[4],
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ md5='',
+ path='',
+ file_size=0,
+ file_name='',
+ file_type='mp4',
+ thumb_path='',
+ duration=0,
+ raw_md5=''
+ )
+ video_dic = parse_video(message_content)
+ msg.duration = video_dic.get('length', 0)
+ msg.file_size = video_dic.get('size', 0)
+ msg.md5 = video_dic.get('md5', '')
+ msg.raw_md5 = video_dic.get('rawmd5', '')
+ msg.path = manager.hardlink_db.get_video(msg.raw_md5, False)
+ msg.thumb_path = manager.hardlink_db.get_video(msg.raw_md5, True)
+ if not msg.path:
+ msg.path = manager.hardlink_db.get_video(msg.md5, False)
+ msg.thumb_path = manager.hardlink_db.get_video(msg.md5, True)
+ # logger.error(f'{msg.path} {msg.thumb_path}')
+ self.add_message(msg)
+ return msg
+
+
+class EmojiMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ msg = EmojiMessage(
+ local_id=message[0],
+ server_id=message[1],
+ sort_seq=message[3],
+ timestamp=message[5],
+ str_time=message[6],
+ type=MessageType.Emoji,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=message[4],
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ md5='',
+ path='',
+ thumb_path='',
+ file_size=0,
+ file_name='',
+ file_type='png',
+ url='',
+ thumb_url='',
+ description=''
+ )
+ emoji_info = parser_emoji(message_content)
+ # logger.error(emoji_info)
+ # logger.error(message_content)
+ if not emoji_info.get('url'):
+ msg.url = manager.get_emoji_url(emoji_info.get('md5'))
+ else:
+ msg.url = emoji_info.get('url')
+ msg.md5 = emoji_info.get('md5', '')
+ # msg.url = get_emoji_url(message_content)
+ # msg.thumb_url = ''
+ msg.description = emoji_info.get('desc')
+ # msg.description = get_emoji_desc(message_content)
+ self.add_message(msg)
+ return msg
+
+
+class LinkMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ msg = LinkMessage(
+ local_id=message[0],
+ server_id=message[1],
+ sort_seq=message[3],
+ timestamp=message[5],
+ str_time=message[6],
+ type=MessageType.LinkMessage,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=message[4],
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ href='',
+ title='',
+ description='',
+ cover_path='',
+ cover_url='',
+ app_name='',
+ app_icon='',
+ app_id=''
+ )
+ if message[2] in {MessageType.LinkMessage, MessageType.LinkMessage2, MessageType.Music,
+ MessageType.LinkMessage4, MessageType.LinkMessage5, MessageType.LinkMessage6}:
+ info = parser_link(message_content)
+ msg.title = info.get('title', '')
+ msg.href = info.get('url', '')
+ msg.app_name = info.get('appname', '')
+ msg.app_id = info.get('appid', '')
+ msg.description = info.get('desc', '')
+ msg.cover_url = info.get('cover_url', '')
+ if message[2] in {MessageType.Music}:
+ msg.type = MessageType.Music
+ if not msg.app_name:
+ source_username = info.get('sourceusername')
+ if source_username:
+ contact = manager.get_contact_by_username(source_username)
+ msg.app_name = contact.nickname
+ msg.app_icon = contact.small_head_img_url
+
+ elif message[2] == MessageType.Applet or message[2] == MessageType.Applet2:
+ info = parser_applet(message_content)
+ msg.type = MessageType.Applet
+ msg.title = info.get('title', '')
+ msg.href = info.get('url', '')
+ msg.app_name = info.get('appname', '')
+ msg.app_id = info.get('appid', '')
+ msg.description = info.get('desc', '')
+ msg.app_icon = info.get('app_icon', '')
+ msg.cover_url = info.get('cover_url', '')
+ self.add_message(msg)
+ return msg
+
+
+class BusinessCardMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ info = parser_business(message_content)
+ msg = BusinessCardMessage(
+ local_id=message[0],
+ server_id=message[1],
+ sort_seq=message[3],
+ timestamp=message[5],
+ str_time=message[6],
+ type=MessageType.BusinessCard,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=message[4],
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ username=info.get('username', ''),
+ nickname=info.get('nickname', ''),
+ alias=info.get('alias', ''),
+ small_head_url=info.get('smallheadimgurl', ''),
+ big_head_url=info.get('bigheadimgurl', ''),
+ sex=info.get('sex', 0),
+ sign=info.get('sign', ''),
+ province=info.get('province', ''),
+ city=info.get('city', ''),
+ is_open_im=message[2] == MessageType.OpenIMBCard,
+ open_im_desc=info.get('openimdescicon', ''),
+ open_im_desc_icon=info.get('openimdesc', '')
+ )
+ self.add_message(msg)
+ return msg
+
+
+class VoipMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ info = parser_voip(message_content)
+ msg = VoipMessage(
+ local_id=message[0],
+ server_id=message[1],
+ sort_seq=message[3],
+ timestamp=message[5],
+ str_time=message[6],
+ type=MessageType.Voip,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=message[4],
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ invite_type=info.get('invite_type', 0),
+ display_content=info.get('display_content', ''),
+ duration=info.get('duration', 0)
+ )
+ self.add_message(msg)
+ return msg
+
+
+class MergedMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ """
+ 合并转发的聊天记录
+ - 文件路径:
+ - msg/attach/9e20f478899dc29eb19741386f9343c8/2025-03/Rec/409af365664e0c0d/F/5/xxx.pdf
+ - 图片路径:
+ - msg/attach/9e20f478899dc29eb19741386f9343c8/2025-03/Rec/409af365664e0c0d/Img/5
+ - 视频路径:
+ - msg/attach/9e20f478899dc29eb19741386f9343c8/2025-03/Rec/409af365664e0c0d/V/5.mp4
+ 9e20f478899dc29eb19741386f9343c8是wxid的md5加密,409af365664e0c0d是packed_info_data_proto字段里的dir3
+ 文件夹最后的5代表的该文件是合并转发的聊天记录第5条消息,如果存在嵌套的合并转发的聊天记录,则依次递归的添加上一层的文件名后缀,例如:合并转发的聊天记录有两层
+ 0:文件(文件夹名为0)
+ 1:图片 (文件名为1)
+ 2:合并转发的聊天记录
+ 0:文件(文件夹名为2_0)
+ 1:图片(文件名为2_1)
+ 2:视频(文件名为2_2.mp4)
+ :param message:
+ :param username:
+ :param manager:
+ :return:
+ """
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ info = parser_merged_messages(message_content, '', username, message[5])
+ msg = MergedMessage(
+ local_id=message[0],
+ server_id=message[1],
+ sort_seq=message[3],
+ timestamp=message[5],
+ str_time=message[6],
+ type=MessageType.MergedMessages,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=message[4],
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ title=info.get('title', ''),
+ description=info.get('desc', ''),
+ messages=info.get('messages', []),
+ level=0
+ )
+ packed_info_data_proto = packed_info_data_merged_pb2.PackedInfoData()
+ packed_info_data_proto.ParseFromString(message[14])
+ # 转换为 JSON 格式
+ packed_info_data = MessageToDict(packed_info_data_proto)
+ dir0 = packed_info_data.get('info', {}).get('dir', '')
+ month = msg.str_time[:7] # 2025-03
+ rec_dir = os.path.join(Me().wx_dir, 'msg', 'attach', hashlib.md5(username.encode("utf-8")).hexdigest(), month,
+ 'Rec')
+ if not dir0 and os.path.exists(rec_dir):
+ for file in os.listdir(rec_dir):
+ if file.startswith(f'{msg.local_id}_'):
+ dir0 = file
+
+ def parser_merged(merged_messages, level):
+ for index, inner_msg in enumerate(merged_messages):
+ wxid_md5 = hashlib.md5(username.encode("utf-8")).hexdigest()
+ if inner_msg.type == MessageType.Image:
+ if dir0:
+ inner_msg.path = os.path.join('msg', 'attach',
+ wxid_md5,
+ month,
+ 'Rec', dir0, 'Img', f"{level}{'_' if level else ''}{index}")
+ inner_msg.thumb_path = os.path.join('msg', 'attach',
+ wxid_md5,
+ month,
+ 'Rec', dir0, 'Img',
+ f"{level}{'_' if level else ''}{index}_t")
+ else:
+ path = manager.get_image(content='', md5=inner_msg.md5, bytesExtra=inner_msg, up_dir='',
+ thumb=False, talker_username=username)
+ inner_msg.path = path
+ inner_msg.thumb_path = manager.get_image(content='', md5=inner_msg.md5, bytesExtra=inner_msg,
+ up_dir='',
+ thumb=True, talker_username=username)
+ elif inner_msg.type == MessageType.Video:
+ if dir0:
+ inner_msg.path = os.path.join('msg', 'attach',
+ wxid_md5,
+ month,
+ 'Rec', dir0, 'V', f"{level}{'_' if level else ''}{index}.mp4")
+ inner_msg.thumb_path = os.path.join('msg', 'attach',
+ wxid_md5,
+ month,
+ 'Rec', dir0, 'Img',
+ f"{level}{'_' if level else ''}{index}_t")
+ else:
+ inner_msg.path = manager.get_video('', '', md5=inner_msg.md5, thumb=False)
+ inner_msg.thumb_path = manager.get_video('', '', md5=inner_msg.md5, thumb=True)
+ elif inner_msg.type == MessageType.File:
+ if dir0:
+ inner_msg.path = os.path.join('msg', 'attach',
+ wxid_md5,
+ month,
+ 'Rec', dir0, 'F', f"{level}{'_' if level else ''}{index}", inner_msg.file_name)
+ else:
+ inner_msg.path = manager.get_file(inner_msg.md5)
+ elif inner_msg.type == MessageType.MergedMessages:
+ parser_merged(inner_msg.messages, f'{index}' if not level else f'{level}_{index}')
+
+ parser_merged(msg.messages, '')
+ self.add_message(msg)
+ return msg
+
+
+class WeChatVideoMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ msg = WeChatVideoMessage(
+ local_id=message[0],
+ server_id=message[1],
+ sort_seq=message[3],
+ timestamp=message[5],
+ str_time=message[6],
+ type=MessageType.WeChatVideo,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=message[4],
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ url='',
+ publisher_nickname='',
+ publisher_avatar='',
+ description='',
+ media_count=1,
+ cover_url='',
+ thumb_url='',
+ cover_path='',
+ width=0,
+ height=0,
+ duration=0
+ )
+ info = parser_wechat_video(message_content)
+ msg.publisher_nickname = info.get('sourcedisplayname', '')
+ msg.publisher_avatar = info.get('weappiconurl', '')
+ msg.description = info.get('title', '')
+ msg.cover_url = info.get('cover', '')
+ self.add_message(msg)
+ return msg
+
+
+class PositionMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ msg = PositionMessage(
+ local_id=message[0],
+ server_id=message[1],
+ sort_seq=message[3],
+ timestamp=message[5],
+ str_time=message[6],
+ type=MessageType.Position,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=message[4],
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ x=0,
+ y=0,
+ poiname='',
+ label='',
+ scale=0
+ )
+ info = parser_position(message_content)
+ msg.x = eval(info.get('x', ''))
+ msg.y = eval(info.get('y', ''))
+ msg.poiname = info.get('poiname', '')
+ msg.label = info.get('label', '')
+ msg.scale = eval(info.get('scale', ''))
+ self.add_message(msg)
+ return msg
+
+
+class QuoteMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ info = parser_reply(message_content)
+ # quote_message = manager.get_message_by_server_id(username, info.get('svrid', '')) # todo 非常耗时
+ quote_message = self.get_message_by_server_id(info.get('svrid', ''), username, manager)
+ msg = QuoteMessage(
+ local_id=message[0],
+ server_id=message[1],
+ sort_seq=message[3],
+ timestamp=message[5],
+ str_time=message[6],
+ type=MessageType.Quote,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=message[4],
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ content=info.get('text'),
+ quote_message=quote_message,
+ )
+ self.add_message(msg)
+ return msg
+
+
+class SystemMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender = message[4] == Me().wxid
+ wxid = message[4]
+ if wxid not in self.contacts:
+ self.contacts[wxid] = manager.get_contact_by_username(wxid)
+ if isinstance(message[12], bytes):
+ message_content = decompress(message[12])
+ try:
+ dic = xmltodict.parse(message_content)
+ message_content = dic.get('sysmsg', {}).get('revokemsg', {}).get('content', '')
+ except:
+ pass
+ # logger.error(message_content)
+ else:
+ message_content = message[12]
+
+ msg = TextMessage(
+ local_id=message[0],
+ server_id=message[1],
+ sort_seq=message[3],
+ timestamp=message[5],
+ str_time=message[6],
+ type=MessageType.System,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=message[4],
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ content=message_content,
+ )
+ self.add_message(msg)
+ return msg
+
+
+class TransferMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ info = parser_transfer(message_content)
+ msg = TransferMessage(
+ local_id=message[0],
+ server_id=message[1],
+ sort_seq=message[3],
+ timestamp=message[5],
+ str_time=message[6],
+ type=MessageType.Transfer,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=message[4],
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ pay_subtype=info.get('pay_subtype', 0),
+ fee_desc=info.get('fee_desc', ''),
+ receiver_username=info.get('receiver_username', ''),
+ pay_memo=info.get('pay_memo')
+ )
+ self.add_message(msg)
+ return msg
+
+
+class RedEnvelopeMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ info = parser_red_envelop(message_content)
+ msg = RedEnvelopeMessage(
+ local_id=message[0],
+ server_id=message[1],
+ sort_seq=message[3],
+ timestamp=message[5],
+ str_time=message[6],
+ type=MessageType.RedEnvelope,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=message[4],
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ title=info.get('title', ''),
+ icon_url=info.get('icon_url', ''),
+ inner_type=info.get('inner_type', 0)
+ )
+ self.add_message(msg)
+ return msg
+
+
+class FileMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ info = parser_file(message_content)
+ md5 = info.get('md5', '')
+ file_path = manager.get_file(md5)
+ msg = FileMessage(
+ local_id=message[0],
+ server_id=message[1],
+ sort_seq=message[3],
+ timestamp=message[5],
+ str_time=message[6],
+ type=MessageType.File,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=message[4],
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ path=file_path,
+ md5=md5,
+ file_type=info.get('file_type', ''),
+ file_name=info.get('file_name', ''),
+ file_size=info.get('file_size', 0)
+ )
+ self.add_message(msg)
+ return msg
+
+
+class FavNoteMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ info = parser_favorite_note(message_content)
+
+ msg = FavNoteMessage(
+ local_id=message[0],
+ server_id=message[1],
+ sort_seq=message[3],
+ timestamp=message[5],
+ str_time=message[6],
+ type=MessageType.Pat,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=message[4],
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ title=info.get('title', ''),
+ description=info.get('desc', ''),
+ record_item=info.get('recorditem', '')
+ )
+ self.add_message(msg)
+ return msg
+
+
+class PatMessageFactory(MessageFactory, Singleton):
+ def create(self, message, username, manager):
+ is_sender, wxid, message_content = self.common_attribute(message, username, manager)
+ info = parser_pat(message_content)
+
+ msg = PatMessage(
+ local_id=message[0],
+ server_id=message[1],
+ sort_seq=message[3],
+ timestamp=message[5],
+ str_time=message[6],
+ type=MessageType.Pat,
+ talker_id=username,
+ is_sender=is_sender,
+ sender_id=message[4],
+ display_name=self.contacts[wxid].remark,
+ avatar_src=self.contacts[wxid].small_head_img_url,
+ status=message[7],
+ xml_content=message_content,
+ title=info.get('title', ''),
+ from_username=info.get('from_username', ''),
+ patted_username=info.get('patted_username', ''),
+ chat_username=info.get('chat_username', ''),
+ template=info.get('template', '')
+ )
+ self.add_message(msg)
+ return msg
+
+
+# 工厂注册表
+FACTORY_REGISTRY = {
+ -1: UnknownMessageFactory(),
+ MessageType.Text: TextMessageFactory(),
+ MessageType.Image: ImageMessageFactory(),
+ MessageType.Audio: AudioMessageFactory(),
+ MessageType.Video: VideoMessageFactory(),
+ MessageType.Emoji: EmojiMessageFactory(),
+ MessageType.File: FileMessageFactory(),
+ MessageType.Position: PositionMessageFactory(),
+ MessageType.System: SystemMessageFactory(),
+ MessageType.LinkMessage: LinkMessageFactory(),
+ MessageType.LinkMessage2: LinkMessageFactory(),
+ MessageType.Music: LinkMessageFactory(),
+ MessageType.LinkMessage4: LinkMessageFactory(),
+ MessageType.LinkMessage5: LinkMessageFactory(),
+ MessageType.LinkMessage6: LinkMessageFactory(),
+ MessageType.Applet: LinkMessageFactory(),
+ MessageType.Applet2: LinkMessageFactory(),
+ MessageType.Voip: VoipMessageFactory(),
+ MessageType.BusinessCard: BusinessCardMessageFactory(),
+ MessageType.OpenIMBCard: BusinessCardMessageFactory(),
+ MessageType.MergedMessages: MergedMessageFactory(),
+ MessageType.WeChatVideo: WeChatVideoMessageFactory(),
+ MessageType.Quote: QuoteMessageFactory(),
+ MessageType.Transfer: TransferMessageFactory(),
+ MessageType.RedEnvelope: RedEnvelopeMessageFactory(),
+ MessageType.FavNote: FavNoteMessageFactory(),
+ MessageType.Pat: PatMessageFactory(),
+}
+
+if __name__ == '__main__':
+ pass
 -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-
-
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-